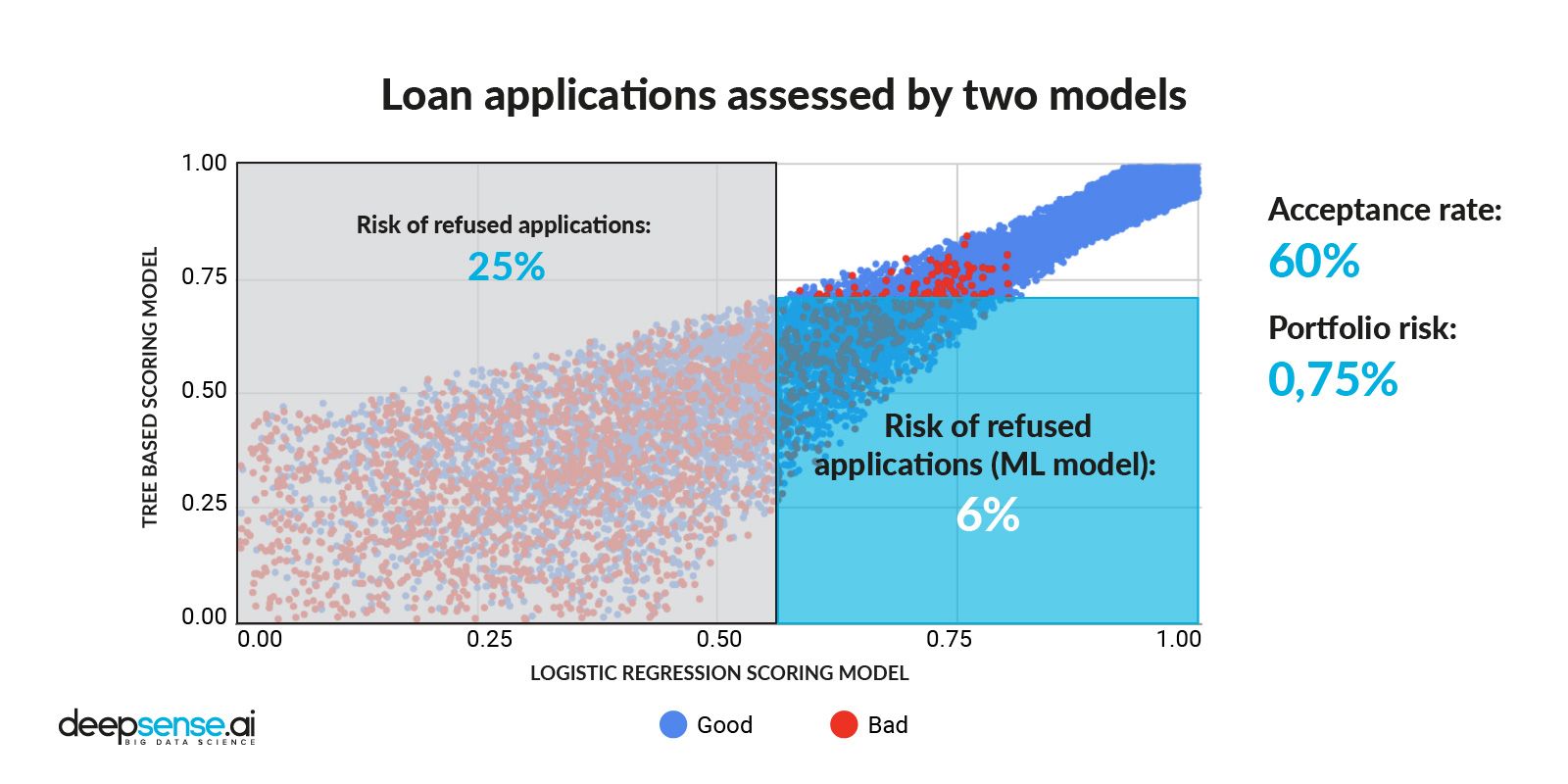
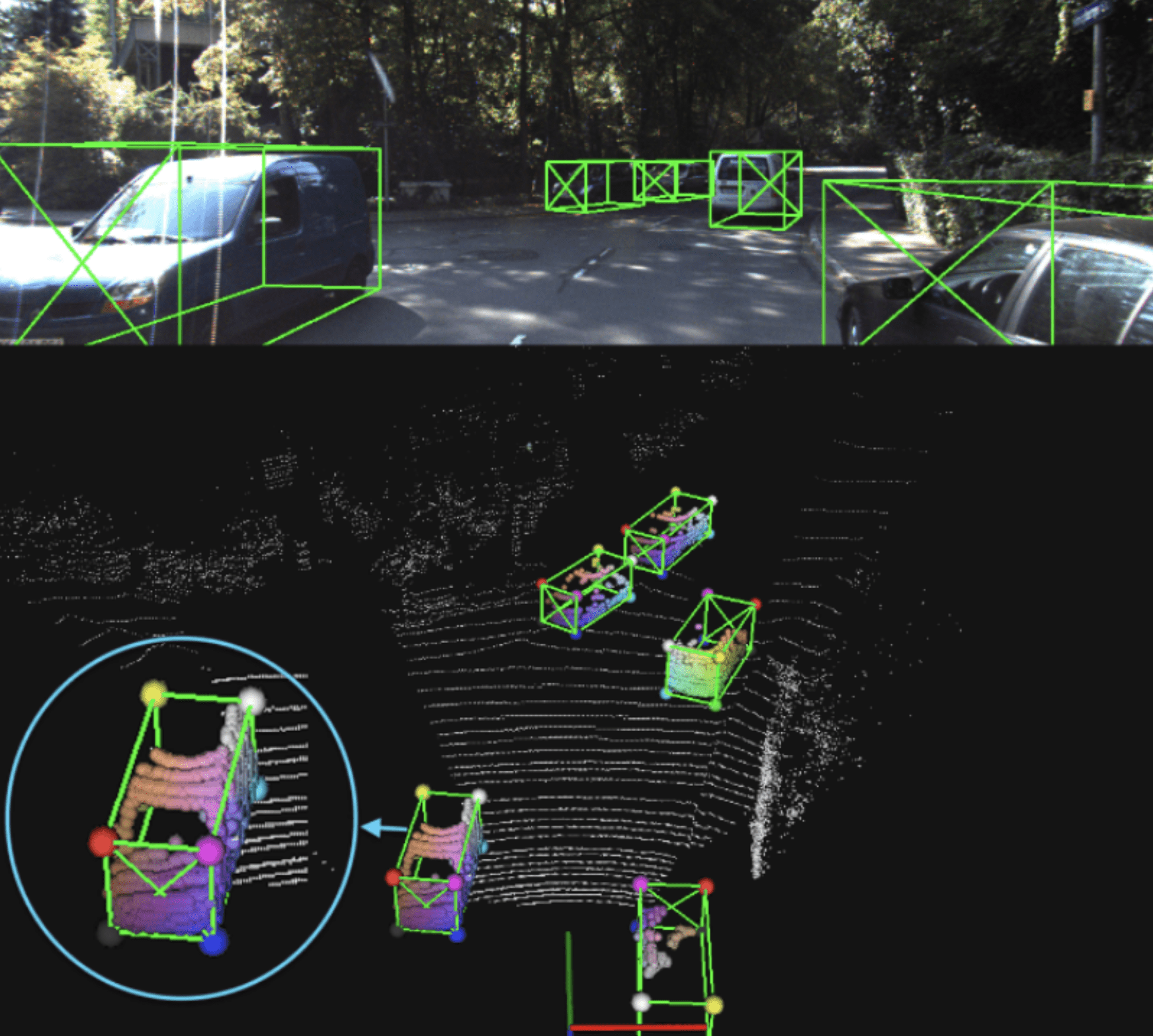
With chatbots powering up customer service on one hand and fake news farms on the other, Natural Language Processing (NLP) is getting attention as one of the most impactful branches of Artificial Intelligence (AI).
When Alan Turing proposed his famous test in 1950, he couldn’t, despite the prescience that accompanies brilliance such as his, predict how easy breaking the test would become. And how far from intelligence the machine that broke the test would be!
Modern Natural Language Processing is being used in multiple industries, in both large-scale projects delivered by tech giants and minor tweaks local companies employ to improve the user experience.
The solutions vary from supporting internal business processes in document management to improving customer service by automated responses generated for the most common questions. According to IDC data cited by Deloitte, companies leveraging the information buried in plain sight in documents and other unstructured data can achieve up to $430 billion in productivity gains by 2020.
The biggest problem with NLP is the significant difference between machines mimicking the understanding of text and actually understanding it. The difference is easily shown with ELIZA software (a famous chatbot from the 1960s), which was based on a set of scripts that paraphrased input text to produce credible-looking responses. The technology was sufficient to produce some text, but far from demonstrating real understanding or delivering business value. Things changed, however, once machine learning models came into use.
What is natural language processing?
As the name implies, natural language processing is the act of a machine processing human language, analyzing the queries in it and responding in a human manner. After several decades of NLP research strongly based on a combination of computer science and linguistic expertise, the “deep learning tsunami” (a term coined by Stanford CS and Linguistics professor Christopher Manning) has recently taken over this field of AI as well, similarly to what happened in computer vision.
Many NLP tasks today are tackled with deep neural networks, which are frequently used among various techniques that enable machines to understand a text’s meaning and its author’s intent.
Modern NLP solutions work on text by “reading” it and making a network of connections between each word. Thus, the model gets more information on the context, the sentiment and exactly what the author sought to communicate.
Tackling the context
Context and intent are critical in analyzing text. Analyzing a picture without context can be tricky – is a fist a symbol of violence, or a bro fist-bump?
The challenge grows even further with NLP, as there are multiple social and cultural norms at work in communication. “The cafe is way too cool for me” can refer to a too-groovy atmosphere or the temperature. Depending on the age of the speaker, a “savage” punk rock concert can be either positive or negative. Before the machine learning era, the flatness of traditional, dictionary-based solutions provided information with significantly less accuracy.
The best way to deal with this challenge is to deliver a word-mapping system based on multidimensional vectors (so-called word embeddings) that provide complex information on the words they represent. Following the idea of distributional semantics (“You shall know a word by the company it keeps”), the neural network learns word representations by looking at the neighboring words. A breakthrough moment for neural NLP came in 2013, when the renowned word2vec model was introduced. However, one of the main problems that word2vec could not solve was homonymy, as the model could not distinguish between different meanings of the same word. A way to significantly improve handling the context in which a word is used in a sentence was found in 2018, when more sophisticated word embedding models like BERT and ELMo were introduced.
Natural Language Processing examples
Recent breakthroughs, especially GPT-2, have significantly improved NLP and delivered some very promising use cases, including the ones elaborated below.
Automated translation
One of the most widely used applications of natural language processing is automated translation between two languages, e.g. with Google Translate. The translator delivers increasingly accurate texts, good enough to serve even in court trials. Google Translate was used when a British court failed to deliver an interpreter for a Mandarin speaker.
Machine translation was one of the first successful applications of deep learning in the field of NLP. The neural approach quickly surpassed statistical machine translation, the technology that preceded it. In a translation task, the system’s input and output are sequences of words. The typical neural network architecture used for translation is therefore called seq2seq, and consists of two recurrent neural networks (encoder and decoder).
The first seq2seq paper was published in 2014, and subsequent research led Google Translate to switch from statistical to neural translation in 2016. Later that year, Google announced a single multi-lingual system that could translate between pairs of languages the system had never seen explicitly, suggesting the existence of some interlingua-like representation of sentences in vector space.

Another important development related to recurrent neural networks is the attention mechanism, which allows a model to learn to focus on particular parts of sequences, greatly improving translation quality. Further improvements come from using Transformer architecture instead of Recurrent Neural Networks.
Chatbots
Automated interaction with customers causes their satisfaction with the overall user experience to rise significantly. And that’s not a thing to overcome, as up to 88% of customers are willing to pay more for better customer experience.
A great example of chatbots improving the customer experience comes from Amtrak, a US railway company that transports 31 million passengers yearly and administrates over 21,000 miles of rails across America. The company decided to employ Julie, a chatbot that supports passengers in searching for a convenient commute. She delivered 800% ROI and reduced the cost of customer service by $1 million yearly while also increasing bookings by 25%.
Speech recognition
As much as a company can use a chatbot to perform some customer service, one can have a personal assistant in the pocket. According to eMarketer data, up to 111.8 million people in the US–over a third of its population–will use a voice assistant at least once a month. The voice assistant market is growing rapidly, with companies such as Google, Apple, Amazon and Samsung developing their assistants not only for mobile devices, but also for TVs and home appliances.
Despite the privacy concerns voice assistants are raising, speech is becoming the new interface for human-machine interaction. The interface can also be used to control industrial machines, especially when employees have their hands occupied – a case common across industries from HoReCa to agriculture and construction – assuming that the noise is reduced enough for machine to register the voice properly.
Thanks to advances in NLP, speech recognition solutions are getting smarter and delivering a better experience for users. As the assistants come to understand speakers’ intentions better and better, they will provide more accurate answers to increasingly complex questions.
An unexpected example of speech recognition comes from deepsense.ai’s project renovating and digitalizating classic movies, where the machine delivers an automated transcription. When combined with a facial recognition tool, the system transcribed and annotated the actor speaking in the film.
Sentiment analysis
Social media provides numerous ways of reaching customers, gathering information on their habits and delivering excellence. It’s also a melting pot of perspectives and news, delivering unprecedented insight on public opinion. This insight can be understood using sentiment analysis tools, which check if the context where a brand is exposed in social media is positive, negative or neutral.
Sentiment analysis can be done without the assistance of AI by building up a glossary of positive and negative words and checking their frequency. If there is swearing or words like “broken” near the brand, sentiment is negative. Yet those systems cannot spot irony or more sophisticated hate. The sentence “I would be happy to see you ill” suggests an aggression and possibly hatred, yet there are no slurs or swearing. By supporting the analysis of words in the glossary by checking the relations between words in each sentence, a machine learning model can deliver a better understanding of the text and provide more information on the message’s subjectivity.
So good can that understanding be, in fact, that deepsense.ai delivered a solution that could spot terrorist propaganda and illicit content in social media in real-time. In the same way, it is possible to deliver a system that spots hate speech and other forms of online harassment. A study from the Pew Research Center shows that up to 41% of adult Americans have experienced some form of online harassment, a number that is likely to increase, mostly due to the rising prevalence of the Internet in people’s daily lives.
Natural language generation
Apart from understanding text, machines are getting better at delivering new texts. According to research published in Foreign Affairs, texts being produced by modern AI software are, for unskilled readers, comparable to those written by journalists. ML models are indeed already writing texts for world media organizations. And while that may seem a fascinating accomplishment, it was the fear of what such advanced abilities might portend that led OpenAI not to make GPT-2 public.
The most known case of automated journalism comes from the Washington Post, where Heliograf covers sport events. Its journalistic debut came in 2016, when the software was responsible for writing up coverage of the Olympic Games in Rio.
In business, natural languae generation is used to produce more polite and humane responses to FAQs. Thus, ironically, automating the conventional communication will make it more personal and humane than current, trigger-based solutions.
Text analytics
Apart from delivering real-time monitoring and sentiment analysis, NLP tools can analyze long and complicated texts, as is already being done at EY, PwC and Deloitte, all of which employ machine learning models to review contracts. The same can be applied to analyze emails or other company-owned unstructured data. According to Gartner estimates, up to 80% of all business data is unstructured and thus nonactionable for companies.
A good example of natural language processing in text analytics is a solution deepsense.ai designed for market research giant Nielsen. The company delivered reports on the ingredients in all of the FMCG products available on the market.
The process of gathering the data was time-consuming and riddled with pitfalls: an employee had to manually read a label, check the ingredients and fill out the tables. The entire process took up to 30 minutes per product. Also, due to inconsistencies in naming, the task was riddled with inconsistencies, as the companies delivered the product ingredients in local languages, English and, especially on the beauty and skin care markets, Latin.
deepsense.ai delivered a comprehensive system that processed an image of the product label taken with a smartphone. The solution spotted the ingredients, scanned the text and sorted the ingredients into tables, effectively reducing the work time from 30 minutes to less than two minutes, including the time needed to gather and validate the data.
Another use case of text analytics is the automated question response function generated by Google, which aims not only to provide search results for particular queries, but a complete answer to the user’s needs, including a link to the referred website, and a description of the matter.
Summary
Natural language processing provides numerous opportunities for companies from multiple industries and segments. Apart from relatively intuitive ways to leverage NLP, such as processing the documents and chatbots, there are multiple other applications, including real time social media analytics and supporting journalism or research work.
NLP models can be used to further augment existing solutions–from supporting the reinforcement learning models behind autonomous cars by providing better sign recognition to augmenting demand forecasting tools with extensions to analyze headlines and deliver more event-based predictions.
Because natural language is the best way to transfer information between humans and machines, the applications NLP makes possible will only increase and will soon be augmenting business processes around the globe.