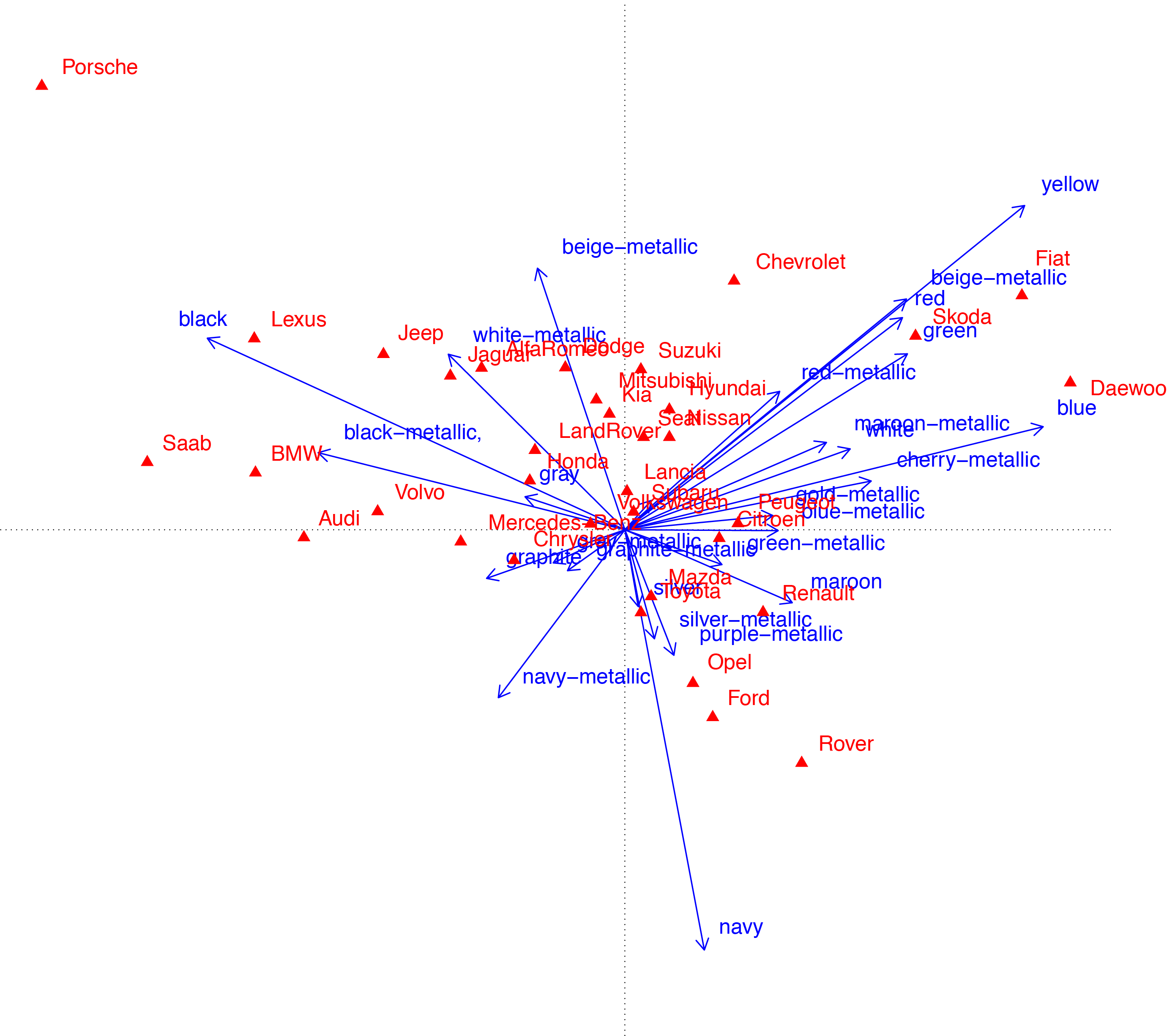
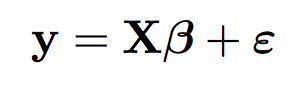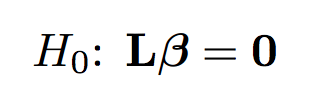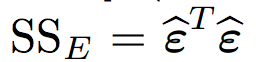The marathon of teams’ data analysis
In just four days’ time we are going to start a marathon of teams’ data analysis. This time it’s a local Warsaw event, but next time? It’s up to us! Let us sum up what we know about that event.
 CodiLime (deepsense.ai) is a sponsor.
CodiLime (deepsense.ai) is a sponsor.
Organizers include Smarter Poland and the Faculty of Mathematics and Information Science of the Warsaw University of Technology.
The projects are prepared in substantive cooperation with the International Institute of Molecular and Cell Biology, Educational Research Institute and Copernicus Science Centre.
The event is organized for students and graduates interested in data analysis. It is dedicated to people who want to work in a team and realize an important and interesting project; those who want to learn what are the tools and methods used by other analysts.
The problems which we are going to face are as follows:
- analysis of data from the project The Cancer Genome Atlas Project (hundreds of gigabits of data – most probably we will make use of only the tip of that iceberg) with a view of determining why in some cases chemotherapy does not affect the cancer,
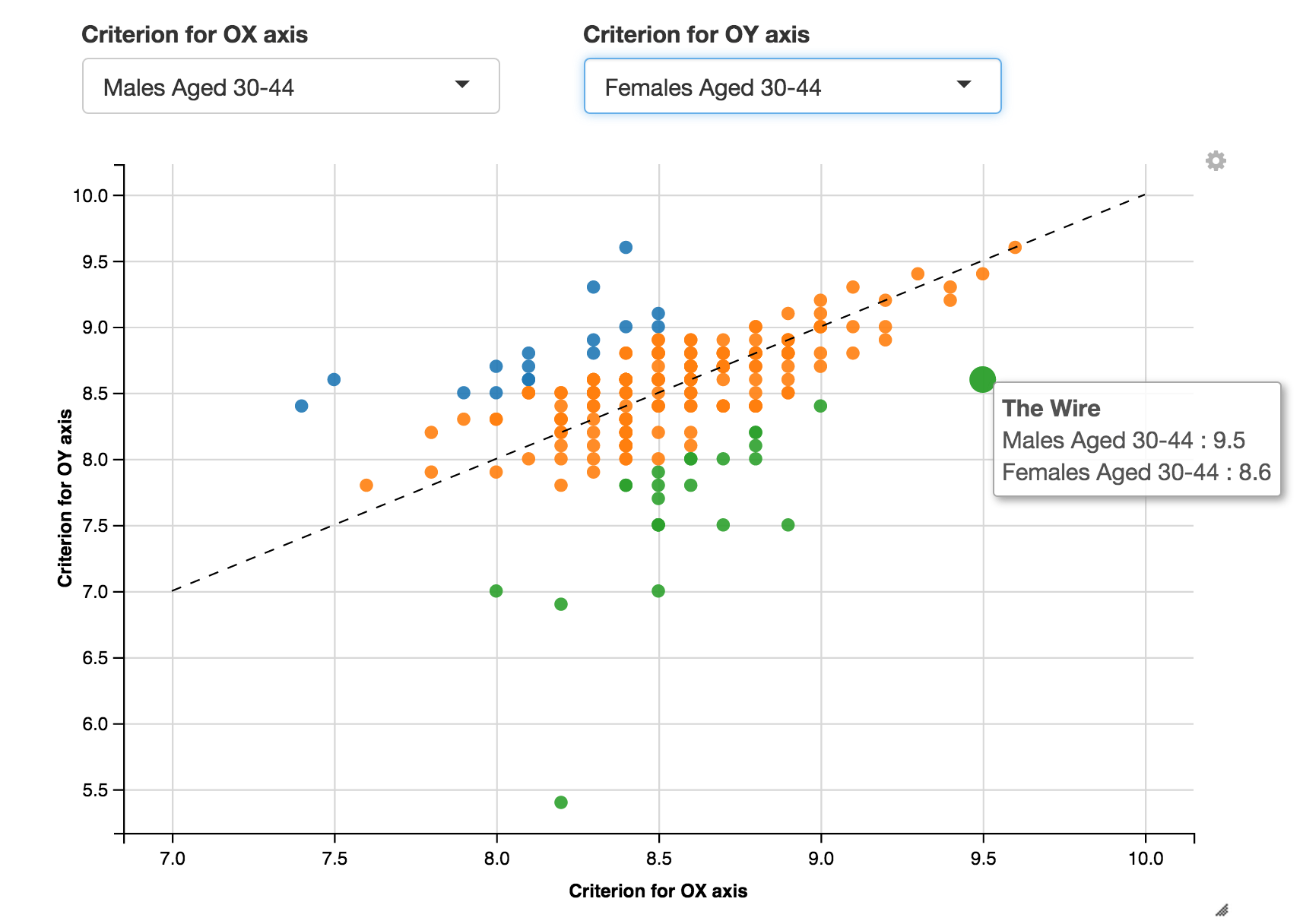
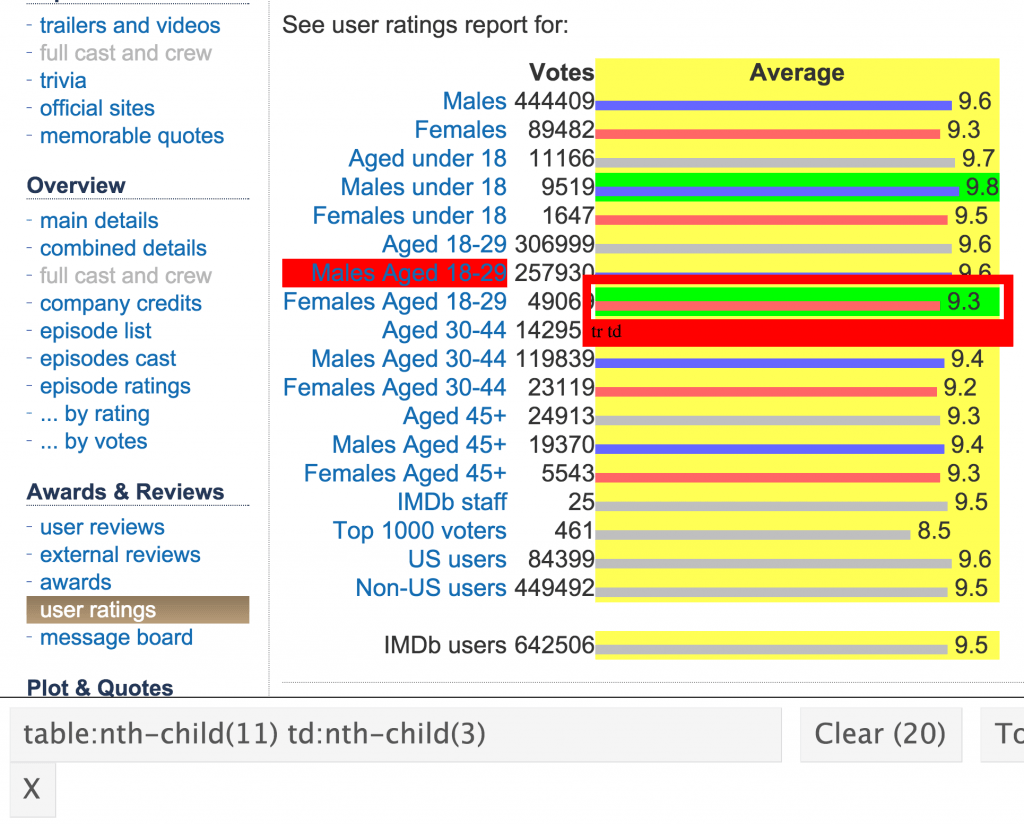
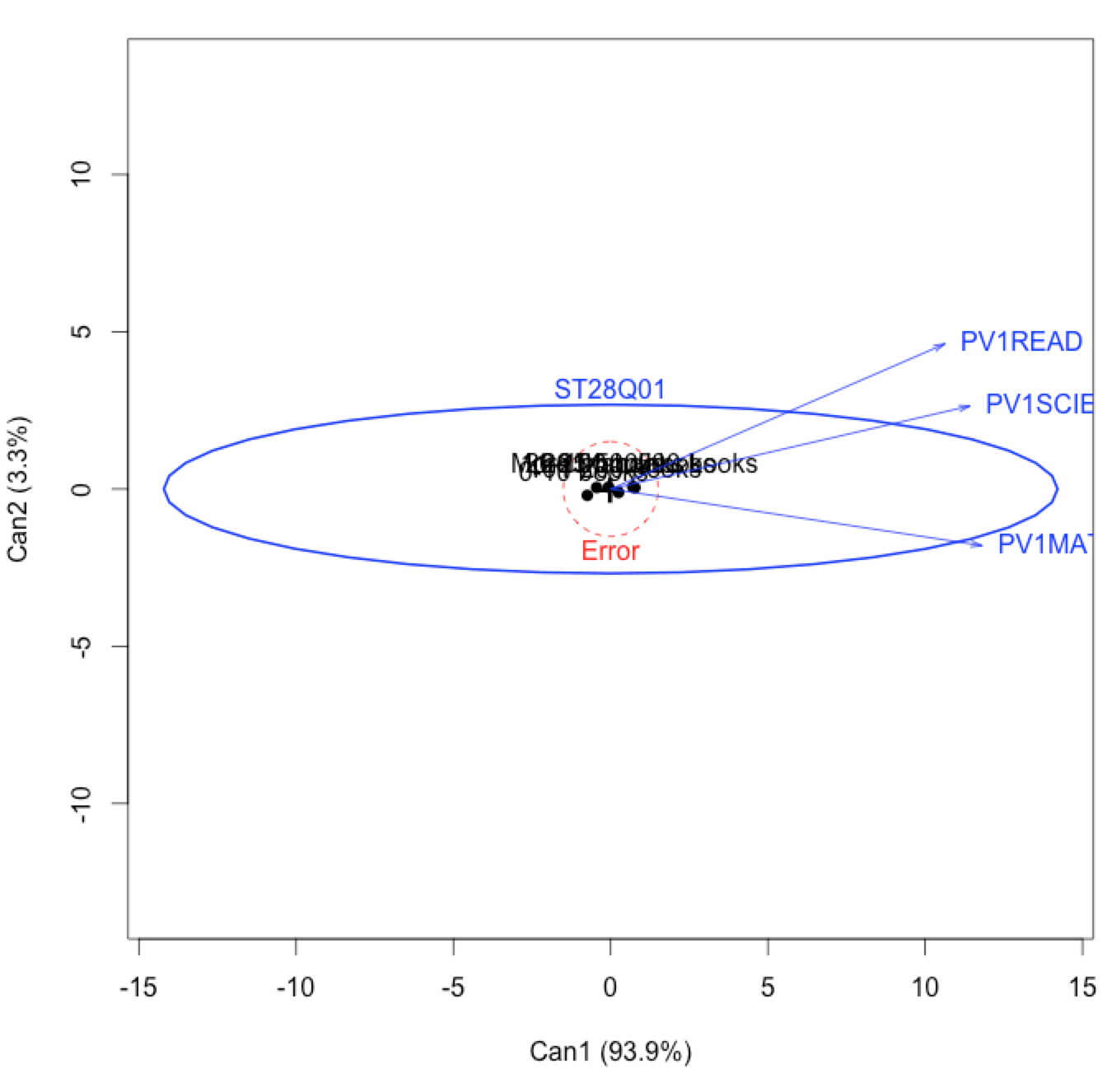
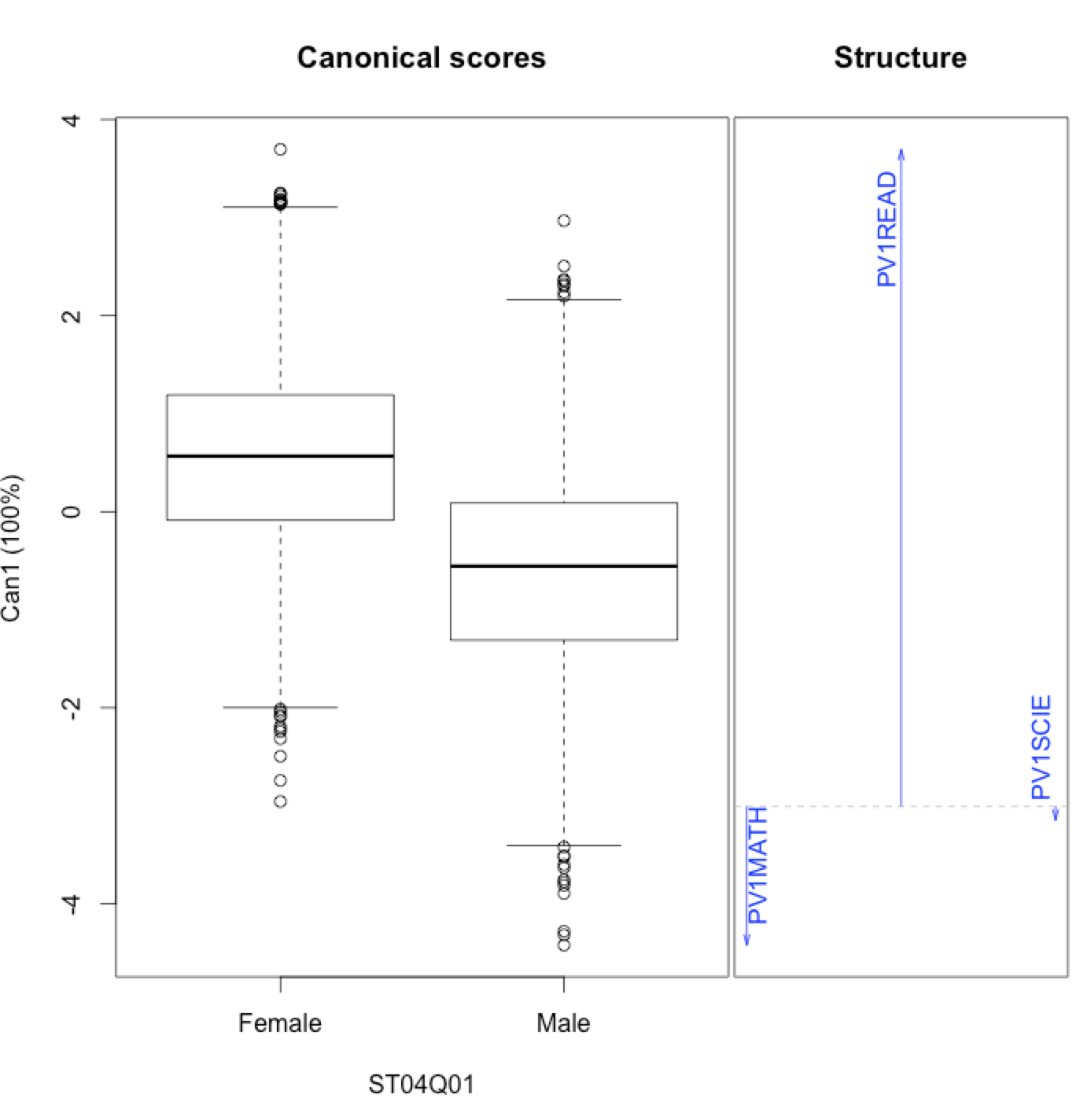
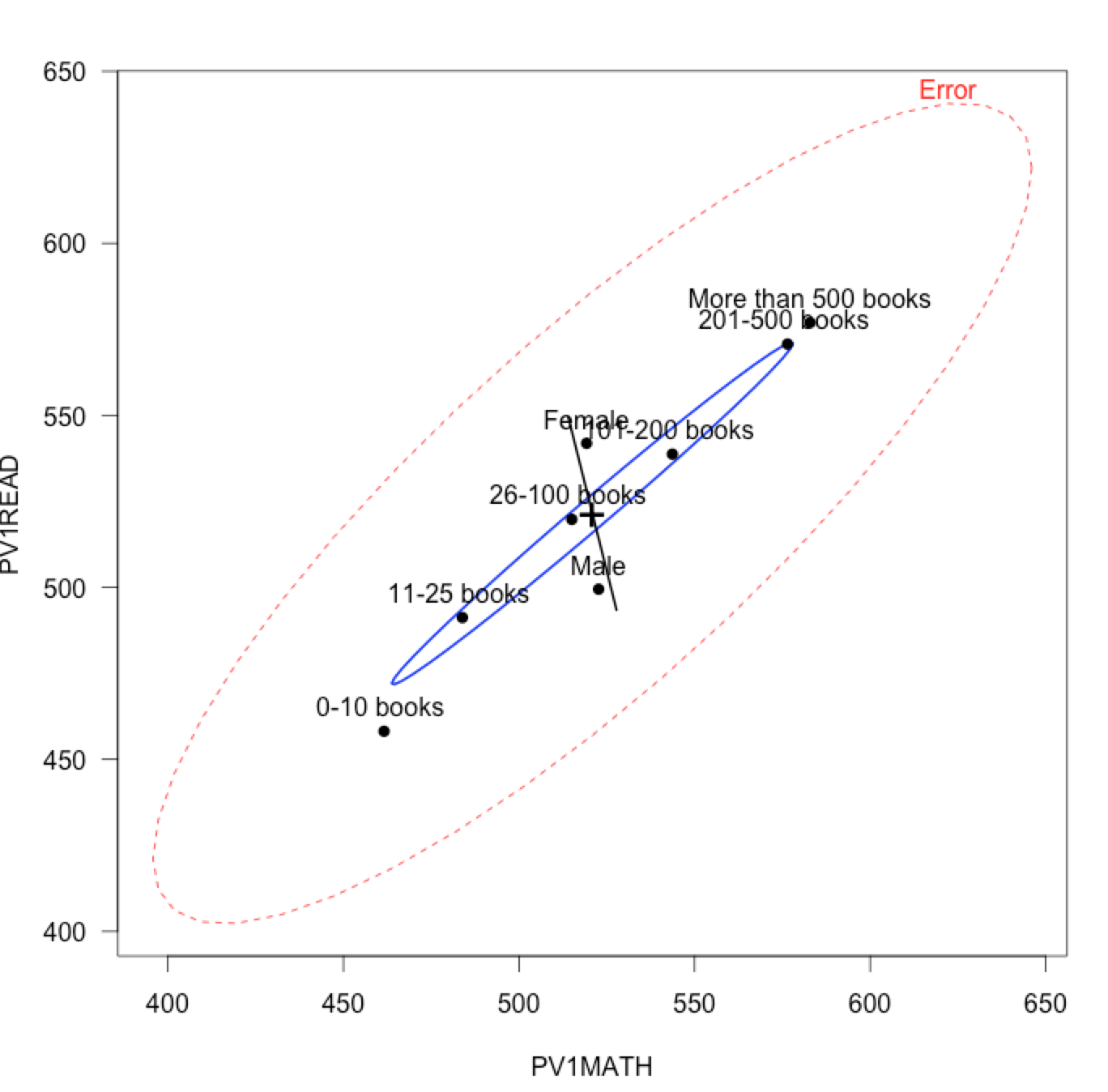
- analysis of data from over 600 thousand Matura exams from maths with a view of factors that influence results from that exam,
- segmentation and determination of a profile of an average visitor of the Copernicus Science Centre.
A link to the registration form: https://www.facebook.com/events/921016974586900/.
During the registration procedure you will be able to choose preferable issue (cancer, Matura exam, profiling) and your tools of choice. On the basis of this data we will assign participants to particular problems.
The marathon will take place at the third floor of the building of the Faculty of Mathematics and Information Science of the Warsaw University of Technology (75 Koszykowa Street). Each issue will be analyzed in a different room.
A working agenda of the meeting is as follows:
8:30 – 9:00 – registration of the participants
9:00 – 9:15 – inauguration and organizational announcements
9:15 – 9:30 – division into groups
9:30 – 12:30 – group data analysis; meanwhile the tutors walk around and help the participants
13:00 – 14:00 – a warm meal
14:00 – 18:00 – further data analysis
18:00 – 18:50 – tutors select the best solutions to be presented
18:50 – 19:00 – a short presentation of the sponsor
19:00 – 20:00 – presentation of the best solutions
Przemyslaw Biecek