The caching system significantly reduces costs by eliminating redundant LLM calls, especially in reasoning-heavy workflows. It enables fast, low-overhead replay of agentic sequences and consistent regeneration of outputs.
Meet our client

Client:

Industry:

Market:

Technology:
Client’s Challenge
Generative AI projects—especially MVPs, PoCs, and production systems—often repeat model generations due to batch inference, test case re-runs, or duplicated prompts across teams. This leads to unnecessary compute usage, higher token costs, and wasted developer time. However, implementing caching in early-stage or ongoing projects is difficult due to time constraints and codebase complexity. Existing solutions often require heavy integration and work only in narrow, pre-defined setups.
Our Solution
We developed a lightweight, plug-and-play caching library designed for LLMs and generative models across modalities (text, image, etc.). With a single import, developers can enable caching in arbitrary codebases—even those with deeply nested modules. The library supports models from both external APIs (like OpenAI) and local deployments, including integration with Transformers, Diffusers, and LiteLLM. The backend uses a custom setup with SQLAlchemy and flexible storage solutions for both observability and cache persistence.
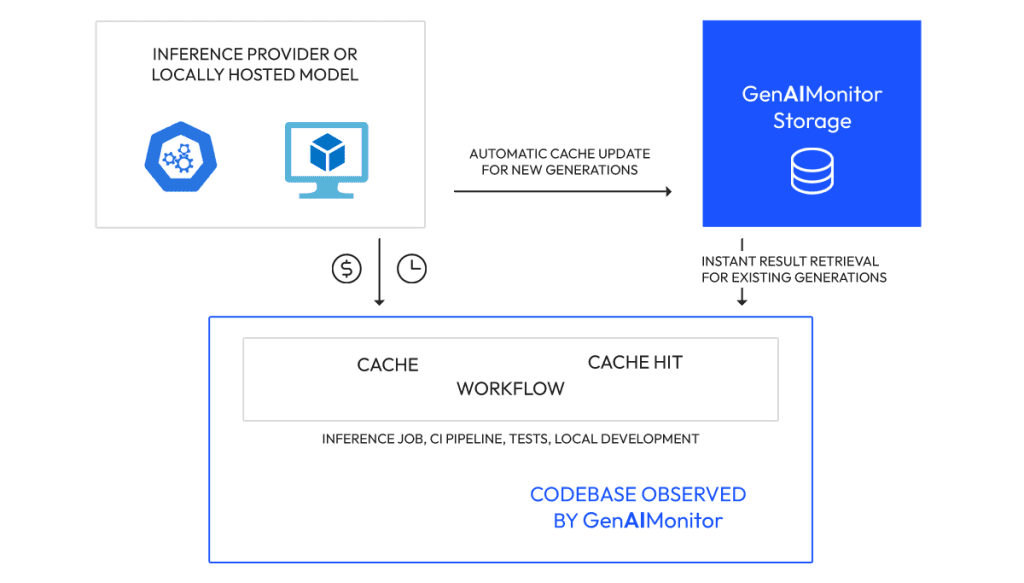
Client’s Benefits
The caching system significantly reduces costs by eliminating redundant LLM calls, especially in reasoning-heavy workflows. It enables fast, low-overhead replay of agentic sequences and consistent regeneration of outputs. With one-line integration and built-in observability, it streamlines experimentation at scale.





