Table of contents
In applied AI delivery, teams are now producing more code than they can meaningfully evaluate. Code assistants are excellent at scaffolding, refactoring, test generation, boilerplate removal, and filling in the mechanical parts. That is real leverage.
At the same time, the ecosystem is already showing where this leads.
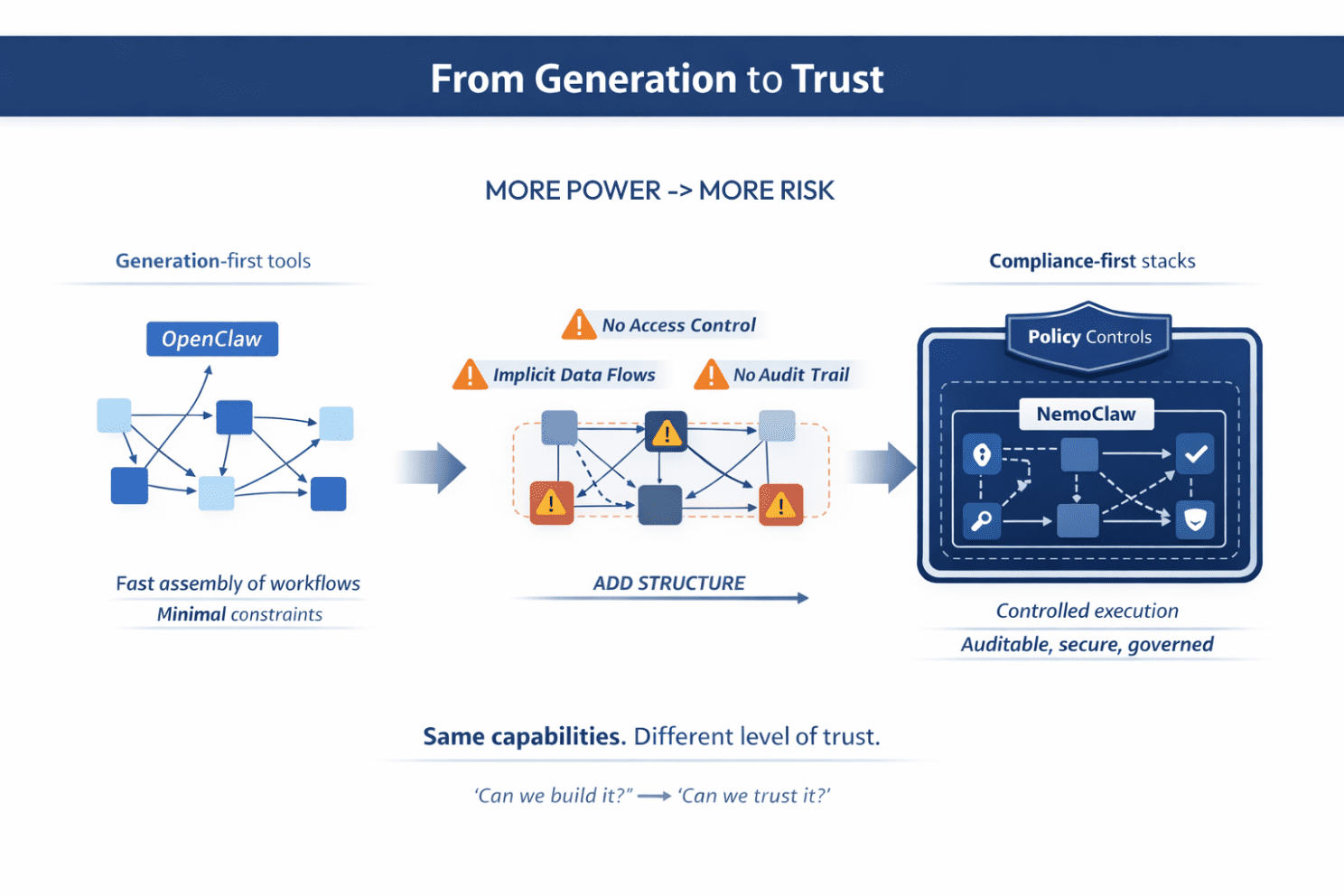
Take this case as an example: tools like OpenClaw are evolving into personal AI “operating systems,” making it trivial to assemble powerful, end-to-end workflows. But they also expose a gap: security, privacy, and control are not solved by code generation alone.
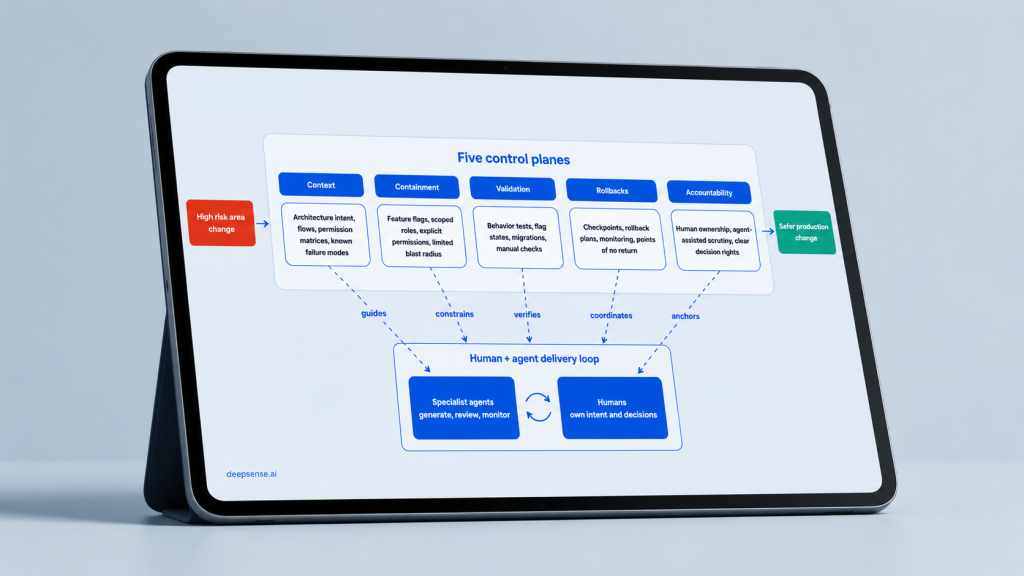
The response is immediate. Stacks like recent NVIDIA’s NemoClaw emerge to wrap these systems with policy-based guardrails, controlled data handling, and explicit governance layers. Same capabilities, but different level of production readiness. This is the shift from “can we build it?” to “can we trust it?”.
Our hypothesis is simple: AI makes code cheaper. That makes engineering judgment more precious.
In this issue, we explain why velocity metrics on their own mislead, where quality breaks down in systems built with AI assistance, and the sequence that turns code assistance from demo utility into production leverage.
TL;DR + Why Read This
- Understand why faster code generation does not automatically mean faster delivery in enterprise AI systems.
- See where quality actually breaks in AI-assisted development: integrations, trust boundaries, retries, observability, and governance.
- Learn why velocity metrics such as PR volume or lines changed are weak signals once AI makes code cheap.
- Get a practical framework for moving from AI-assisted implementation to production-ready systems in the right order.
- See how this applies in real enterprise settings, especially where compliance, auditability, and reliability matter most.
The Throughput Trap in AI-Assisted Development
Once code generation gets good enough, teams start measuring the wrong things. PR counts go up. Number of changes explode. Review cycles get shorter. Spikes appear faster. Demos look better. On paper, this feels like acceleration.
In practice, it often means the system is accumulating surface area faster than the team can validate it.
We saw this clearly in a sensitive project built around a core authentication and authorization module. Development throughput was high. Reviews were fast. Exploratory spikes kept moving. The real question was not whether we were shipping fast, but whether we were validating the right things deeply enough.
The spike review process was too light for the risk surface.
That kind of gap rarely hurts during demo week. It hurts later, during validation, security review, or direct client scrutiny, when architectural weaknesses become expensive to hide and even more expensive to fix.
One subtle failure mode kept appearing: AI treats everything in the codebase as equally valid. It doesn’t understand which parts are actually alive, trusted, or safe to use.
We saw implementations built on top of dead code (e.g., inactive user activation paths), unused database tables, or the ignoring of multiple auth flows depending on feature flags.
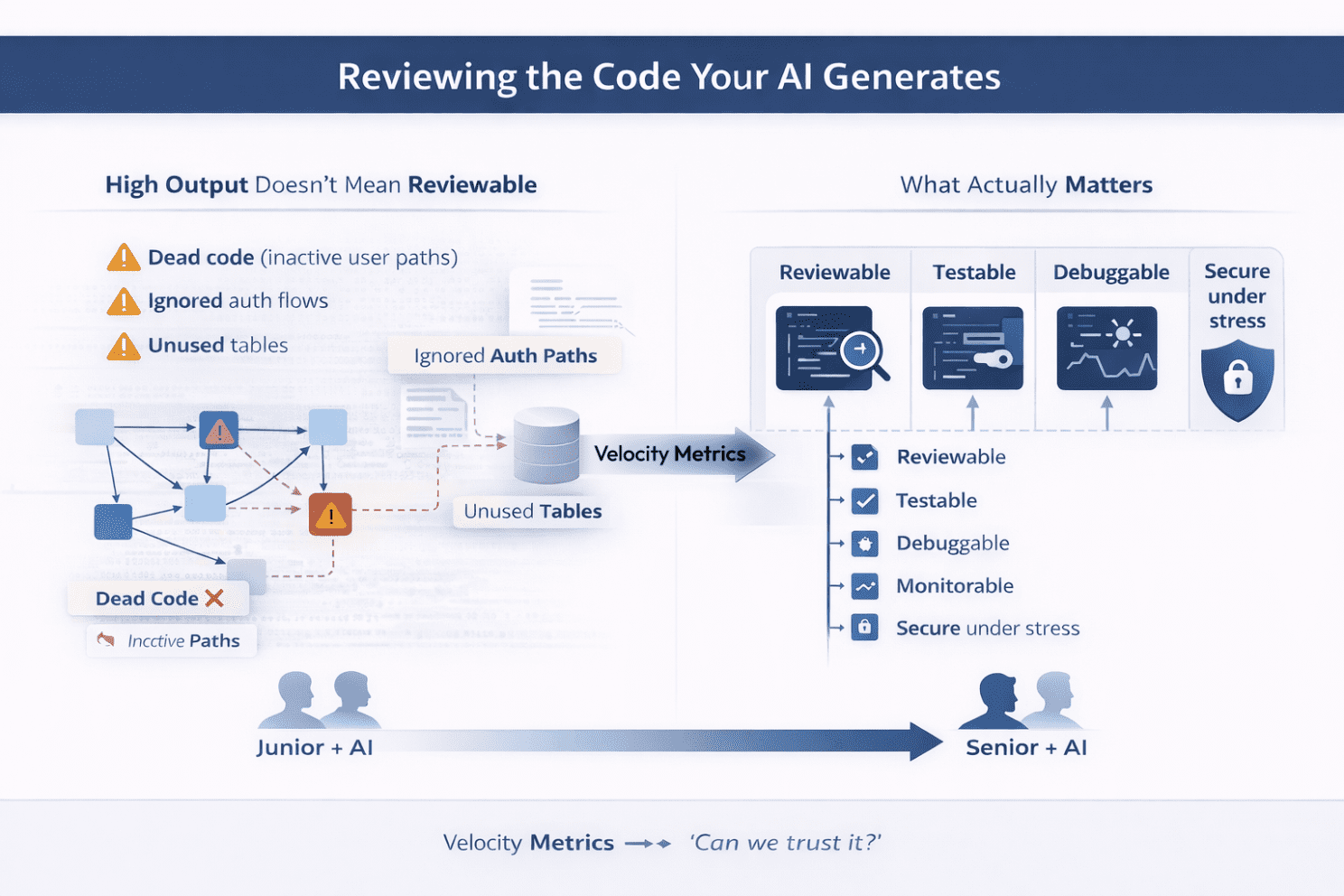
This is why velocity metrics used in isolation are weak proxies in AI-assisted teams. When code generation gets cheaper, output volume becomes meaningless. What matters is whether the system remains:
- reviewable,
- testable,
- debuggable,
- monitorable,
- secure under stress.
The split between senior + AI and junior + AI becomes sharper. One uses AI to remove toil while protecting design quality. The other can generate code, APIs, and abstractions faster than they can reason about them.
AI amplifies engineering maturity. It does not replace it.
That also changes what the review is about. It is no longer enough to review the diff. Teams need to review the design first: boundaries, invariants, trust model, rollback path, observability, and failure handling. AI can fill in a pull request. It cannot certify that the decomposition is sound.
Where Quality Actually Breaks in AI-Generated Systems
The interesting bugs are no longer in the scaffolding. They are at the boundaries.
With frameworks like FastMCP, it is now easy to get a server running quickly. Built-in middleware patterns cover much of the obvious cross-cutting work: caching, logging, rate limiting. The demo appears fast. The first version looks clean.
But the real engineering work starts one layer deeper:
- authentication quirks in the upstream API,
- pagination edge cases,
- partial failures and retries,
- timeout behavior,
- rate-limit handling,
- mapping messy upstream responses into stable tool outputs.
That is the part the agent has to live with in production. And that is where low-quality systems become excessively nondeterministic.
Build AI Systems That Hold Under Real Conditions

A tool that sometimes succeeds, sometimes times out, and sometimes invents a response shape is not a tool. It is operational debt with a nice interface.

This is why the upstream interaction layer deserves the most effort. Stable agentic systems need deterministic contracts: explicit retry policy, explicit timeout policy, stable error envelopes, predictable fallback behavior, and response shapes that do not drift under pressure.
The same applies to observability. In production MCP services, clear logging is non-negotiable. Middleware-level logging provides request/response visibility with minimal effort. Structured logging makes aggregation easier. But that is not enough on its own.
You also need domain logs:
- identifiers,
- decision points,
- upstream calls,
- retries,
- failure classes,
- fallback paths.
That combination is what makes incidents debuggable.
Logs explain what happened. Monitoring tells you when it is happening again. Without both, teams end up doing archaeology instead of engineering.
Building MCPs for Anthropic Life Sciences
Applying these rules is exactly what made our MCP Life Science servers for Anthropic work in production. The key lesson was that, in regulated environments, MCPs become security, compliance, and audit boundaries.
That changed what “quality” meant in practice:
- isolated containerized services,
- stateless execution,
- strict role-based access,
- observable infrastructure without storing PII,
- explainable error handling instead of raw API failures,
- and performance techniques like controlled caching to keep latency usable without sacrificing data integrity.
In healthcare and life sciences, architectures fail on weak boundaries, missing traceability, and systems that cannot prove compliance under scrutiny. That is why quality here is not polish added later — it is the architecture itself.
From Code Generation to Production Readiness: The Only Order That Works
The temptation in AI-heavy delivery is to start with generation.
- Let the model write the server.
- Let the assistant create the PR.
- Let the agent scaffold the integration.
- Let the benchmark come later.
- Let the monitoring wait until production.
A better order works more consistently.
Start with the foundations that determine quality later.
For the application layer, treat Twelve-Factor as the baseline checklist for portability and scale: config in the environment, stateless processes, clean build-release-run separation, dev/prod parity, logs as event streams, and easy horizontal scaling.
For the model and data layer, build the annotation workflow early: clear labeling guidelines, stable schema definitions, versioned datasets and labels, QA or consensus checks, and an audit trail.
This is not bureaucracy, but the ceiling on downstream quality.
In AI systems, poor annotation is the data equivalent of shallow code review: the defect is upstream, but the pain becomes visible only later.
The same discipline applies to implementation choices.
Implementation Choices: Open Source or Custom in Enterprise AI Systems?
Less tech-mature organizations still waste time rebuilding complex infrastructure from scratch instead of starting with proven open-source components. They create custom skill frameworks, custom orchestration layers, custom middleware, and custom plumbing — then discover they produced long-term maintenance overhead rather than meaningful differentiation.
The real leverage is not in avoiding customization, but in customizing the right layer.
Use proven components as the foundation, then tailor how they are connected, constrained, orchestrated, and aligned to the specific business problem. That is where custom work creates real value – not in rewriting commodity infrastructure, but in shaping reliable systems around the use case that actually matters.
Case study:
For instance, in a recent advisory project for one of the leading U.S. industrial manufacturers, we evaluated an internally developed agentic system for retrieving information across multiple departments. While the system had been built from scratch, it faced several limitations – including unreliable human-in-the-loop workflows and a lack of support for parallel tool execution across sub-agents. Following our recommendations, the solution was rebuilt using the OpenAI Agents SDK, resulting in a significantly more robust, scalable, and maintainable system.
And we keep seeing the pattern: teams try to invent sophisticated mechanisms before they have stabilized the actual tool contracts, integration behavior, or review standards. That sequencing is upside down.
The better rule is simpler: Borrow complexity before you build it. Use established components first. Extend only where the extension creates real leverage.
A practical sequence looks like this:
proven components -> Twelve-Factor baseline -> annotation and versioning discipline -> AI-assisted implementation -> tests, review, logging, and monitoring -> staged rollout
That sequence prevents teams from speeding in the wrong direction.
From Prototype to Compliant AI Systems
Demos Are Not Enterprise Systems: Why Production AI Needs More Than Speed
This is where the gap between prototypes and production becomes obvious.
Fun projects are easy. They are fast to set up, permissive by default, impressive in demos, and often surprisingly capable. They make AI feel magical by optimizing for the happy path.
Enterprise systems optimize for everything the happy path ignores:
- approvals,
- policy boundaries,
- auditability,
- replayability,
- tenant isolation,
- failure recovery,
- on-call debuggability.
That is the real difference between something enjoyable to show and something safe to run.
Prototypes are easy because they can ignore these constraints. Production systems cannot.
This is also why the most useful position is between the two current extremes. The first extreme says AI can now replace most of the engineering discipline, so speed is the only thing left to optimize. The second says AI-generated code is inherently unserious, so the safest move is to reject it altogether.
Both miss the point.
The practical middle is better:
Use AI aggressively for scaffolding, repetitive implementation, refactoring, and code assistance. Slow down hard at design review, code review, tests, monitoring, and security boundaries.
Fun projects optimize for wow. Enterprise systems optimize for accountability.
The Payoff: From Output Volume to System Reliability
Teams that get this right do not become slower. They become harder to surprise.
They still benefit from code assistance. They still ship faster. But their speed compounds instead of backfiring, because the quality gates are doing real work.
So, what to do?
- Use AI to compress mechanical implementation, not to bypass design.
- Stop treating PR volume or lines changed as proof of progress.
- Put stricter review standards around security-critical paths such as authentication, authorization, and core business rules.
- Make logging and monitoring first-class from day one.
- Build on proven components, and bake portability, annotation quality, and auditability in early.
Less time is now spent writing code by hand. More time is spent deciding what deserves to stay.
When code gets cheaper, judgment gets more precious.
Table of contents