Table of contents
Table of contents
Modern science is facing a completely new challenge: overload. According to research from the University of Ottawa, the total number of research papers published since 1665 passed the 50 million mark in 2009 and approximately 2.5 million new papers are published every year. In fact, it is nearly impossible to be up-to-date with all this information, at least for a human being. Machine learning tools make it easier and faster to find information in today’s ever vaster trove of publications.
Books-box.com runs a platform with access to a wide variety of science-oriented literature. Its library contains around 5,000 books across multiple categories. But rather than distributing whole books in a digital form, it provides page-level access to required pieces of knowledge. This is often the case in academia and research work, where a particular piece of information is needed to enrich a paper and deliver more credible information.
We had the pleasure of working with books-box.com and providing them with NLP services. The goal of the project was to create a recommendation engine that suggests relevant literature to users based on the content they’re viewing.
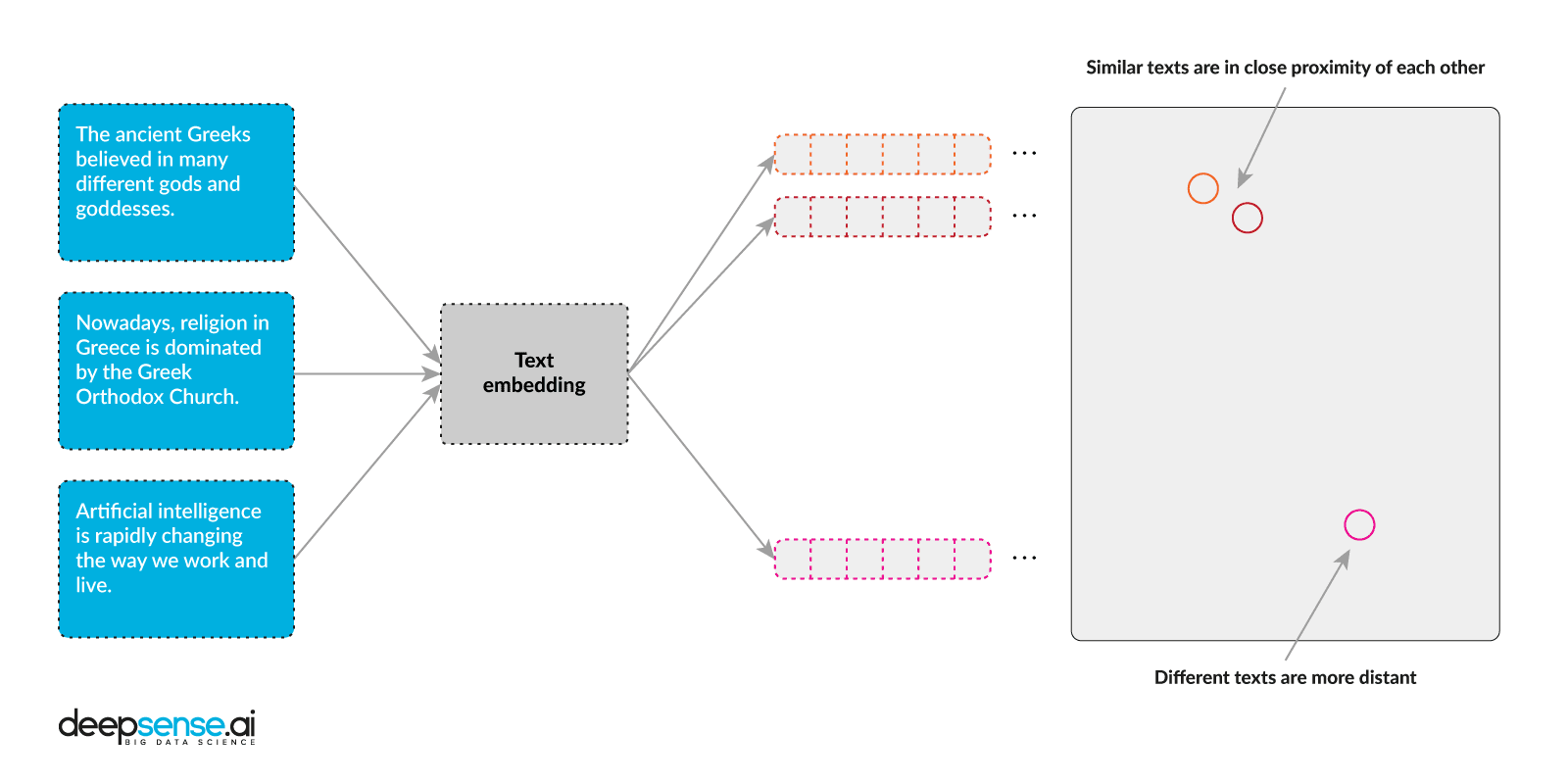 To create sentence embeddings we use the top-shelf neural network-based NLP algorithms ELMo and BERT. ELMo uses deep, bi-directional LSTM recurrent neural networks, while BERT uses the Transformer attention mechanism. The engine uses both algorithms to make final recommendations.
We developed a proprietary aggregation mechanism that allows us to generate aggregate embedding vectors for each book page. They allow us to easily check page similarity, by calculating the cosine similarity of two vectors, a standard metric in multidimensional vector space.
To create sentence embeddings we use the top-shelf neural network-based NLP algorithms ELMo and BERT. ELMo uses deep, bi-directional LSTM recurrent neural networks, while BERT uses the Transformer attention mechanism. The engine uses both algorithms to make final recommendations.
We developed a proprietary aggregation mechanism that allows us to generate aggregate embedding vectors for each book page. They allow us to easily check page similarity, by calculating the cosine similarity of two vectors, a standard metric in multidimensional vector space.
Text embedding
To make a book’s text readable to a computer, the words are transformed into vectors. A vector is just a set of real numbers that functions as input for a Machine Learning algorithm. If you would like to learn more about the technologies and techniques we use, click on over to our business guide to Natural Language Processing. One way to transform a sentence into a vector of numbers is one-hot encoding. This technique transforms a word into an n-vector where “n” equals the number of all unique words the model was taught during training. Unfortunately, this solution isn’t very useful for text because the vector becomes enormous and the word order and context are completely lost. Enter embeddings, the state-of-the-art in NLP algorithms. To create a sentence embedding means to assign a vector to a sentence in a vector space that conserves semantics. When two embedding vectors in this space are close to each other, the sentences they represent are similar in meaning. Commonly used vector size is between 100 and 1024, which is much smaller than the number of all unique words.
To create sentence embeddings we use the top-shelf neural network-based NLP algorithms ELMo and BERT. ELMo uses deep, bi-directional LSTM recurrent neural networks, while BERT uses the Transformer attention mechanism. The engine uses both algorithms to make final recommendations.
We developed a proprietary aggregation mechanism that allows us to generate aggregate embedding vectors for each book page. They allow us to easily check page similarity, by calculating the cosine similarity of two vectors, a standard metric in multidimensional vector space.
Recommendations
When viewing a page users will get five other page recommendations that may interest them. But having around 200,000 pages per book category to get recommendations means calculating 200,000 page embedding comparisons for each request! That’s a lot of computing time. But instead of calculating the similarity online, we calculate it beforehand, and store top recommendations. Having a pre-calculated cosine similarity between all pages, book-box’s recommendations can now be given almost instantaneously – the higher the score, the better the recommendation will be. Ball tree is an alternative solution to storing raw embeddings in a multi-dimensional, space partitioning data structure like k-d tree. The beauty of this approach is that it doesn’t require all possible embedding comparisons to be calculated. Instead, the data structure enables the optimal search for the nearest points (embeddings) in multidimensional space. In our case, however, there is one problem with this approach – from the business side we have required for one page to have recommendations from a variety of books. But top k similar pages for one (k is a parameter which needs to be chosen during the tree-build phase) would most likely be from the same book. And that was not the solution we were looking for.Threshold
Each pair of pages comes with a similarity score. In order to achieve the quality of recommendations desired, a threshold has to be selected. The higher the similarity score, the higher the quality of the recommendations will be, even if a smaller number of recommendations remain available. It is worth noting that assessing recommendation quality is not a straightforward (binary) task as it takes the subjective opinion of the assessor into account.Cloud deployment
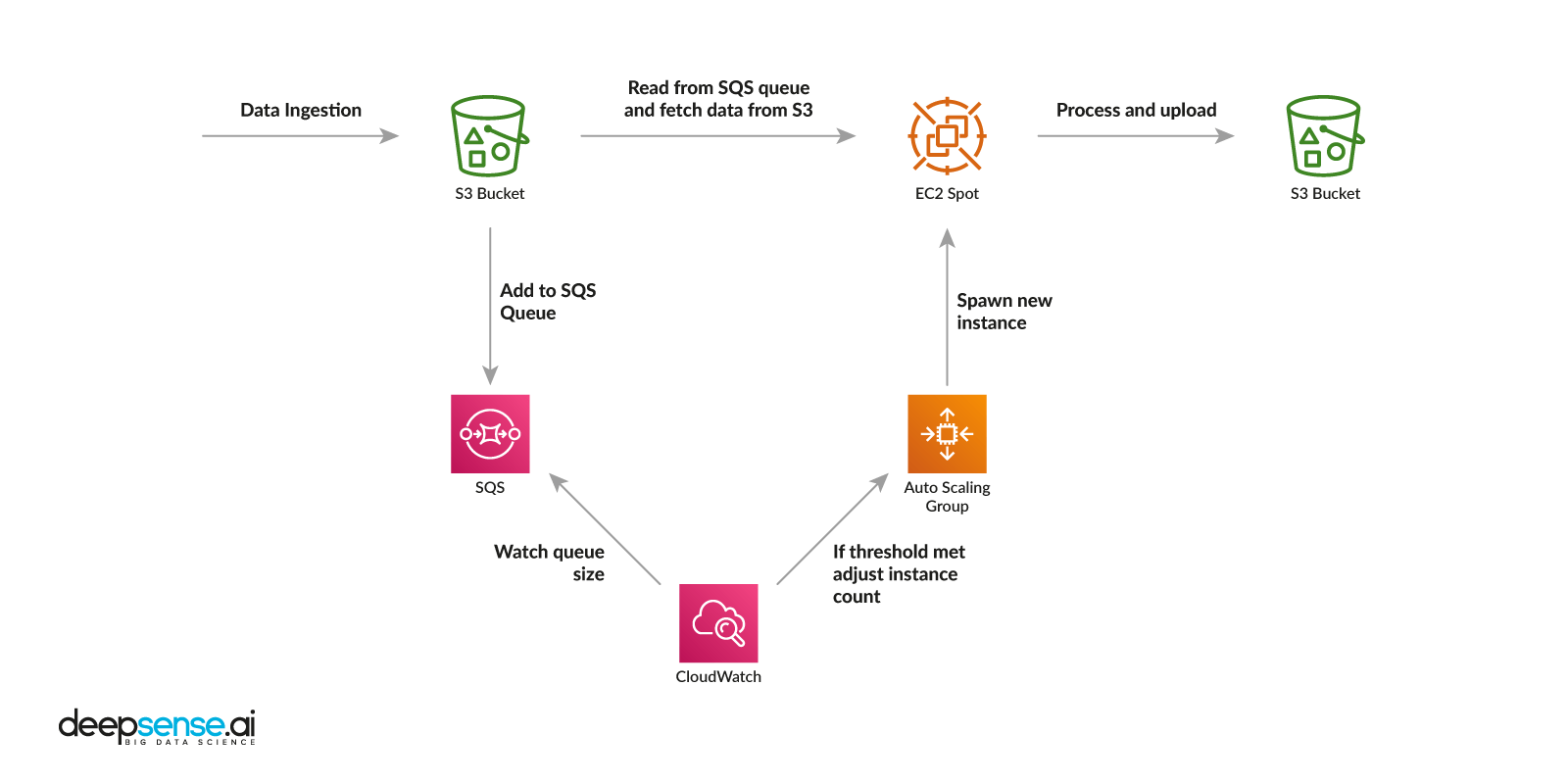
books-box.com regularly adds new books to its library. This entails preprocessing new books (parsing from html etc.), transforming their pages to embedding vectors and then updating the recommendation structure. Such operations require a lot of computing power, especially when we’re talking about thousands of books. To run neural networks for embedding, we need GPU devices for fast parallel computing. We decided to deploy our recommendation engine on Amazon Web Services (AWS) cloud, which allowed us to control costs and work on the solution’s elasticity, durability and scaling capabilities. AWS also provides a convenient system of spot instances that are available at a discount of up to 90% compared to on-demand pricing. Our deployment consists of three elements: API server, Simple Storage Service (S3) bucket, Graph updater.The API server
- Exposes a simple API to retrieve recommendations
- Provides API for category management
- Fetches new books and storing them in S3 basket
The S3 bucket
- Stores books
- Stores embeddings
- Stores recommendation graphs
The Graph updater
- Processes new books