Table of contents
Most enterprise voice AI still feels unnatural for a simple reason: the architecture was never designed for human conversational timing. What works in a chatbot often breaks in voice, where users notice every pause, interruption, and awkward handoff immediately.
At deepsense.ai, we see this gap all the time when voice AI moves from prototype to production. On paper, the stack looks straightforward: transcribe speech, run the LLM, synthesize the response. In practice, each stage adds latency, strips away vocal nuance, and makes it harder to deliver the responsiveness users expect in real conversations.
Realtime native audio models offer a meaningful shift. They collapse parts of the pipeline, reduce latency, and enable more fluid interactions. But they also force new architectural decisions around control, reliability, and tool orchestration.
This article explains what changes when you move from traditional voice pipelines to realtime voice-to-voice systems, based on our hands-on evaluation of OpenAI and Google models in an enterprise-style voice agent with RAG, tool calling, and observability built in from the start.
TL;DR – What You’ll Learn from This Article
- Why traditional voice pipelines fail in production
Compounding latency with the loss of paralinguistic cues (tone, emotion) frustrates users and degrades the customer experience. - The shift to real-time voice-to-voice architectures
How native multimodal models process audio directly, eliminating the Speech-to-Text and Text-to-Speech bottlenecks. - A case study
Lessons from building an experimental voice agent featuring RAG, tool calling, and enterprise observability. - GPT vs. Gemini showdown
The critical trade-offs between OpenAI’s flawless tool calling and Google’s highly cost-effective voice quality. - Where to deploy today
Why these models shine in empathetic, free-flowing conversations but aren’t yet ready for rigid, high-stakes data collection.
Our Voice AI Experience at deepsense.ai
At deepsense.ai, we’ve spent years working at the intersection of AI innovation and enterprise deployment. Our production deployments have taught us that success requires more than adapting existing tools—it demands rethinking how AI systems are architected from the ground up. To understand the challenges of voice AI, consider two of our recent commercial deployments:
- Outbound Sales & Appointment Voice Agent:
We developed a telephony voice AI agent capable of making human-like calls to potential customers. It navigates a complex, predefined conversation flow that includes voicemail detection, delivering tailored sales pitches, and negotiating time and date for in-person or immediate phone appointments (saving them directly via client APIs). The agent also updates lead statuses, handles seminar opt-ins, answers FAQs, and seamlessly transfers calls to human agents via PSTN when necessary.
- High-Precision Appointment Booking Voicebot:
A client came to us with an existing production voicebot that was struggling. Their approach relied on massive prompts, leading to high latency, bloated costs, and zero control over the output—the bot would even hallucinate available slots on days that were actually unavailable. We completely re-architected the solution. By restricting the LLM from communicating directly with the user and tightly controlling the output, we eliminated hallucinations. The new system is highly debuggable, maintains a rock-solid median API latency of just 520ms, and uses a highly predictable 1,200-1,300 tokens per call.
These projects reinforced a critical lesson: traditional voice pipelines often struggle with latency and control, and the landscape is about building systems that can maintain natural human pacing under real-world conditions.
Solving the Latency Challenge
The key difference when building a voice agent today lies in where and how speech is handled. There are two primary approaches, each with significant implications for performance and user experience:
1. The Traditional Sequential Pipeline (Voice -> Text -> Voice)
Historically, voicebots have relied on a three-step sequential pipeline orchestrated on your own servers:
- Speech-to-Text (STT): The user’s audio is transcribed into text.
- Reasoning (LLM): The text is processed by a Large Language Model to generate a text response.
- Text-to-Speech (TTS): The text response is synthesized back into audio.
While this approach introduces compounding latency at each step, it is far from being limited to simple tasks. At deepsense.ai, we have successfully developed and deployed complex commercial projects (such as automating calls to book in-place appointments) using this sequential architecture. Through these deployments, we’ve gathered crucial lessons on optimizing the traditional pipeline:
- UX is as critical as technical execution: Generating a user response involves multiple steps (intent detection, database retrieval, API calls, audio synthesis). To mask latency, actions can be executed in parallel or in the background, while background sounds can be added to maintain a natural conversational flow.
- Design conversations for longer responses: Many ASR systems struggle with very short utterances. Designing the conversation to encourage fuller, open-ended responses helps the voicebot “hear” more accurately, resulting in smoother interactions.
- Human-like, natural voice is critical: We found that prompting TTS models to sound more empathetic often yields inconsistent tonal variation. It is better to evaluate and select a TTS provider with inherently natural and stable output from the start.
- Constrain LLM usage when wording must be precise: In sensitive domains, we limit LLMs to intent recognition with structured outputs and keep the rest of the system deterministic and scripted. Pre-generating recordings, where feasible, drastically reduces latency and ensures consistent delivery.
Despite these extensive optimizations, managing pauses in a sequential pipeline remains a constant challenge. Furthermore, this approach inherently loses the rich paralinguistic cues of the user’s voice since the LLM only ever processes flat text.
2. The Realtime Pipeline (Voice-to-Voice)
The new paradigm utilizes native multimodal models. In a real-time pipeline, a single model handles audio input, reasoning, and audio output in one continuous stream. No intermediate text translation is required for the model to “understand” or “speak.”
This drastically reduces latency and allows the model to pick up on vocal nuances, making the interaction feel significantly more natural and conversational, a critical factor for driving user adoption and satisfaction.
However, the biggest drawback of this real-time approach is the lack of control over the model’s output. Because the model generates audio directly, we can only influence its responses through prompting. In contrast, the sequential approach offers fine-grained control-allowing developers to use response templates, inject pre-generated responses, or apply post-processing to the text before it is ever sent to the user.
Case Study: A Voice Agent Architecture
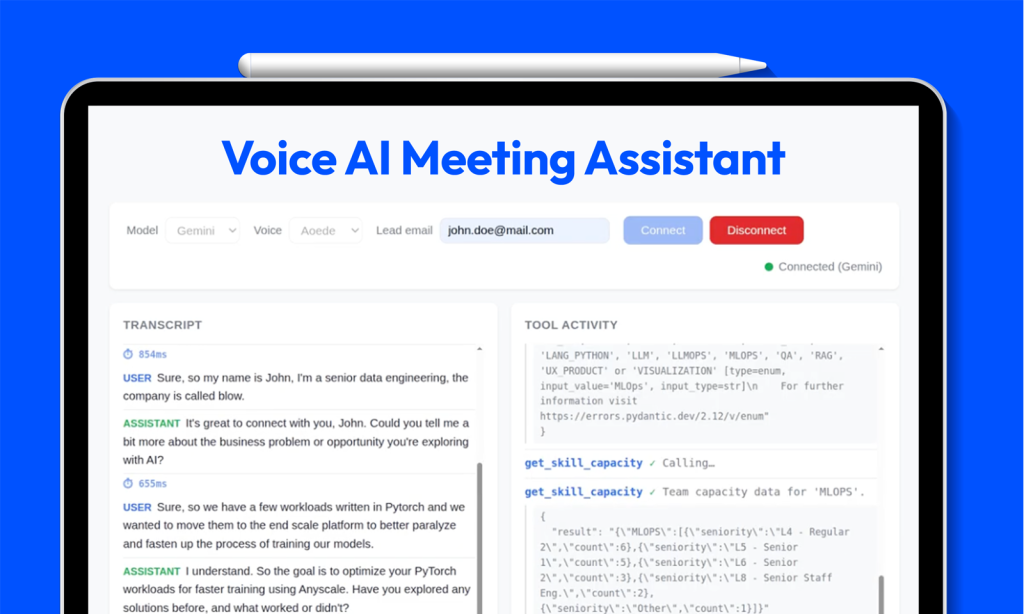
To rigorously test this new paradigm and its enterprise readiness, we built a prototype of a fully functional real-time voice agent acting as a proactive Sales Development Representative (SDR) for deepsense.ai.
The agent’s primary objective is to qualify incoming leads by guiding callers through a structured conversation-gathering contact details, understanding their business problems, defining project scope, and exploring budget and decision-making processes. Once the qualification is complete, the agent automatically emails a structured summary to the sales team.
Unlike typical enterprise integrations, real-time voice servers must handle continuous audio streams while maintaining enterprise-grade context and access to tools. Our architecture prioritizes speed and reliability, ensuring that every interaction is grounded in real data:
- Knowledge Base: A Vector database indexed on the deepsense.ai website to answer general company and service questions using RAG.
- Internal Data Tools: Live access to deepsense.ai’s project portfolio statistics and team capacity metrics, allowing the agent to dynamically answer specific questions about industry experience and staffing.
- Action Tooling: A Gmail integration to seamlessly send structured lead qualification summaries to the sales owner.
- Observability: Langfuse to trace, monitor, and evaluate interactions.
- The Contenders: OpenAI’s gpt-1.5-realtime vs. Google’s gemini-2.5-flash-native-audio.
Impressively, the entire codebase for this project was 100% AI-generated using Claude Code, allowing our engineers to focus entirely on architecture, rigorous evaluation, and user experience optimization. However, it is important to note that while this AI-driven development approach is incredible for rapidly prototyping a functional demo, it is not yet fully suited for deploying robust, maintainable commercial projects in production without significant human oversight and engineering rigor.
See It in Action
Want to experience the difference firsthand? Watch the demos below to see the realtime voice agent in action—qualifying a lead, retrieving live company data, and sending a structured summary to the sales team, all in a natural, free-flowing conversation.
Demo 1: Gemini (gemini-2.5-flash-native-audio)
See Google’s Gemini model in action, showcasing its superior voice quality and cost-effective performance in a live lead qualification conversation.
Demo 2: GPT (gpt-1.5-realtime)
Watch OpenAI’s GPT model demonstrate its flawless tool calling and natural conversational pacing, including spontaneous filler phrases while retrieving live data.
GPT vs. Gemini for Voice AI Breakdown
Both models achieved a smooth conversational flow with latency that is perfectly acceptable for real-time applications. However, our evaluation revealed distinct trade-offs that engineering teams must consider.
| Model | Cost & Latency Impact | Pros | Cons |
| OpenAI (gpt-1.5-realtime) | High cost (~$0.20/min), but unbeatable latency for real-time applications. | • Flawless Tool Calling: 100% success rate when using tools—paramount for complex, action-oriented agents interacting with internal APIs or CRMs.• Natural Conversational Pacing: Spontaneously inserts context-aware filler phrases (e.g., “Let me check on that…”) while processing, masking latency and feeling highly human. | • Cost: At ~$0.20/min, significantly more expensive, impacting ROI for high-volume use cases.• Voice Quality: Audio quality is “acceptable” rather than exceptional; occasionally shifts in tone mid-conversation. |
| Google (gemini-2.5-flash-native-audio) | Highly cost-effective (~$0.02/min) – 10x cheaper than GPT. | • Highly Cost-Effective: At just $0.02/min, highly attractive for scaling large-volume deployments.• Superior Voice Quality: Noticeably higher quality audio synthesis, delivering a very natural acoustic experience. | • Tool Calling Consistency: Occasionally requires more precise instructions for RAG tools to avoid failed queries; may need extra tuning for complex API workflows.• Conversational Friction: Challenging for users to “barge in” (interrupt). Lacks spontaneous filler words, resulting in dead air during processing. |
Here is what many organizations miss: these aren’t just minor feature differences. They fundamentally shape how your AI architecture must be designed from the ground up, depending on your business goals.
Lessons Learned: Where to Deploy Real-time Voice
Beyond the models themselves, building our experimental voice agent provided valuable insights into the current maturity of the technology. Both models demonstrated a strong ability to keep conversations on-topic, but they share some general limitations. Currently, these models perform optimally in English; multilingual support remains a challenge. Additionally, while hallucinations are infrequent, they still require robust guardrails.
Where Realtime Voice Shines Today:
- Free-flowing bots with generic conversational objectives (e.g., initial user triage, interactive FAQs).
- Scenarios where a human-like, empathetic experience adds significant product value.
- Low-stakes use cases where occasional conversational friction is acceptable.
Where to Avoid Realtime Voice (For Now):
- High-stakes environments where execution errors are critical.
- Compliance-focused projects requiring exact, specific wording.
- Bots focused on gathering extensive, highly structured user information (e.g., spelling out complex names, emails, and alphanumeric IDs).
AI Voice Experience as a Competitive Moat
Building voice agents for the enterprise isn’t just about adapting existing chatbot patterns-it requires rethinking AI infrastructure from the ground up with latency and natural interaction as core architectural principles.
The voice AI transformation is happening now. Organizations that master real-time native audio deployment will gain a significant competitive advantage by bringing AI-powered solutions to market faster and delivering better user experiences than their competitors. The question isn’t whether to build these systems, but whether you have the expertise to build them right.
At deepsense.ai, our production experience proves that enterprise-grade voice infrastructure is not just possible-it’s a competitive necessity for the future of customer interaction. Whether you choose the reliable tool-calling of GPT or the cost-effective, high-quality audio of Gemini depends entirely on your specific business requirements. We are dedicated to supporting your business every step of the way, helping you confidently navigate these architectural choices..
Table of contents





