
Table of contents
Table of contents
We’re thrilled today to announce the latest version of Neptune: Machine Learning Lab. This release will allow data scientists using Neptune to take some giant steps forward. Here we take a quick look at each of them.
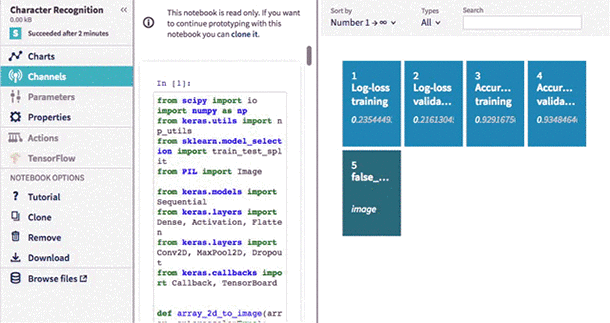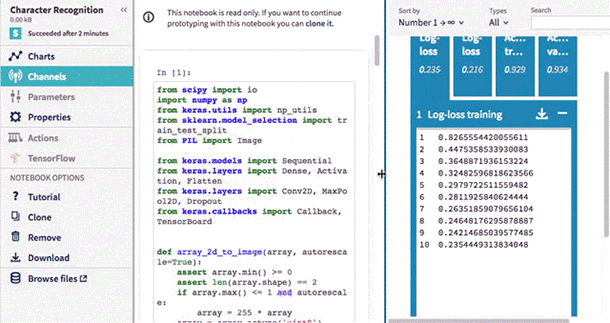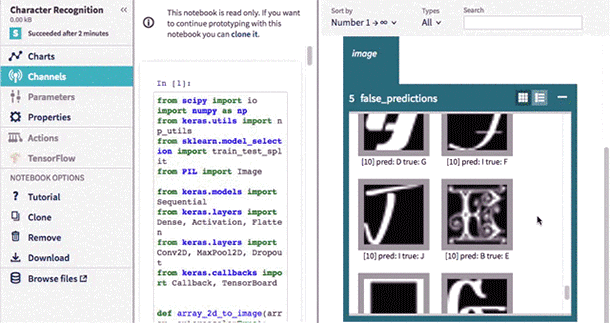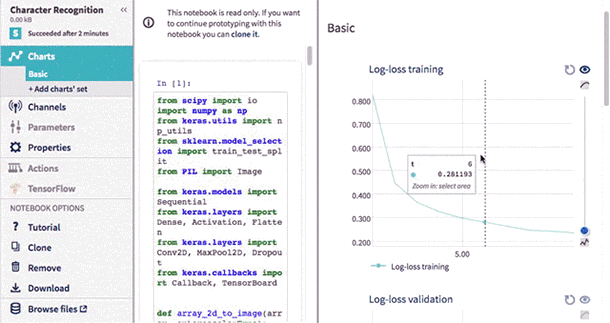
 You can also edit the name, tags and notes directly in the table and display metadata including running time, worker type, environment, git hash, source code size and md5sum.
You can also edit the name, tags and notes directly in the table and display metadata including running time, worker type, environment, git hash, source code size and md5sum.
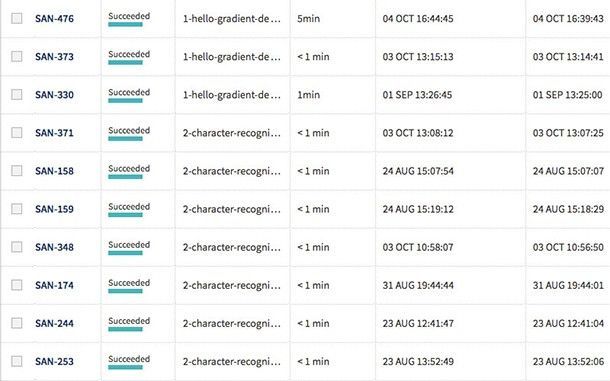
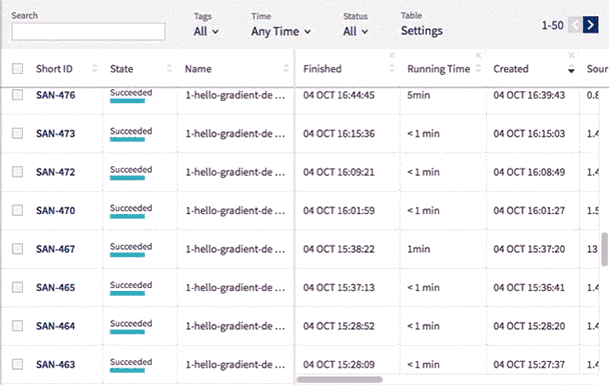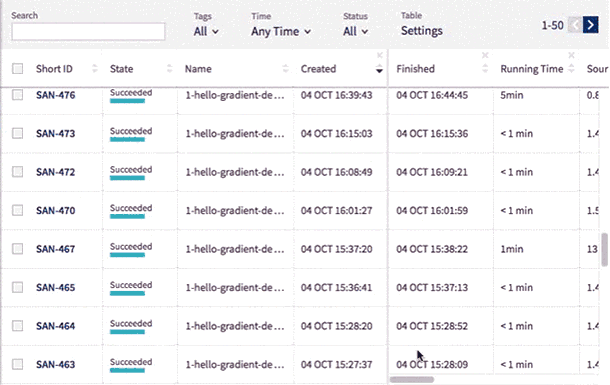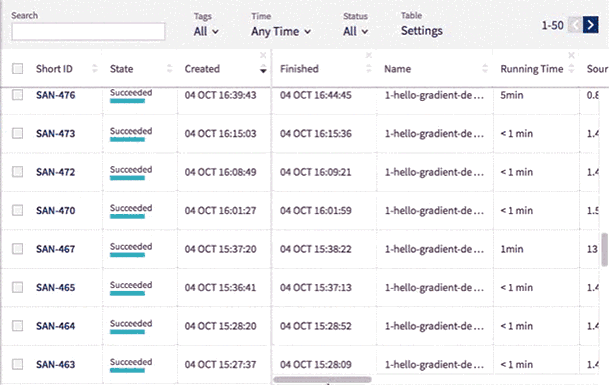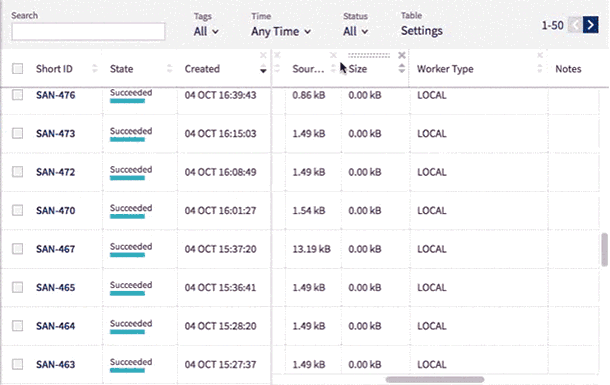
 The experiments are now presented with their Short ID. This allows you to identify an experiment among those with identical names.
The experiments are now presented with their Short ID. This allows you to identify an experiment among those with identical names.
 Sometimes you may want to see the same type of data throughout the entire project. You can now fix chosen columns on the left for quick reference as you scroll horizontally through the other sections of the table.
Sometimes you may want to see the same type of data throughout the entire project. You can now fix chosen columns on the left for quick reference as you scroll horizontally through the other sections of the table.
 The new parameter syntax supports grid search for numeric and string parameters:
The new parameter syntax supports grid search for numeric and string parameters:
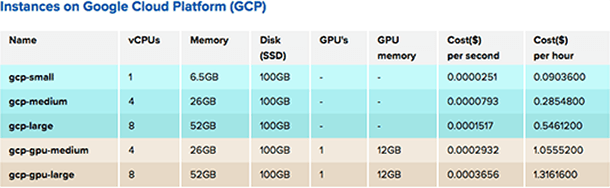
Cloud support
One of the biggest differences between Neptune 1.x and 2.x is that 2.x supports Google Cloud Platform. If you want to use NVIDIA® Tesla® K80 GPUs to train your deep learning models or Google’s infrastructure for your computations, you can just select your machine type and easily send your computations to the cloud. Of course, you can still run experiments on your hardware the way it was. We currently support only GCP–but stay tuned as we will not only be bringing more clouds and GPUs into the Neptune support fold, but offering them at even better prices! With cloud support, we are also changing our approach to managing data. Neptune uses shared storage to store data about each experiment, for both the source code and the results (channel values, logs, output files, e.g. trained models). On top of that, you can upload any data to a project and use it in your experiments. As you execute your experiments, you’ve got all your sources at your fingertips, in the /neptune directory, which is available on fast drive for reading and writing. It is also your current working directory – just like you would run it on your local machine. Alongside this feature, Neptune can still keep your original sources so you can easily reproduce your experiments. For more details please read documentation.
Interactive Notebooks
Engineers love how interactive and easy to use Notebooks are, so it should come as no surprise that they’re among the most frequently used data science tools. Neptune now allows you to prototype faster and more easily using Jupyter Notebooks in the cloud, which is fully integrated with Neptune. You can choose from among many environments with different libraries (Keras, TensorFlow, Pytorch, etc) and Neptune will save your code and outputs automatically.
New Leaderboard
Use Neptune’s new leaderboard to organize data even more easily. You can change the width of all columns and reorder them by simply drag and dropping their headings.
You can also edit the name, tags and notes directly in the table and display metadata including running time, worker type, environment, git hash, source code size and md5sum.
The experiments are now presented with their Short ID. This allows you to identify an experiment among those with identical names.
Sometimes you may want to see the same type of data throughout the entire project. You can now fix chosen columns on the left for quick reference as you scroll horizontally through the other sections of the table.
Parameters
Neptune comes with new, lightweight and yet more expressive parameters for experiments. This means you no longer need to define parameters in configuration files. Instead, you just write them in the command line! Let’s assume you have a script named main.py and you want to have 2 parameters: x=5 and y=foo . You need to pass them in the neptune send command:neptune send -- '--x 5 --y foo'Under the hood, Neptune will run python main.py –x 5 –y foo , so your parameters are placed in sys.argv . You can then parse these arguments using the library of your choice. An example using argparse :
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--x', type=int)
parser.add_argument('--y')
params = parser.parse_args() # params.x = 5, params.y = 'foo'
If you want Neptune to track a parameter, just write ‘%’ in front of its value — it’s as simple as that!
neptune send -- '--x %5 --y %foo'The parameters you track will be displayed on the experiment’s dashboard in the UI. You will be able to sort your experiments by parameter values.
The new parameter syntax supports grid search for numeric and string parameters:
neptune send -- '--x %[1, 10, 100] --y %(0.0, 10.0, 0.1)' neptune send -- '--classifier %["SVM", "Naive Bayes", "Random Forest"]'You can read more about the new parameters in our documentation.





