
Table of contents
Most Vision-Language-Action (VLA) models never make it out of the lab. They’re too heavy, too power-hungry, and too slow to run on real-world, resource-constrained hardware. At deepsense.ai, we wanted to know:
what’s the smallest, lightest, cheapest device that can still run an embodied AI system in the wild — and run it well?
So, we pushed VLAs onto platforms weighing under 100 grams, tested them against industrial-grade GPUs, and measured everything from sub-centimeter localization accuracy to token generation rates for chat-like LLM experiences. The results surprised us, and could change how you think about edge AI deployment in 2025–2026.
TL;DR – What You’ll Find Inside
If you’re considering embodied AI for robotics, manufacturing, or logistics, this article gives you:
- Three VLA architectures compared: Modular, Unified, and Multi-Model, with pros and cons for edge deployment.
- Hard numbers from our tests: refresh rates up to 354 Hz, sub-centimeter localization accuracy, and chat-capable LLM inference on Raspberry Pi 5.
- Hardware head-to-head: Raspberry Pi 5, NVIDIA Jetson Nano, RTX 2080 Ti, and Hailo-8L accelerators, ranked by performance, power use, and deployability.
- Where most VLAs fail on the edge: and how a modular approach beats the trade-offs between capability and efficiency.
- The “100g AI” proof point: why lightweight embodied AI isn’t just possible, but practical for field-ready systems in 2025.
From Transformers to Edge Robotics: How AI Evolved into the Era of Embodied Intelligence
In recent years, AI has advanced at a remarkable pace. The first wave, from 2017 to around 2022, was the software revolution, sparked by the Transformer architecture (Vaswani et al., 2017) and culminating in the launch of ChatGPT. It was a transformative era for purely digital intelligence.
The next phase, beginning in 2022, brought multimodal models capable of processing vision, text, and audio. We also saw a shift in paradigm: from compute-heavy training to smarter, test-time-compute–focused, reasoning-capable models. Recent milestones, such as OpenAI and Google topping international science olympiads, are just one sign of this acceleration.
In parallel, an equally important frontier has been emerging: embodied AI, where systems not only understand the world but also act within it, increasingly on the edge, in real-time, and on lightweight, cost-efficient hardware.
The Rise of Vision-Language-Action (VLA) Models: Powering the Next Wave of Embodied AI in Robotics and Edge Computing
Embodied AI is moving from research labs to real-world deployment – fast. At the center of this shift are VLA models: systems that can not only see and understand the world but also act within it.
We’re witnessing a major architectural evolution, from modular systems to singular, end-to-end models, and now to layered designs that resemble dual-process thinking (Kahneman’s “System 1 and System 2”).
Tech giants are already betting big. Google is building Gemini Robotics, NVIDIA and Figure AI are advancing embodied agents with tightly integrated vision capabilities, and VLAs are quickly becoming the new benchmark for embodied intelligence.
Imagine a warehouse drone that can visually scan shelves, understand spoken or text instructions, identify objects with sub-centimeter accuracy, and guide workers on where to place goods, all autonomously. This isn’t science fiction. It’s happening right now.
By fusing vision, language, and action, VLAs bring machines into the unpredictable, dynamic, and nuanced real world. They’re poised to transform industries from manufacturing and logistics to autonomous robotics, unlocking capabilities that pure digital intelligence could never achieve.
Our Recent R&D Focus: Lightweight VLAs for Edge Deployment
At deepsense.ai, we go off the beaten path, break the mold, and aim to set future trends, with our current R&D centered on pushing VLAs to the edge, quite literally. We asked ourselves:
What’s the smallest, lightest platform that can realistically run a fully functional VLA model?
And just as importantly: What kinds of intelligent behaviors can we enable on such resource-constrained devices?
We focused our recent experiments on devices weighing less than 100 grams, systems small enough for lightweight drones or handheld robots. Our platforms included:
- Raspberry Pi 5 features the Broadcom BCM2712 quad-core Arm Cortex A76 processor and it is able to execute LLMs with a chat-like experience. It can be extended by Hailo-8 AI accelerator, which delivers up to 13 TOPS and transforms Raspberry Pi into a computational beast


- NVIDIA Jetson Nano is an edge AI platform, providing powerful GPU performance in a small and affordable package. It includes 4GB of RAM and is ideal for running modern AI workloads.

- Desktop RTX GPU is a high-end graphics card designed for deep learning and AI workloads. It offers exceptional performance and is often used in high-end workstations. In our experiments, NVIDIA GeForce RTX 2080 Ti has been used as a baseline.

The chosen platforms are known for their affordability and provide relatively high computational power in small, lightweight, and power-efficient form factors, which makes them a perfect choice for the development of autonomous machines !.
How to Realize a VLA Model: Architecture Choices & Key Metrics
Edge AI is transforming industries such as manufacturing and logistics by bringing artificial intelligence processing closer to the source of data, enabling faster, more efficient, and more private operations.
However, it also presents challenges. In a conventional implementation, a VLA takes text and/or images as input, converts that data into tokens, and then takes actions in response to the current situation. In a nutshell, VLAs integrate multiple capabilities into a single model — the Unified VLA — which significantly increases complexity. This complexity often makes deployment on resource-constrained edge devices impractical.
As part of our research, we explored three possible VLA implementation approaches, analyzing the pros and cons of each.
Realizing VLA Architectures: Three Design Paradigms
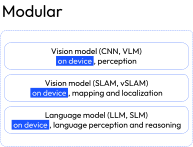
1. Modular VLA
In this approach, all core functionalities, perception, mapping, localization, and language understanding, are split into separate models. This provides significant flexibility for edge deployment: each algorithm can be individually optimized for execution on resource-constrained devices, and easily swapped or fine-tuned for specific customer needs (e.g., operation in different environments). It also improves cost efficiency, since these algorithms can run on relatively inexpensive microcomputers.
The trade-off? Modular architectures introduce higher communication overhead between modules, requiring efficient communication strategies. They also make it more challenging to achieve deep cross-modal understanding between individual models.
2. Unified VLA
This approach combines computer vision, mapping, and localization, language understanding, and action-taking into a single model. Unified VLAs excel at cross-modal understanding and can perform exceptionally well on tasks with diverse inputs — for example, a sequence of images, text, and spoken language.
However, their complexity comes at a cost: more parameters mean higher resource requirements, making deployment on edge devices more difficult. Large parameter counts also limit fine-tuning or customization for specific use cases.
3. Multi-Model VLA
Here, the workload is split between two VLAs: a smaller, reactive VLA running locally on the device, and a larger, reasoning-capable VLA running in the cloud. The local model handles immediate actions, while the cloud model processes more complex reasoning tasks.
This hybrid approach seeks to balance real-time responsiveness with advanced capabilities. It can outperform modular architectures in some scenarios but comes with its requirements — reliable internet access, and edge hardware with greater resources to support the local VLA.
Given the resource limitations of these devices, we opted for a modular VLA architecture, simpler to manage and more realistic for deployment. While newer layered or singular end-to-end VLAs are promising, they’re still too heavy for edge environments. Below you can find a chart summarizing all approaches:


Testing Real-World Capabilities with Embodied AI
Our experiments targeted two critical competencies for embodied systems:
- Perception – The ability to detect and understand objects and agents in the environment.
- Spatial Awareness – The ability to localize the system in space, relying purely on visual input (e.g., stereo vision), with no LiDAR or GPS.
We designed our tests with realistic applications in mind, for example, enabling a drone to safely navigate a warehouse without hitting workers or obstacles, using only onboard vision and lightweight processing.
We measured:
- Model performance and responsiveness
- Energy consumption vs. inference speed
- Reliability, capability under real-time constraints
- Hardware deployment feasibility, resource requirements
The summary of metrics used to assess VLA models can be found in the table below.
| Metric | Description | Guiding Rule |
| Hz (Hertz) | Refresh rate of VLA. Higher is better for reactive control and real-time performance (especially in robotics). | More = Better |
| W (Watts) | Power consumption. Lower is better for battery life and system operation time. | Less = Better |
| C (Capability) | Overall VLA capacity (autonomy, understanding). Higher is better. | More = Better |
| KPIs & Guiding Rules Used to Assess the Capability of Given Device | ||
Our results, which we’ll detail in the next section, offer a first glimpse into what’s truly possible with embodied AI on the edge. They also highlight the trade-offs between model complexity and deployability, an essential insight for those building real-world AI solutions.
Tests and Results
We divided our tests into three categories:
- Visual Perception
- Language Understanding
- Spatial Awareness
It’s important to note that we did not measure accuracy in any of these categories. Our focus was on assessing how well models operate in resource-constrained environments, not on evaluating their absolute quality. Model quality assessment should be the focus of a separate study.
For visual reference, we indicate different capability levels using circle sizes: the larger the circle, the more capable we believe a model to be. For example, we consider YOLO11l (large) to be more capable than YOLO11n (nano), and have represented this with a proportionally larger circle.

Visual Perception
Robots must be able to identify objects in their surroundings, not only to determine, for example, what to grasp, but also to detect hazards, recognize people, and respond appropriately.
For our target application — an autonomous robot operating in a warehouse environment — we focused on testing object detection algorithms. We used a dataset collected directly in the warehouse, ensuring the evaluation reflected real-world conditions.
An example detection result is shown in the image below.

Tested Models
We focused on the YOLO family of models as it provides plenty of models of varying sizes to choose from and can be easily deployed on almost all kinds of devices. They can also be exported to ONNX format, which allows for optimizations like TensorRT.
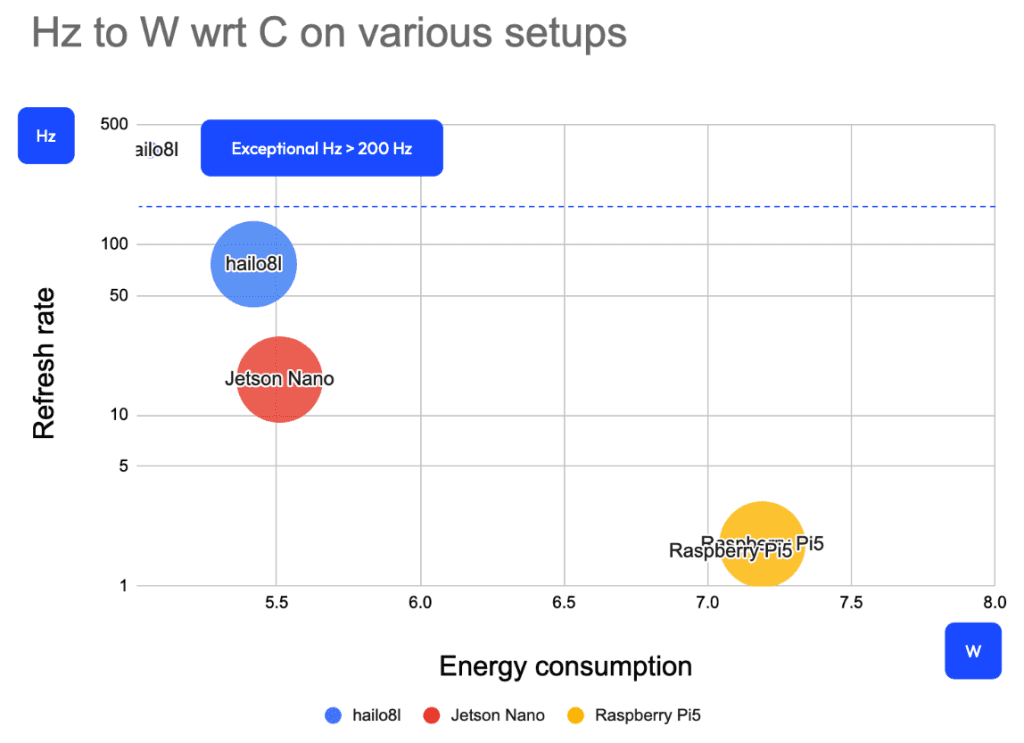
Results:
| Device | Model | Hz | W |
| hailo8l | YOLO11n | 76.30 | 5.42 |
| YOLO6n | 354.79 | 5.06 | |
| Jetson Nano | YOLO11n | 16.13 | 5.51 |
| Raspberry Pi5 | YOLO11n | 1.75 | 7.19 |
| YOLO6n | 1.59 | 7.08 | |
| GeForce RTX 2080 Ti | YOLO11n | 109.89 | >100 |
Key Takeaways
- We achieved refresh rates above 50 Hz, and in some cases over 200 Hz, on lightweight platforms. High refresh rates are essential for detecting obstacles or other hazards and reacting in time.
- There is little trade-off here: Hailo outperforms both Jetson Nano and bare Raspberry Pi 5 in refresh rate and power efficiency. While its higher refresh rate is expected (it’s a modern GPU), its lower energy consumption is a welcome surprise.
- Model selection still matters. For example, YOLO6n delivers a higher refresh rate, but its quality must be evaluated to ensure it meets the requirements of specific use cases.
Language Understanding
There are several reasons to add language understanding to an embodied AI system, but the most important is the ability to interact naturally with humans, to understand their commands and interpret their feedback. This requires both voice recognition and language understanding; however, we focused primarily on the latter, as it is significantly more resource-intensive.
Some models, such as Gemma 3n, provide both capabilities, but we encountered challenges deploying them on our target machines.
We also faced difficulties using GPUs for processing:
- Hailo – We could not convert the models into a format supported by Hailo. Currently, Hailo for Raspberry Pi 5 does not offer LLM support.
- Jetson Nano – While its GPU could theoretically support LLMs out-of-the-box, all current LLM frameworks require at least CUDA 11, which the Jetson Nano does not support.
Tested models:
| Device | Model | Hz (token/s) | W |
| Jetson Nano CPU | Qwen2.5-0.5B-Instruct.Q4_K_M | 9.15 | 5 |
| Raspberry Pi5 | Qwen2.5-0.5B-Instruct.Q2_K_M | 24.57 | 7.5 |
| Qwen2.5-0.5B-Instruct.Q4_K_M | 22.38 | 8.2 | |
| Qwen2.5-0.5B-Instruct.Q8_K_M | 16.51 | 8.5 | |

Key Takeaways
- A chat-like experience requires a token generation rate of at least 10–15 TPS, and we found this is achievable even on a lightweight platform like the Raspberry Pi 5.
- There is a trade-off between token rate and energy consumption: Raspberry Pi 5 delivers a higher token rate but consumes significantly more energy than the Jetson Nano.
- Model size is another trade-off — careful analysis is needed to determine which quantization level provides sufficient quality for the intended use case.
Spatial Awareness
Visual Simultaneous Localization and Mapping (VSLAM) is essential for enabling mobile robots to navigate and interact with their environments. Using cameras, whether monocular, stereo, or RGB-D, VSLAM constructs a map of the robot’s surroundings while simultaneously estimating its own position within that map. These two tasks are tightly coupled: high-quality map construction improves localization, while accurate localization supports more robust mapping.
Localization and mapping are critical components of spatial awareness, especially when there is no prior information about the environment the robot is entering. This is why we chose to run and evaluate VSLAM in our tests.
We evaluated the performance of Stella VSLAM using the widely adopted TUM RGB-D dataset (shown below). The evaluation workflow consisted of two steps:
- Deployment and Trajectory Generation – Stella VSLAM was deployed on both Raspberry Pi and NVIDIA Jetson Nano platforms, processing TUM RGB-D sequences to generate estimated camera trajectories, which were saved along with corresponding timestamps for further analysis.
- Trajectory Alignment and Accuracy Measurement – Using the evo Python package, we aligned and compared the estimated trajectories against ground truth, measuring key metrics such as Absolute Position Error (APE).



Our experiments showed that Stella VSLAM achieved a mean localization error below 1 cm and a maximum error of around 3 cm across indoor sequences. The system processed frames in approximately 40 ms on both the Raspberry Pi and Jetson Nano, equivalent to about 25 frames per second.
These results demonstrate that Stella VSLAM can deliver both high accuracy and real-time performance, even within the constrained computational resources of edge platforms. The sub-centimeter mean error confirms its strong spatial awareness capabilities, making it well-suited for precision-dependent tasks such as indoor navigation, inspection, and manipulation.


The accuracy of mapping and localization generally improves as more observations are accumulated. The longer the trajectories and the richer the environmental features, the more precise and robust the results. However, this increase in observations comes at a computational cost, i.e.: more map features and data associations require additional processing power and memory, which can challenge the limited resources available on edge devices.
In Summary: How Modular VLAs Make Embodied AI Practical on the Edge
As AI systems become increasingly embodied, the need for efficient, responsive, and capable VLAs on edge devices is becoming critical. Our study highlights several key insights for designing and deploying VLA systems in resource-constrained environments:
- Metric-driven design matters. Edge-deployed VLAs must be responsive, battery-powered, and adaptable to unknown environments while maintaining low resource consumption. Feasibility studies should define and measure key metrics such as refresh rate, power consumption, capability, and resource requirements.
- Modular architecture is a practical choice for low-end edge devices. It offers the best trade-off between flexibility, reliability, and feasibility for edge deployment. Despite some communication overhead, it allows independent development and optimization of vision, language, and SLAM components.
- Hardware choice impacts everything. It directly influences inference time, power consumption, and overall deployment feasibility. For example:
- Hailo-8L dramatically boosts performance in computer vision tasks while keeping power usage low, outperforming Jetson Nano and Raspberry Pi 5.
- Hailo-8L does not support LLMs, making it unsuitable for language understanding tasks.
- Jetson Nano and Raspberry Pi 5 can both run LLMs with chat-like responsiveness, with Raspberry Pi 5 often outperforming Jetson Nano.
- For spatial awareness, VSLAM can deliver sub-centimeter localization accuracy and real-time frame rates on modest hardware like Jetson Nano and Raspberry Pi 5.
- Raspberry Pi 5 + Hailo-8L is an optimal pairing, covering all three core functionalities: vision, language, and spatial awareness.
Bottom line: Deploying VLAs on the edge is not just about picking the right model — it requires optimizing the entire pipeline: architecture selection, model optimization, hardware choice, and deployment strategy.
Our experiments revealed:
- Hardware limitations, such as a lack of LLM support on certain accelerators, can be mitigated with CPU execution on capable platforms like Raspberry Pi 5.
- Quantization can significantly improve inference time, but at the potential cost of accuracy — a trade-off that must be tuned through experimentation.
- With the right balance of responsiveness, accuracy, and power efficiency (as achieved with YOLO, Qwen, and VSLAM), it is possible to build highly capable autonomous robotics systems on low-cost, lightweight edge devices.
Conclusion: Low-end edge devices can run Modular VLA models efficiently, opening the door to practical, affordable embodied AI in real-world environments.
References
Akundi, S. (2024). The future of AI is not LLMs: Yann LeCun. https://shaastramag.iitm.ac.in/interview/future-ai-not-llms-yann-lecun
Druitt, M. V. (2025). AI’s Next Five Years: LeCun Predicts a Physical-World Revolution. https://www.klover.ai/ais-next-five-years-lecun-predicts-a-physical-world-revolution/
Nvidia Corporation. (2025). NVIDIA Expands Omniverse With Generative Physical AI. https://nvidianews.nvidia.com/news/nvidia-expands-omniverse-with-generative-physical-ai
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., N. Gomez, A., Kaiser, Ł., & Polosukhin, I. (2017). Attention Is All You Need. https://arxiv.org/pdf/1706.03762
Table of contents





