“Since the Vancouver police use predictive modelling to fight crime, it is a great city to gather crime prediction experts and confront theory with practice” says Patryk Miziuła, data scientist and lead instructor at deepsense.ai. Miziula is slated to be a panelist at the Joint Statistical Meetings 2018 conference held in Vancouver on July 28 – August 2.
Crime forecasting is usually associated with the film “Minority Report”, based on Philip K. Dick’s short story. It depicts a dystopian vision of people convicted of a crime before actually committing it. In the story, information about potential killers or burglars comes from “precogs”, people with precognition talents who saw the future crimes. “Fortunately, statistical data collected by the police, surveillance systems and municipal services is enough to build a system that can predict the probability of crimes in the area,” says Miziuła. “deepsense.ai prepared such a system for Portland, Oregon and we see a similar solution working efficiently every day in Vancouver”.
Reaching for PreCrime
The Vancouver crime prediction system was introduced in August 2017, following six months of testing in 2016. The pilot ran from April 1 to September 30, when people tend to go on vacation and leave their houses vulnerable to burglaries. During the testing time police recorded a 27% drop in break-ins due to the better distribution of police patrols. According to Vancouver Police Department data, the total crime rate in the city decreased slightly (-1,5%) in 2016-2017, with the burglary rate falling the most (18.4%).
The crimes are predicted by a machine learning model, which analyzes the data collected by the city police department and looks for patterns in crimes. “Machine learning is currently the best tool to handle the massive amounts of data generated on crime. The experiment we did in Portland showed that bad neighborhoods tend to remain bad and crimes usually occur within close proximity. Given that, statistics and machine learning are great tools not only for predicting crime, but also for spotting the problem areas and inspire other public services to act. If vandalism is common in the district, maybe it is not only a matter of crime, but also suggests the need to implement social policy”, Miziuła explained. Further details of the experiment, the results and the technology used in the Portland predictive model are described in a blog post on deepsense.ai’s blog. The experiment will also be described during the upcoming Joint Statistical Meetings 2018 conference held in Vancouver on July 28 – August 2.
Datagazers
The model was built for a US National Institute of Justice competition. The crimes were split into a few categories – burglary, car theft and street crimes including assaults, robberies and shots fired. To predict the place and time a crime would probably occur, the Institute provided historical data with all the crimes registered in Portland between March 2012 and February 2017. deepsense.ai researchers fed the data to its machine learning model, which analyzed the dataset. “During my speech I will discuss the details of our solution and show how statistics is the best fuel for machine learning techniques,” Miziuła says. “We are essentially datagazers, who can see the future by looking at data, rather than the stars”. “Vancouver provides a great environment for a conference with crime forecasting on the agenda. Not only is it a really safe city, but also gave us the opportunity to prove just how efficient these technologies are” concludes Miziuła.
###
About deepsense.ai:
Media contact:
deepsense.ai trademarks at boilerplate
https://deepsense.ai/wp-content/uploads/2019/02/Crime-prediction-in-theory-and-practice-Vancouver-and-beyond.jpg3371140Konrad Budekhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngKonrad Budek2018-07-30 14:03:382019-06-03 13:28:57Crime prediction in theory and practice – Vancouver and beyond
Online learning opens up a raft of benefits, flexibility foremost among them. You don’t have to look for a suitable time for everyone in the team to start training as they can adjust other responsibilities and study on their own schedule, no matter where they are.
Some courses are offered in collaboration with top universities, which provide a wide range of topics to choose from, and further guarantees quality. Moreover, leading companies and industry experts participate in creating the courses, so you can be sure that the educational content is up-to-date and has practical value.
There is also the issue–or non-issue, as the case be–of location. Instead of doing research and looking for a decent vendor, you can just send the team to a data visualization course at the University of Illinois, a Python course at the University of Michigan or a data science course at the Johns Hopkins University, all while your business is headquartered in Australia.
Your employees will surely appreciate the fact that you invest in their development and will be proud of the certification they get after finishing the course. Participants can learn at their own pace, and, if receiving a course certificate isn’t the aim, dedicate more time to one thing while skipping those parts with less value.
Last but not least, MOOCs are usually affordable; you can receive a group discount or wait for a sale season. Some platforms even offer free courses.
So why is the dropout rate so high?
We have already agreed that online education provides a lot of freedom. Of course, there is a set of guidelines and rules students should follow. The question is, do they have enough self-control and determination to stick with it? Online courses, especially ones in demanding and ambitious fields such as machine learning, require great self-discipline. It is essential the student be able to balance their priorities to finish the course. The dropout rate of massive open online courses (MOOCs) is north of 87%!
Although MOOCs have enjoyed wide publicity and numerous institutions (including MIT and Stanford) have invested heavily in developing and promoting such courses, the jury is out on their effectiveness. Staying motivated and keeping up with assignments is not a piece of cake, even if you work in a team.
Teams need support when learning
Online learning is awesome, no doubt. But it comes with a few drawbacks. The absence of direct interaction with an instructor makes online education more of a monolog than a dialogue. When it comes to educating teams, face-to-face communications is paramount, as everyone has to have the same understanding of the problem and the solutions. It therefore should not be replaced by technology. Learning from a live instructor helps students remain focused while enabling instructors to keep students motivated. Online courses don’t provide these opportunities, which may be a, a huge hurdle.
According to a study conducted by Susan Dynarski, professor of education, public policy and economics at the University of Michigan, online courses tend to be more beneficial for proficient students, while keeping the less motivated off track. Without a teacher present to help students with problems, online courses tend to lose their efficiency, while instructor-led sessions can be adjusted to the actual level of the team being trained.
The lack of an individual approach and support exactly when your team need it make the transition from theoretical learning to practical application required for the real-life problems challenging. During an online course, students won’t receive instructor support when the subjects become more and more difficult, leaving some feeling overwhelmed.
According to a study conducted by researchers at the University of Pennsylvania, instructional approach and instructor or peer feedback have a huge impact on the effectiveness of training. Direct and interactive instructions, experiential learning and an individual approach all increase participant engagement. Online courses use peer reviews to enhance learning, and they allow students to learn from each experience by providing feedback. However, this approach is not fully controlled by the instructor and may not always give students constructive feedback. Instructor-led courses can do that, giving the less focused or motivated attendees an opportunity to actually benefit from the course.
Why companies choose online courses vs. instructor-led training
According to Capterra, reducing costs is one reason companies decide to train teams online. But can low price give you the quality you need? The problem with MOOCs begins with the fact that, as their name says, they’re “massive” and “open”. They address many student profiles and the materials are not tailored to their particular needs. Companies sometimes choose courses with little understanding of what the course requires and have unrealistic expectations of it or of their employees abilities. Aside from their attractive price, online courses are easier to arrange than instructor-led training. You don’t have to look for a vendor and arrange a program. Just choose a course covering a relevant topic online.
Nevertheless, managers should look forward and think about the future outcome. Will the team put to good use the knowledge it gains during the online course? An internal instructor-led training program grounded in real projects may cost more than an online course, but that money will soon enough be recouped. Ask yourself whether you can afford ineffective training.
How to effectively develop technical skills in-house
Interaction with others can help you boost your knowledge and increase your interest in a particular topic. Indeed, nothing is more motivating than the people around you. Group training can help your team develop practical skills that are increasingly important in the professional world. Thanks to teamwork and brainstorming, they can tackle more complex problems than they could do individually–for example, develop new approaches to resolve an issue or pool their knowledge.
Some instructor-led courses provide the learning experience tailored to the technical goals and business strategy. Teams learn by building projects using hands-on, code-based training to be able to apply new skills and experience in practice. This practical approach can be followed up by a mentoring program to ground new competencies. A group can potentially understand a given technology more thoroughly when it applies it to specific business use cases. Online course can’t address a company’s particular problems.
So if you have a team which needs new skills which are crucial for your company, are online courses really the answer, or is instructor-led training the way to go? The former seem the riskier of the two, particularly if it is quality results and maximizing budget efficiency you’re after. Finally, the Association for Talent Development has stated that companies offering comprehensive training sessions to their people have 218% higher income per employee. This is a win-win situation for the employee and employer. It takes into account both the individual employee’s development and the company’s strategic goals. The optimal solution combines the best educational practices with real-life business cases. Participants can then turn around their knowledge and use it in their everyday work.
https://deepsense.ai/wp-content/uploads/2019/02/online-course-vs-instructor-led-training-how-to-develop-your-teams-new-skills.jpg3371140Anna Kowalczykhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngAnna Kowalczyk2018-07-27 12:45:092023-10-10 18:48:55Online course vs. instructor-led training – how to develop your team’s new skills?
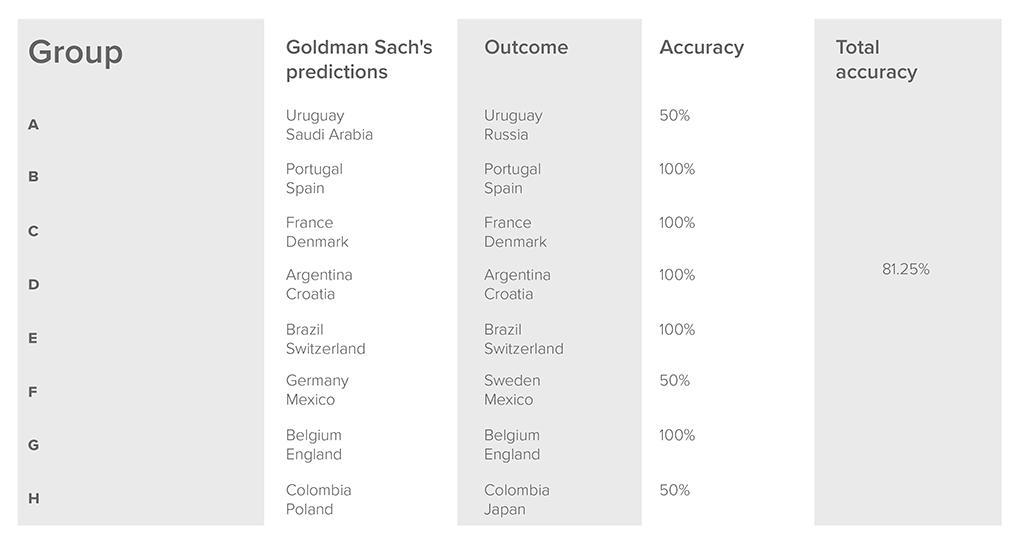
According to predictions done by Soccerbot 3000, the AI-powered prediction machine, Germany should face Brazil in the finals of the World Cup in Russia – or should have, that is. Then the unthinkable happened.
The short explanation for those not interested in the football matches being played in Russia: the German team – the same one Goldman Sachs picked as the probable world champ – failed to get out of its group for the first time in 80 years. And when the German team was vanquished by South Korea and its brilliant Son Heung-Min, predictions were proved wrong. Not much later, the always ballyhooed Brazilian team was knocked just as far out of the tournament, which is to say, all the way. Indeed, Mr. Neymar and peers, following legends Cristiano Ronaldo and Leo Messi, were sent packing before the semi-finals.
The Financial Times pointed out that Soccerbot 3000 used “200,000 models” that generated “1,000,000 possible evolutions of the tournament”. According to its prediction, this year’s Cup should have gone to Brazil by a nose, or a toe as it were. The conclusion that Machine Learning is still ineffective in predictions seems obvious, but it would be severely biased.
It wasn’t only the model that was surprised
In the detailed report on the current World Cup and among generated vast majority have shown Brazil, France, and Germany were forecast to lead, with 18.5%, 11.3%, and 10.7% chances of bringing home the cup, respectively. None of the other teams garnered more than 10%.
The models used historical data about team characteristics, individual players and recent team performance. The model later learned the correlation between these metrics and the teams’ performance based on World Cup data since 2005. Is that a massive amount of data? Indeed it is. But that’s hardly the entire issue.
The model was unable to predict the weather, player health or the atmosphere prevailing in each team. Football, like any other game, consists of many more variables than researchers are able to predict and insert into a model. Of the one million scenarios it produced, the model predicted almost 200,000 scenarios when Germany didn’t reach the round of 16.
That it didn’t happen shocked the world, not only people who trusted the AI to predict the outcome. Even the famous Gary Lineker, who said that “Football is a simple game – twenty-two men chase a ball for 90 minutes and at the end, the Germans always win.” after Germany have beaten England in Italy in 1990 updated his famous quote.
Football is a simple game. Twenty-two men chase a ball for 90 minutes and at the end, the Germans no longer always win. The previous version is confined to history.
The key role machine learning models play is in reducing the randomness of choices based on data processing. The level of accuracy applied to be used in production is highly dependant on the purpose it was designed for.
A fraud detection model that was 80% accurate would never be used in a bank or any other institution. The 20% of the fraud it didn’t catch would be nothing short of a disaster for such an institution.
On the other hand, a model that could return that same 80% processing investment opportunities would earn millions of dollars. Warren Buffet may have missed the investment opportunity in Google and Amazon, but that doesn’t make him an unreliable investor.
Considering its 81,25% accuracy in the group phase, the model would be quite reliable as an advisor, even if it was unable to read opinions, use social media, leaked information or just read the news just before each match to make corrections.
When a company has access to more reliable data or even provides all the data possible, the accuracy rises. This can be seen in visual quality control or recognizing diabetic retinopathy from photos. Predicting the outcome of sporting events is a much different business.
Even the Goldman Sachs analysts behind the model cautioned against seeing it as an oracle. In any case, however many analyses or however much data science gets done, the World Cup will be exciting to watch.
https://deepsense.ai/wp-content/uploads/2019/02/when-predictive-analytics-in-football-fall-short-an-example-header.jpg3371140Konrad Budekhttps://deepsense.ai/wp-content/uploads/2023/10/Logo_black_blue_CLEAN_rgb.pngKonrad Budek2018-07-10 14:44:512021-01-05 16:47:50When predictive analytics in football fall short (an example)
With an estimated market size of 7.35 billion US dollars, artificial intelligence is growing by leaps and bounds. McKinsey predicts that AI techniques (including deep learning and reinforcement learning) have the potential to create between $3.5T and $5.8T in value annually across nine business functions in 19 industries.
Although machine learning is seen as a monolith, this cutting-edge technology is diversified, with various sub-types including machine learning, deep learning, and the state-of-art technology of deep reinforcement learning.
What is reinforcement learning?
Reinforcement learning is the training of machine learning models to make a sequence of decisions. The agent learns to achieve a goal in an uncertain, potentially complex environment. In reinforcement learning, an artificial intelligence faces a game-like situation. The computer employs trial and error to come up with a solution to the problem. To get the machine to do what the programmer wants, the artificial intelligence gets either rewards or penalties for the actions it performs. Its goal is to maximize the total reward.
Although the designer sets the reward policy–that is, the rules of the game–he gives the model no hints or suggestions for how to solve the game. It’s up to the model to figure out how to perform the task to maximize the reward, starting from totally random trials and finishing with sophisticated tactics and superhuman skills. By leveraging the power of search and many trials, reinforcement learning is currently the most effective way to hint machine’s creativity. In contrast to human beings, artificial intelligence can gather experience from thousands of parallel gameplays if a reinforcement learning algorithm is run on a sufficiently powerful computer infrastructure.
Examples of reinforcement learning
Applications of reinforcement learning were in the past limited by weak computer infrastructure. However, as Gerard Tesauro’s backgamon AI superplayer developed in 1990’s shows, progress did happen. That early progress is now rapidly changing with powerful new computational technologies opening the way to completely new inspiring applications.
Training the models that control autonomous cars is an excellent example of a potential application of reinforcement learning. In an ideal situation, the computer should get no instructions on driving the car. The programmer would avoid hard-wiring anything connected with the task and allow the machine to learn from its own errors. In a perfect situation, the only hard-wired element would be the reward function.
For example, in usual circumstances we would require an autonomous vehicle to put safety first, minimize ride time, reduce pollution, offer passengers comfort and obey the rules of law. With an autonomous race car, on the other hand, we would emphasize speed much more than the driver’s comfort. The programmer cannot predict everything that could happen on the road. Instead of building lengthy “if-then” instructions, the programmer prepares the reinforcement learning agent to be capable of learning from the system of rewards and penalties. The agent (another name for reinforcement learning algorithms performing the task) gets rewards for reaching specific goals.
Another example: deepsense.ai took part in the “Learning to run” project, which aimed to train a virtual runner from scratch. The runner is an advanced and precise musculoskeletal model designed by the Stanford Neuromuscular Biomechanics Laboratory. Learning the agent how to run is a first step in building a new generation of prosthetic legs, ones that automatically recognize people’s walking patterns and tweak themselves to make moving easier and more effective. While it is possible and has been done in Stanford’s labs, hard-wiring all the commands and predicting all possible patterns of walking requires a lot of work from highly skilled programmers.
For more real-life applications of reinforcement learning check this article.
The main challenge in reinforcement learning lays in preparing the simulation environment, which is highly dependant on the task to be performed. When the model has to go superhuman in Chess, Go or Atari games, preparing the simulation environment is relatively simple. When it comes to building a model capable of driving an autonomous car, building a realistic simulator is crucial before letting the car ride on the street. The model has to figure out how to brake or avoid a collision in a safe environment, where sacrificing even a thousand cars comes at a minimal cost. Transferring the model out of the training environment and into to the real world is where things get tricky.
Scaling and tweaking neural networks
Scaling and tweaking the neural network controlling the agent is another challenge. There is no way to communicate with the network other than through the system of rewards and penalties.This in particular may lead to catastrophic forgetting, where acquiring new knowledge causes some of the old to be erased from the network (to read up on this issue, see this paper, published during the International Conference on Machine Learning).
Overcoming local optimum and task evasion
Yet another challenge is reaching a local optimum – that is the agent performs the task as it is, but not in the optimal or required way. A “jumper” jumping like a kangaroo instead of doing the thing that was expected of it-walking-is a great example, and is also one that can be found in our recent blog post.
Finally, there are agents that will optimize the prize without performing the task it was designed for. An interesting example can be found in the OpenAI video below, where the agent learned to gain rewards, but not to complete the race.
What distinguishes reinforcement learning from deep learning and machine learning?
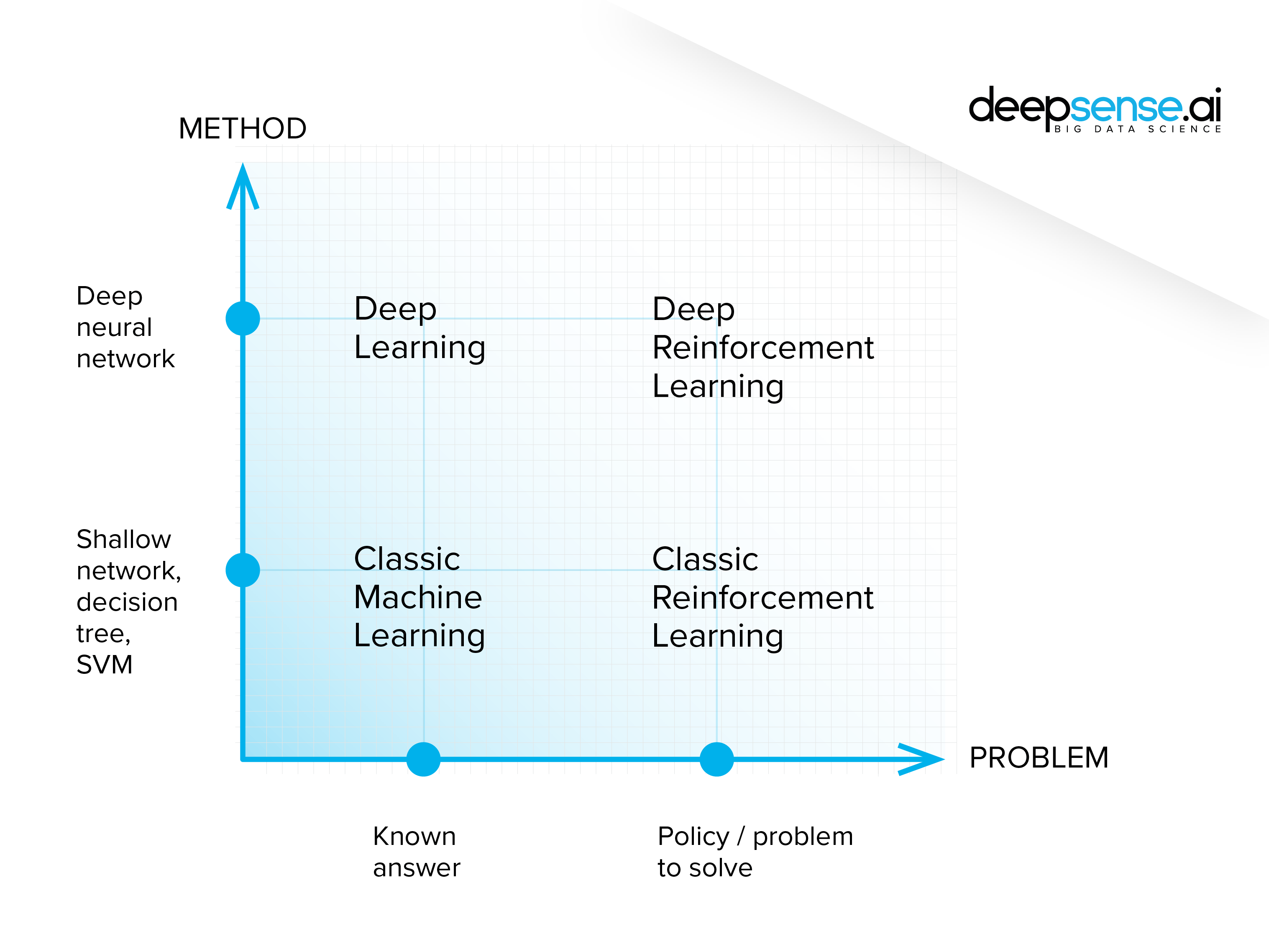
In fact, there should be no clear divide between machine learning, deep learning and reinforcement learning. It is like a parallelogram – rectangle – square relation, where machine learning is the broadest category and the deep reinforcement learning the most narrow one.
In the same way, reinforcement learning is a specialized application of machine and deep learning techniques, designed to solve problems in a particular way.
Although the ideas seem to differ, there is no sharp divide between these subtypes. Moreover, they merge within projects, as the models are designed not to stick to a “pure type” but to perform the task in the most effective way possible. So “what precisely distinguishes machine learning, deep learning and reinforcement learning” is actually a tricky question to answer.
What is machine learning?
Machine learning is a form of AI in which computers are given the ability to progressively improve the performance of a specific task with data, without being directly programmed ( this is Arthur Lee Samuel’s definition). He coined the term “machine learning”, of which there are two types, supervised and unsupervised machine learning
Supervised machine learning happens when a programmer can provide a label for every training input into the machine learning system.
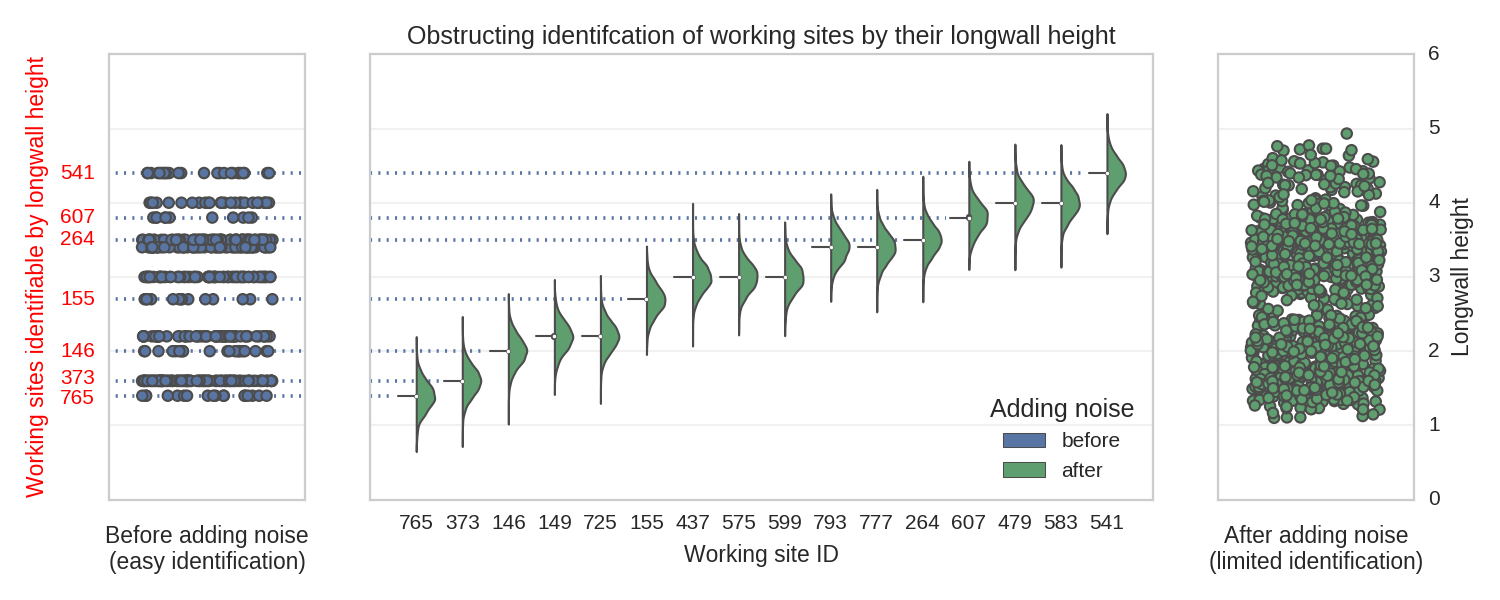
Example – by analyzing the historical data taken from coal mines, deepsense.ai prepared an automated system for predicting dangerous seismic events up to 8 hours before they occur. The records of seismic events were taken from 24 coal mines that had collected data for several months. The model was able to recognize the likelihood of an explosion by analyzing the readings from the previous 24 hours.
Some of the mines can be exactly identified by their main working height values. To obstruct the identification, we added some Gaussian noise
From the AI point of view, a single model was performing a single task on a clarified and normalized dataset. To get more details on the story, read our article about machine learning models predicting dangerous seismic events. Unsupervised learning takes place when the model is provided only with the input data, but no explicit labels. It has to dig through the data and find the hidden structure or relationships within. The designer might not know what the structure is or what the machine learning model is going to find.
An example we employed was for churn prediction. We analyzed customer data and designed an algorithm to group similar customers. However, we didn’t choose the groups ourselves. Later on, we could identify high-risk groups (those with a high churn rate) and our client knew which customers they should approach first.
Another example of unsupervised learning is anomaly detection, where the algorithm has to spot the element that doesn’t fit in with the group. It may be a flawed product, potentially fraudulent transaction or any other event associated with breaking the norm.
What is deep learning?
Deep learning consists of several layers of neural networks, designed to perform more sophisticated tasks. The construction of deep learning models was inspired by the design of the human brain, but simplified. Deep learning models consist of a few neural network layers which are in principle responsible for gradually learning more abstract features about particular data.
Although deep learning solutions are able to provide marvelous results, in terms of scale they are no match for the human brain. Each layer uses the outcome of a previous one as an input and the whole network is trained as a single whole. The core concept of creating an artificial neural network is not new, but only recently has modern hardware provided enough computational power to effectively train such networks by exposing a sufficient number of examples. Extended adoption has brought about frameworks like TensorFlow, Keras and PyTorch, all of which have made building machine learning models much more convenient.
Example: deepsense.ai designed a deep learning-based model for the National Oceanic and Atmospheric Administration (NOAA). It was designed to recognize Right whales from aerial photos taken by researchers. For further information about this endangered species and deepsense.ai’s work with the NOAA, read our blog post. From a technical point of view, recognizing a particular specimen of whales from aerial photos is pure deep learning. The solution consists of a few machine learning models performing separate tasks. The first one was in charge of finding the head of the whale in the photograph while the second normalized the photo by cutting and turning it, which ultimately provided a unified view (a passport photo) of a single whale.
The third model was responsible for recognizing particular whales from photos that had been prepared and processed earlier. A network composed of 5 million neurons located the blowhead bonnet-tip. Over 941,000 neurons looked for the head and more than 3 million neurons were used to classify the particular whale. That’s over 9 million neurons performing the task, which may seem like a lot, but pales in comparison to the more than 100 billion neurons at work in the human brain. We later used a similar deep learning-based solution to diagnose diabetic retinopathy using images of patients’ retinas.
Reinforcement learning in detail
Reinforcement learning, as stated above employs a system of rewards and penalties to compel the computer to solve a problem by itself. Human involvement is limited to changing the environment and tweaking the system of rewards and penalties. As the computer maximizes the reward, it is prone to seeking unexpected ways of doing it. Human involvement is focused on preventing it from exploiting the system and motivating the machine to perform the task in the way expected. Reinforcement learning is useful when there is no “proper way” to perform a task, yet there are rules the model has to follow to perform its duties correctly. Take the road code, for example.
Example: By tweaking and seeking the optimal policy for deep reinforcement learning, we built an agent that in just 20 minutes reached a superhuman level in playing Atari games. Similar algorithms in principal can be used to build AI for an autonomous car or a prosthetic leg. In fact, one of the best ways to evaluate the reinforcement learning approach is to give the model an Atari video game to play, such as Arkanoid or Space Invaders. According to Google Brain’s Marc G. Bellemare, who introduced Atari video games as a reinforcement learning benchmark, “although challenging, these environments remain simple enough that we can hope to achieve measurable progress as we attempt to solve them”.
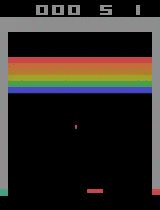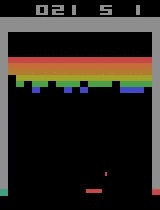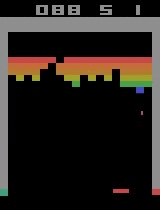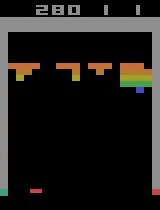
Breakout
Initial performance
After 15 minutes of training
After 30 minutes of training
Assault
Initial performance
After 15 minutes of training
After 30 minutes of training
In particular, if artificial intelligence is going to drive a car, learning to play some Atari classics can be considered a meaningful intermediate milestone. A potential application of reinforcement learning in autonomous vehicles is the following interesting case. A developer is unable to predict all future road situations, so letting the model train itself with a system of penalties and rewards in a varied environment is possibly the most effective way for the AI to broaden the experience it both has and collects.
Reinforcement learning vs deep learning ve machine learning: conclusion
The key distinguishing factor of reinforcement learning is how the agent is trained. Instead of inspecting the data provided, the model interacts with the environment, seeking ways to maximize the reward. In the case of deep reinforcement learning, a neural network is in charge of storing the experiences and thus improves the way the task is performed.
Is reinforcement learning the future of machine learning?
Although reinforcement learning, deep learning, and machine learning are interconnected no one of them in particular is going to replace the others. Yann LeCun, the renowned French scientist and head of research at Facebook, jokes that reinforcement learning is the cherry on a great AI cake with machine learning the cake itself and deep learning the icing. Without the previous iterations, the cherry would top nothing.
In many use cases, using classical machine learning methods will suffice. Purely algorithmic methods not involving machine learning tend to be useful in business data processing or managing databases.
Sometimes machine learning is only supporting a process being performed in another way, for example by seeking a way to optimize speed or efficiency.
When a machine has to deal with unstructured and unsorted data, or with various types of data, neural networks can be very useful.
Summary
Reinforcement learning is no doubt a cutting-edge technology that has the potential to transform our world. However, it need not be used in every case. Nevertheless, reinforcement learning seems to be the most likely way to make a machine creative – as seeking new, innovative ways to perform its tasks is in fact creativity. This is already happening: DeepMind’s now famous AlphaGo played moves that were first considered glitches by human experts, but in fact secured victory against one of the strongest human players, Lee Sedol.
Thus, reinforcement learning has the potential to be a groundbreaking technology and the next step in AI development.