
Table of contents
Living in a world of big data comes with a certain challenge. Namely, how to extract value from this ever-growing flow of information that comes our way. There are a lot of great tools that can help us, but they all require a lot of resources. So, how do we ease the burden on this CPU/RAM demand? One way to do it is to share the data we are working on and the results of our computations with others.
Table of contents
Imagine a team of data scientists working on a problem. Each of them attacks the problem from a different angle and tries various techniques to tackle it. But what they all have in common is the data lying at the base of the problem. So, why should this data be instantiated multiple times in cluster memory? Why shouldn’t it be shared between all team members? Furthermore, when someone on the team makes an interesting discovery about the data, they should be able to share their results with others instantly so that everyone can benefit from the new insight.
The Solution
Technologies
The IPython notebook is a well-known tool among the data science community. It serves both as a great experimentation tool and research documentation device. On the other hand, Apache Spark is a rising star in the Big Data world, that already has a Python API. In this post we’ll show how combining these two great pieces of software can improve the data exploration process.
Simple data sharing
Let’s run a simple Spark application (in our heads, for now – it’s far easier to debug and compile times are awesome) that reads a CSV file into a DataFrame (Spark’s distributed data collection). This DataFrame is large – several gigabytes, for example (or any number that You feel is noticeable across the cluster). How can we share this DataFrame between multiple team members? Let’s think of our application as a server. A server can handle multiple clients and act as a “hub”, where shared state is stored.

Luckily for us, Spark is well prepared for such a use case. Its Python API uses a library called Py4J that acts as a proxy between Python code and the JVM-based core. Internally, Py4J works like this: the JVM process sets up a Gateway Server which listens on incoming connections and allows calling methods on JVM objects via reflection. On the other side of the communication pipe, Py4J provides Java Gateway, a Python object that handles “talking” to the Gateway Server and exposes objects imitating those in the JVM process.
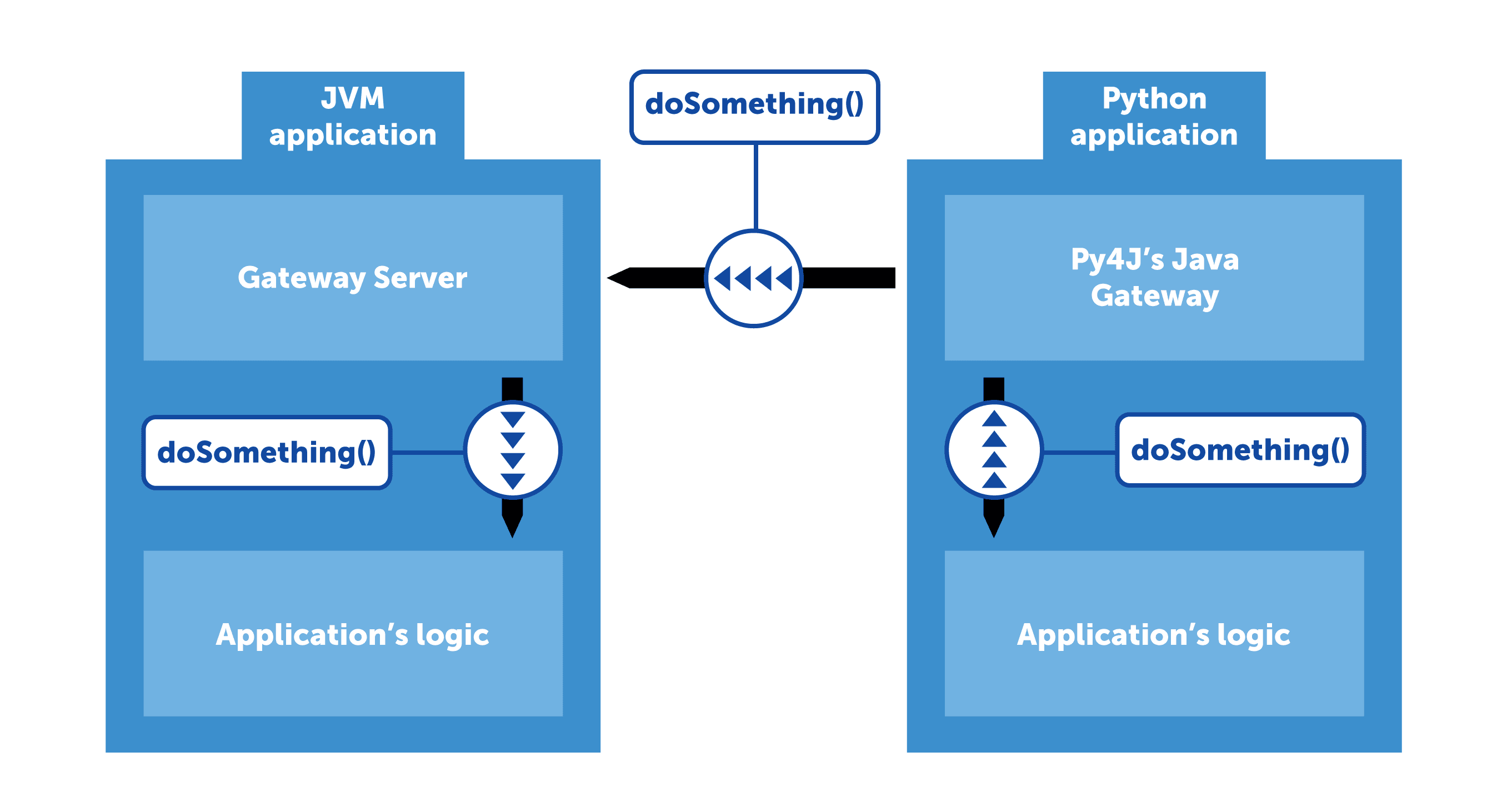
Let’s quickly add this functionality to our imaginary application. By now it has read our big DataFrame and exposed a server to which we can connect and perform operations on JVM objects. But on which objects exactly? We can’t just say “let’s do a .select() on that DataFrame”. That’s why Py4J allows us to define the Entry Point: an object proxied to Python side by default. Let’s put our DataFrame in this object and define an access method that returns it. Now, anyone that connects to our Gateway Server can use the DataFrame without it being duplicated in cluster’s memory.
Scala code
class MyEntryPoint() {
def getDataFrame(): DataFrame = // ...
// ...
}
Python code
java_gateway = JavaGateway(GatewayClient(address='localhost', port=8080),
auto_convert=True)
java_gateway.entry_point.getDataFrame().select(“my_column”).toDF().show()
Sharing results
We’ve managed to convince our Spark application to serve a DataFrame. But when we build another DataFrame, we’d like other users to be able to access it. Let’s add a collection of DataFrames to our Entry Point. For simplicity, let it be a String → DataFrame map. Whenever we want to share our results with other team members, we just need to append a new mapping to the collection: “my new result” → DataFrame. Now, anyone can access the map and see what we’ve done. Just remember to stay thread-safe :).
Scala code
class MyEntryPoint() {
def getDataFrame(id: String): DataFrame = // ...
def saveDataFrame(id: String, dataFrame: DataFrame) = // ...
// ...
}
Extensions Using this core functionality, it’s now easy to think of possible improvements like
- user management, each user having their own namespace, being able to share what they want with only selected colleagues
- notifications: “Look, John published a new result!”
- sharing more than just data: any JVM object can be shared this way, provided it’s immutable (mutable objects can be shared as well, of course, but for obvious reasons it’s best to avoid that if possible)
Of course, this is only a taste of what can be achieved using this technique. Please let us know if you come up with an interesting application for it.
Putting it all together
Below is an outline of how to set up both JVM (Scala) and Python side of the above solution. Your Spark application should basically run in an infinite loop. In order to control it better, you could add some custom methods to the Entry Point like “shutdown application”, but it’s not mandatory.
Scala code
class MyEntryPoint() {
def getDataFrame(id: String): DataFrame = // ...
def saveDataFrame(id: String, dataFrame: DataFrame) = // ...
// ...
}
val gatewayServer = new GatewayServer(new MyEntryPoint(), 8080)
gatewayServer.start()
Python code
java_gateway = JavaGateway(GatewayClient(address='localhost', port=8080),
auto_convert=True)
selected = java_gateway.entry_point.getDataFrame("my DataFrame").select(“my_column”).toDF()
java_gateway.entry_point.saveDataFrame(“my new shiny DataFrame”, selected._jdf)
The last line contains a reference to protected _jdf member of DataFrame object. While this is a bit unorthodox, it’s used here for simplicity. The _jdf object is Py4J’s proxy to the corresponding JVM DataFrame object. An alternative implementation requires us to share Spark’s SQLContext over Py4J connection and registering our output DataFrame as a temporary table.






