
Table of contents
Generating images from text has been a subject of rapid development as it might provide significant enhancements for the solutions across various domains. This text describes a complete framework that allows text-to-image conversion by combining several machine learning solutions.
Table of contents
Accurately generating images from text (and vice versa) has been a major challenge for both natural language processing and computer vision. Recent publications, including the release of OpenAI’s DALL-E model early this year, have proved that when large enough datasets are used for training, it is possible to generate high-quality images from arbitrary text, reliably conveying the semantics of input. The large surge in development that has been occurring makes this topic very interesting, from both a scientific and business perspective. This text describes a complete framework that allows text-to-image conversion by combining several machine learning solutions. Generating images from text has been a subject of rapid development as it might provide significant enhancements for the solutions across various domains, such as fashion or architecture. Apart from improving the abilities of recommendation systems, it also makes generating synthetic datasets much easier for a vast field of computer vision applications, such as facial recognition-based tasks.

Overview of the Framework
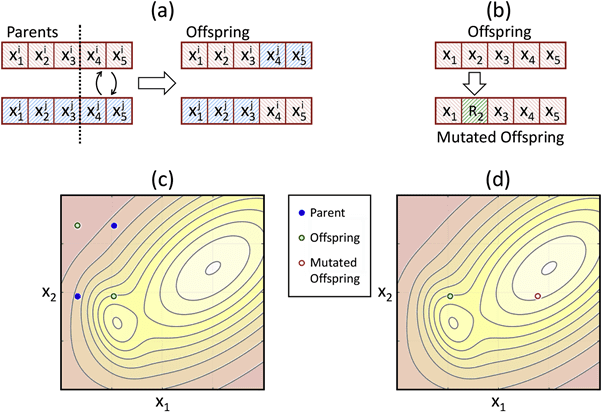
The framework used in this solution consists of three important components: a pre-trained generative network, a CLIP model, and an evolutionary algorithm loop. The generative network is the core of the solution. Quality, variety, and the domain of generated images are all greatly influenced by the choice of model. The predictive power of the model within a certain latent space area is dependent on the underlying dataset used during the training process. In a nutshell, CLIP can be perceived as a mapping between two spaces – one with encodings of text snippets and the other with encodings of images. The whole model was trained on an enormous dataset consisting of 250 million text-image pairs, mostly scraped from the web. Evolutionary algorithms are population-based heuristic optimization methods. Algorithms from this family use computational implementations of processes related to natural selection, such as crossover, mutation, and reproduction. The algorithm is based on the survival of the fittest principle, where the main objective is to generate more and more fit members of the population while reducing the number of weak units.
These three parts can be used to create a pipeline that enables a batch of images corresponding to an input text snippet to be generated.
How does it work?
The solution is based on the input text provided by the user. It is encoded by the CLIP model and will be used repeatedly in unchanged form as the reference in the optimization loop. The first population of images is generated by using a randomized latent vector (noise) and passing it through the generative network. The quality of the population is assessed by the fitness function, which compares the encoded text snippet provided by the user with each image in the batch.
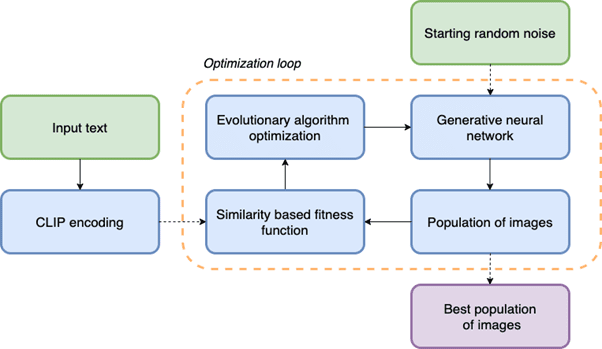
The role of the evolutionary algorithm is to use the current population to generate new units that will reflect the input text more accurately. After each algorithm step, a new batch of images is generated and the loop repeats until it converges or is stopped. The final population of images is the framework’s output. The whole solution is possible thanks to the continuity of latent spaces, which can be traversed in search of the best solution. For instance, the latent space for the StyleGAN2-car model (trained on the large dataset of car images) is generated by 512-dimensional vectors with values ranging from -10 to 10. The first population of images generated by the phrase a yellow car in the city is presented below. The result is a bunch of cars, but they are chosen at random – created by a randomized initial vector.

After 200 iterations, the genetic algorithm arrives at a population of vectors that correspond to the below images.

The genetic algorithm was able to alter the initial population of vectors to reach the area of latent space that provides information about the yellow color and the city to the generator – hence these attributes are seen in the images. These images make the framework’s abilities and potential clear. But this is only a start. Work in deep learning is expected to lead to more versatile, robust and widely applicable solutions. These may include simulations and find application in a wide range of industries, including gaming, entertainment, interior design and urban infrastructure planning, to name a few.





