
Table of contents
When moving a large language model (LLM) assistant from prototype to production, one rule is universal: if it’s not safe, it’s not ready. Skip this, and you’re not deploying innovation – you’re deploying risk.
For enterprises, this is especially critical. Whether it’s pharma, healthcare, financial services, or digital products, regulatory pressure and user trust leave zero room for error.
At deepsense.ai, we’ve built and deployed AI agents and GenAI systems for highly regulated industries. We’ve seen what happens when safety is treated as an afterthought, and we’ve built frameworks that prevent it.
The Hidden Risks of LLM Assistants in Production
The excitement of an LLM prototype is real: natural fluency, impressive reasoning, and wow-factor demos. But once exposed to real users, those same models often:
- Overshare or generate out-of-scope responses.
- Get exploited into discussing sensitive or non-compliant topics.
- Misinterpret user intent and deliver confidently wrong answers.
- Spiral into infinite loops, tangents, or offensive content.
From a security perspective, proof-of-concepts (PoCs) are playgrounds, production is war.
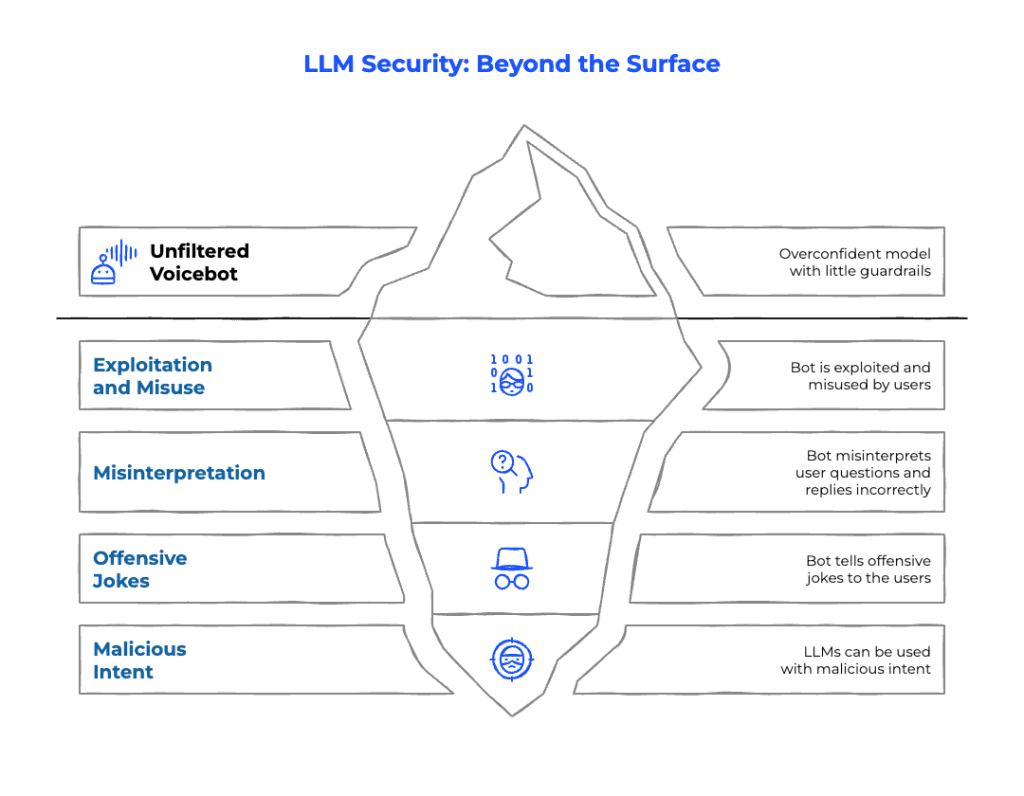
We’ve even observed how LLMs can be manipulated for malicious purposes, including radicalization attempts. This is why enterprises must assume adversarial usage from day one.
How to Build Secure AI Agents: From Lockdown to Controlled Freedom
When we were asked to fix an exposed AI voicebot, our first step was counterintuitive: we removed its ability to speak freely.
It felt like stripping away superpowers, the empathy, adaptability, and human-like tone. But this is how responsible AI deployment begins: design as if it will be abused.
Our process:
- Validate every output. Use predefined or verified responses. No unfiltered text-to-user pipelines.
- LLMs for intent discovery only. Let the model understand what users want, not improvise sensitive answers.
- Incremental functionality. Expand safely, testing each addition against strict compliance and AI governance rules.
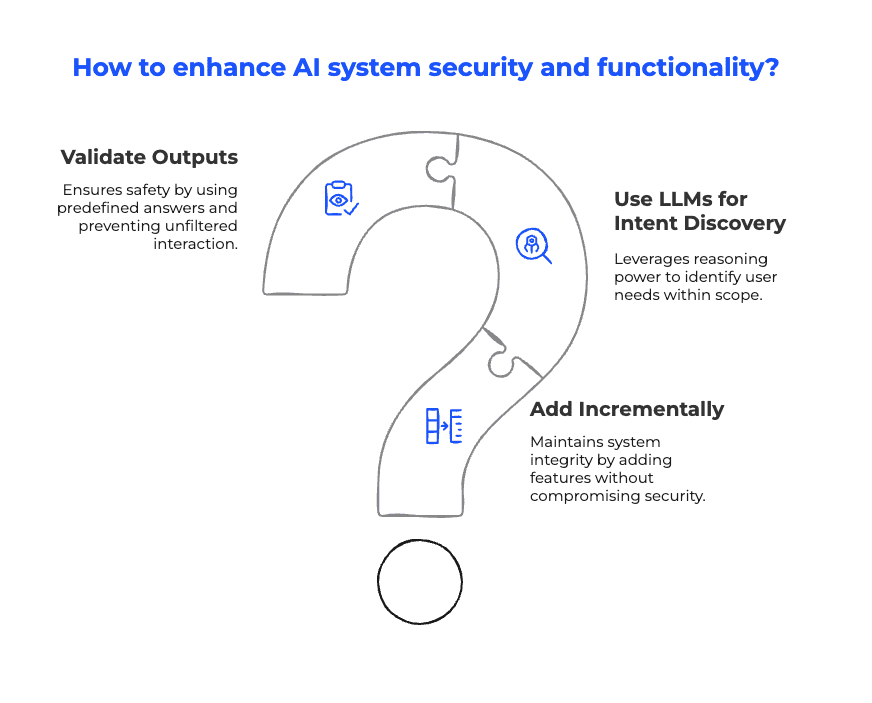
We built this using a custom conversational AI framework (think along the lines of RASA CALM), ensuring safety-first deployment.
AI Security in Practice: Trust, but Verify
Only after safety foundations were solid did we introduce more freedom. The philosophy shifted from “let it speak” to “trust, but verify.”
- Strict control of conversation state was maintained.
- Automated pipelines with tools like promptfoo enforced guardrails.
- Continuous adversarial testing uncovered vulnerabilities before attackers could.
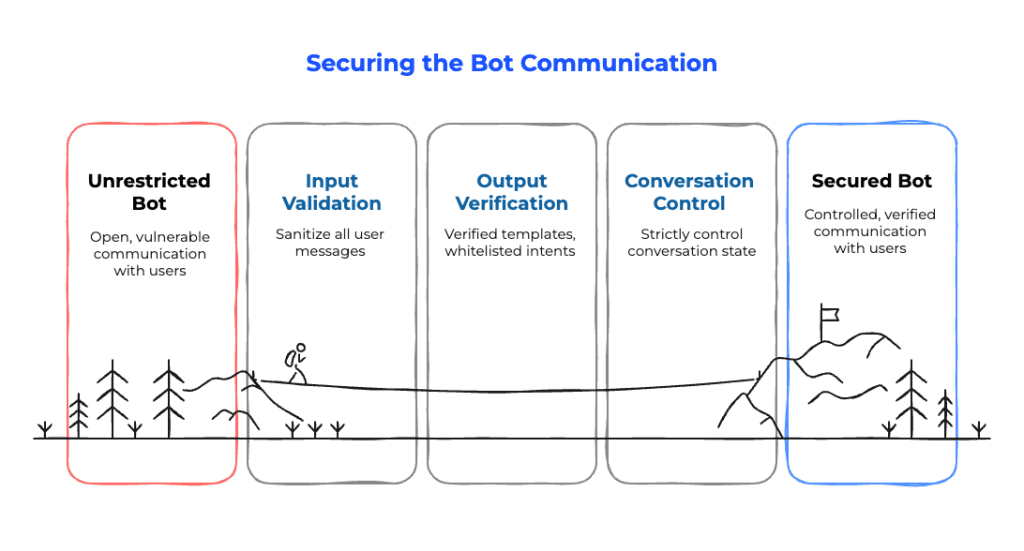
This discipline has been battle-tested in healthcare AI deployments in Europe: safeguarding doctors, patients, and compliance requirements while still delivering natural, efficient digital assistants.
Conclusion: Safe AI Deployment Is Non-Negotiable
Prototyping is for experimentation. Production is for discipline.
Enterprises must recognize:
- Every user input is a potential attack vector.
- Every output must be verified.
- Every boundary is non-negotiable.
That’s not optional. It’s the price of deploying AI agents responsibly at scale.
Because in the real world of enterprise AI adoption: If it’s not safe, it’s not ready. And that’s a feature, not a bug.
Table of contents





