
eXtreme Gradient Boosting vs Random Forest [and the caret package for R]
Decision trees are cute. It is easy to visualize them, easy to explain, easy to apply and even easy to construct. Unfortunately they are quite unstable, particularly for large sets of correlated features.
Fortunately, there are some solutions that may help. One of the most popular solutions is to create a random forest, an ensemble of trees that vote independently, each tree is build on bootstrap sample of observations and subset of features. The other interesting approach is to use a gradient boosting method, to create a collection of trees that optimize the cases that are badly predicted by previous trees. Also one may use bagging instead of boosting so there are much more choices.

For me, the random forest if one of favorite tools when it comes to genetic data (because of OOB, proximity scores and feature importance scores). But recently here and there more and more discussions starts to point the eXtreme Gradient Boosting as a new sheriff in town.
So, let’s compare these two methods.
The literature shows that something is going on. For example Trevor Hastie said that
Boosting > Random Forest > Bagging > Single Tree
You will find more details on slides, and if you prefer videos rather than slides with math, you can watch this example.
I am going to use the caret package (a really really great package) to compare both methods. Random forest have tag “rf” while gradient boosting “xgbTree“.
I am going to use data from The Cancer Genome Atlas Project (next generation sequencing, expression of mRNA, 33 different tumors, 17000+ features, 300+ cases, 33 different classes) and the classifier should predict the type of cancer based on gene expression (Actually I am interested in genetic signatures, but classification is the first step).
Dataset is going to be divided into a testing and training data and the whole procedure will be replicated hundreds times to see what is the variability in model performance.
With the caret package, the training is so easy that I’ve added boosted logistic regression and SVM ,,just in case’’.
library(caret)
mat = lapply(c("LogitBoost", 'xgbTree', 'rf', 'svmRadial'),
function (met) {
train(subClasTrain~., method=met, data=smallSetTrain)
})
So, what are the results?
So, last week I’ve compared these two methods based on Walmart Recruiting Trip from Kaggle. There the goal was to classify a trip to one of 34 types of trips. It was easier to get good results with the use of random forest rather than boosting gradient. But let’s see what is happening with the cancer data.
Below you can see the distribution of accuracies (not a perfect measure, but here it is not a bad one, either) for random splits into the testing/training dataset.
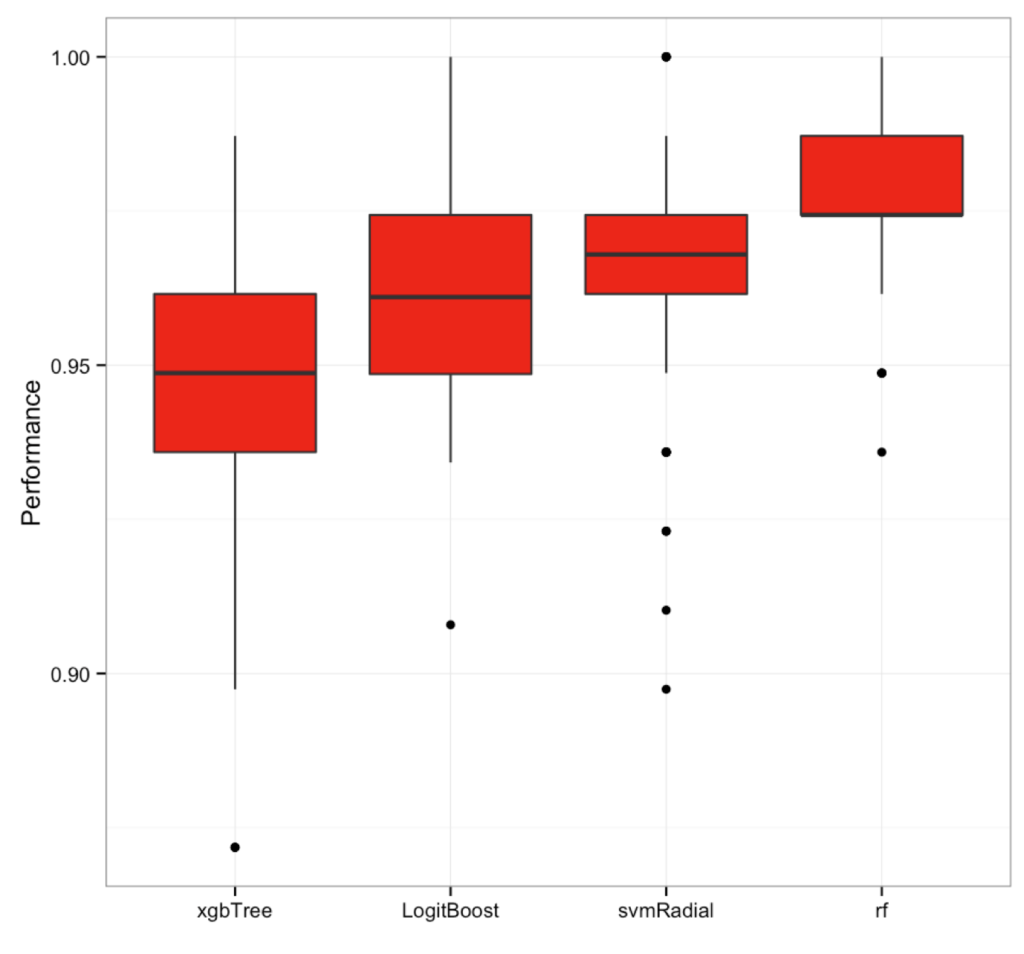
So, it looks like for this dataset the random forest is doing better.
The ‘train’ function has a great argument ‘tuneGrid’, you can specify grid of parameters to be tested. Results may be different for different parameters and of course different datasets.







