
Table of contents
Turns out a walk in the park is not so simple after all. In fact, it is a complex process done by controlling multiple muscles and coordinating who knows how many motions. If carbon-based lifeforms have been developing these aspects of walking for millions of years, can AI recreate it?
Table of contents
This blog will describe:
- How reinforcement learning works in practical usage
- The process used to learn the model
- Challenges in reinforcement learning
- How knowledge is transferred between neural networks and why it is important for the development of artificial intelligence
Moving by controlling the muscles attached to bones, as humans do it, is way more complicated and harder to recreate than building a robot that can move with engines and hydraulic cylinders. Building a model that can run by controlling human muscles recreated in a simulated environment was the goal of a competition organized at the NIPS 2017 conference. Designing the model with reinforcement learning was a part of a scientific project that could potentially be used to build software for sophisticated prostheses, which allow people to live normally after serious injuries.
Software that understands muscle-controlled limb movement would be able to translate the neural signals into instructions for an automated arm or leg. On the other hand, it may also be possible to artificially stimulate the muscles to move in a particular way, allowing paralyzed people to move again.
Why reinforcement learning
Our RL Agent had to move the humanoid by controlling 18 muscles attached to bones. The simulation was done in an OpenSim environment. Such environments are used mainly in medicine to determine how changes in physiology are going to affect a human’s ability to move. For example, if a patient with a shorter tendon or bone will still be able to walk or grab something with his hand. The surprising challenge was the environment itself – OpenSims require a lot of computational power.
Building hard-coded software to control a realistic biomechanical model of a human body would be quite a challenge, even if researchers from Stanford University have done just that. But training a neural network to perform this task proved to be much more efficient and less time-consuming, and didn’t require biomechanical domain specific knowledge.
Run Stephen! Run!
Our reinforcement learning algorithm leverages a system of rewards and punishments to acquire useful behaviour. During the first experiments, our agent (whom we called Stephen)randomly performed his actions, with no hints from the designer. His goal was to maximize the rewards involved by learning which actions, done randomly, yielded the best effect. Basically, the model had to figure out how to walk over the course of a few days, a much shorter time than the few billion years it took carbon-based lifeforms.
In this case, Stephen got a reward for every meter he travelled. During the first trials, he frequently fell over, sometimes forward, sometimes backward. With enough trials, it managed to fall only forward, then to jump or take its first step.
The curriculum, or step-by-step learning
After enough trials, Stephen learned that jumping forward is a good way to maximize the future reward. As a jumper, he was not that bad – he got from point A to point B by effectively controlling his muscles. He didn’t fall and was able to move quickly.
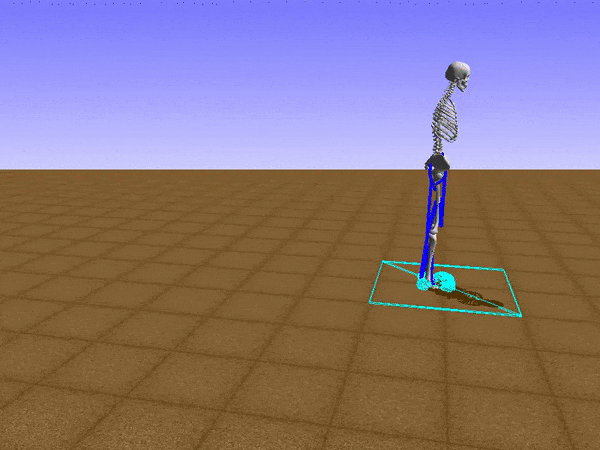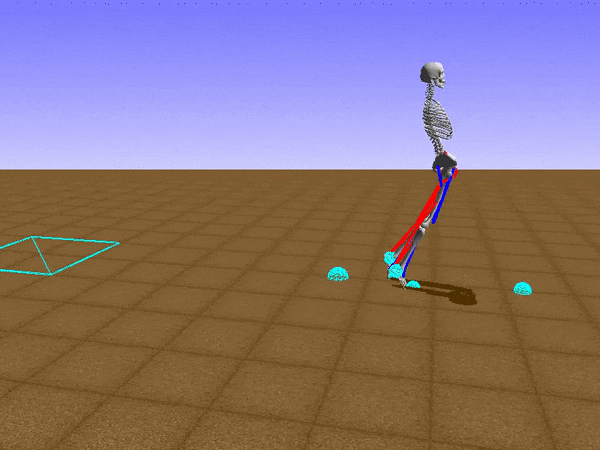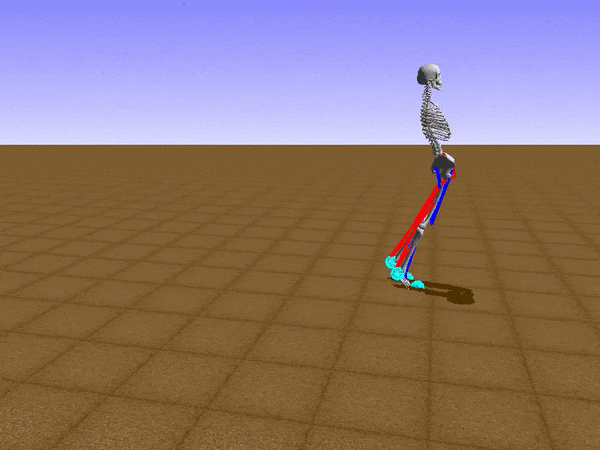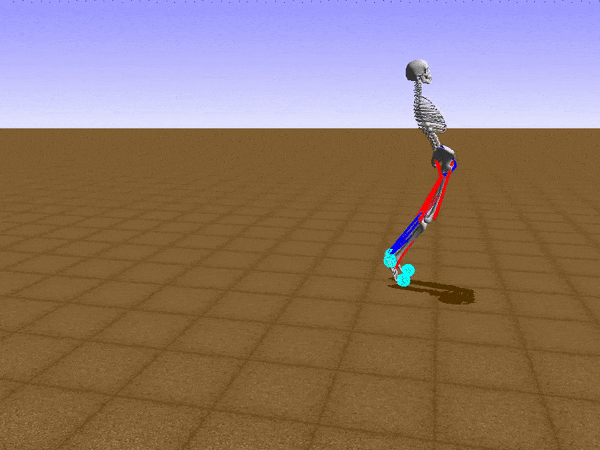
But our goal for Stephen was not “learning to hop”- it was “learning to run”. Jumping was a sub-optimal form of locomotion.
This prompted the need for a curriculum, or, in other words, a tutoring program. Instead of training Stephen to avoid obstacles and run at the same time, we would teach him progressively harder skills – first to walk on a straight road, then to run and, finally, to avoid obstacles. Learn to walk before you run, right?
To reduce his tendency to jump and instead find a way to walk, we had to get Stephen to explore different options such as moving his legs separately. We opted to use a relatively small neural network that would be able to learn to walk on a path without any obstacles. He succeeded at this, but during the process, he had a Jon Snowesque problem with his knee.
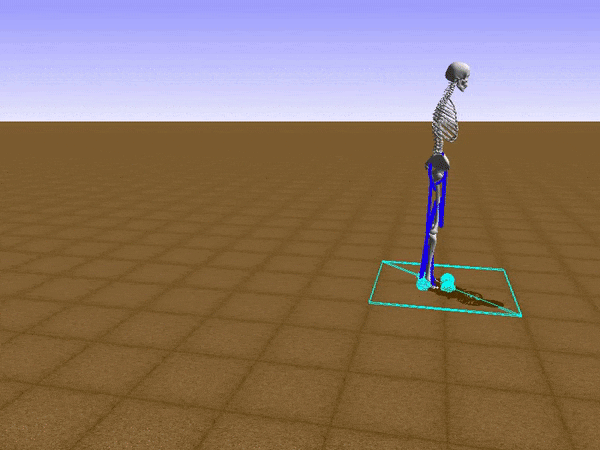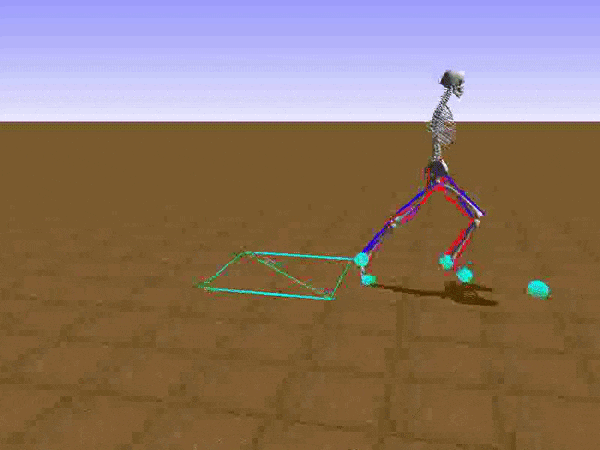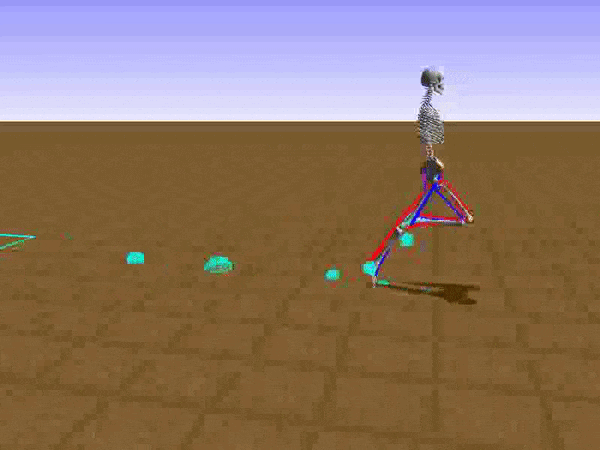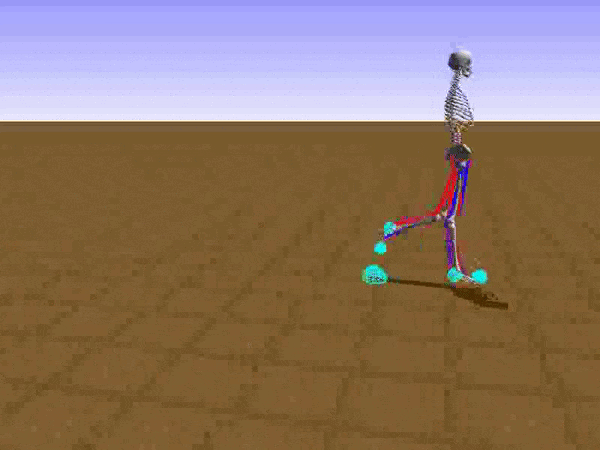
Anyone who has ever aspired to sports stardom will remember a coach admonishing them to bend their knees. Apparently, the failure to do so is common among all walkers, including simulated ones controlled by an artificial neural network. Reshaping the reward function was the only way to communicate with the agent. As the human creators, we of course know just what walking should look like, but the neural network had no clue. So adding an award for Stephen for bending his knees was a good way to improve his performance and find a better policy.
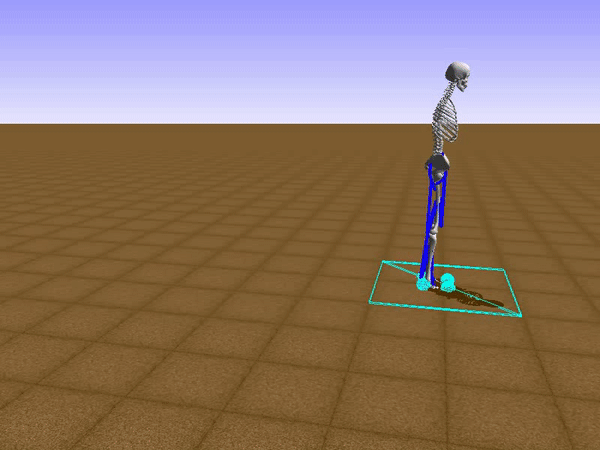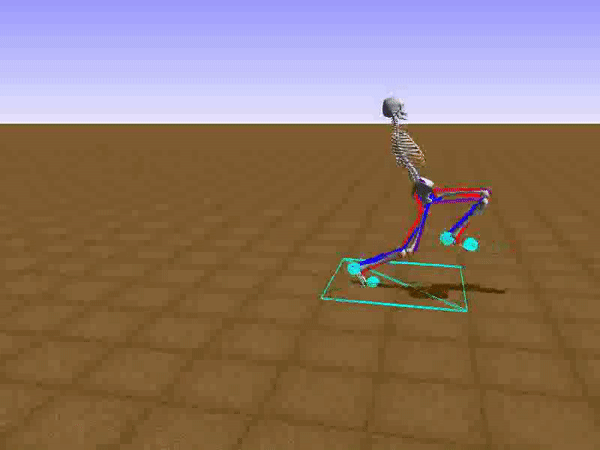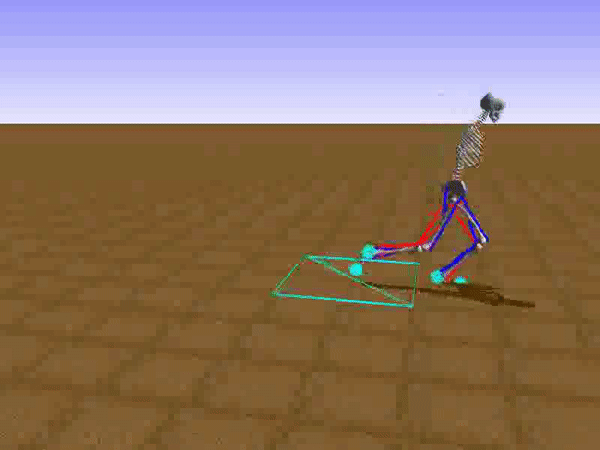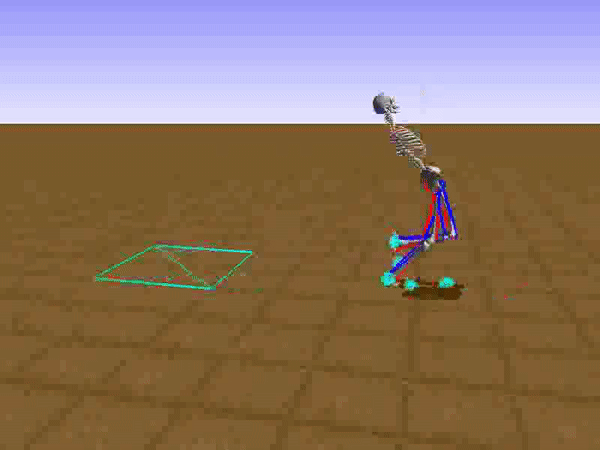
If any human had his walk from that moment, it would be wise to apply for a government grant to develop it.
When Stephen finally worked out how to walk and run effectively, we added another, bigger neural network to figure out how to avoid obstacles. At that point, one neural network was controlling the running process while the second one figured out how to tweak Stephen’s movement to avoid obstacles and not fall.
This is a novel technique which we called policy blending. The usual way to make a neural network bigger and teach it new skills is behavioral cloning, which is a machine learning interpretation of the master-apprentice relation. The new, bigger deep neural network watches how the smaller one performs its tasks.
For this task, our method of policy blending has been outperforming behavioural cloning. For further information, please read a scientific paper we contributed to. It presents interesting ideas employed during the challenge. After Stephen learned how to move and avoid rocks in his way, we blended another neural network encouraging him to run even faster.
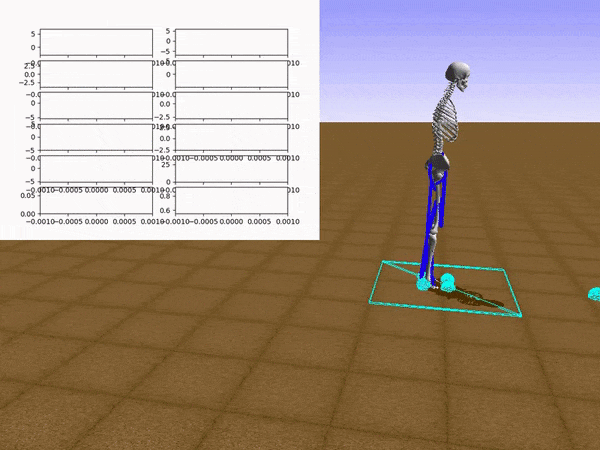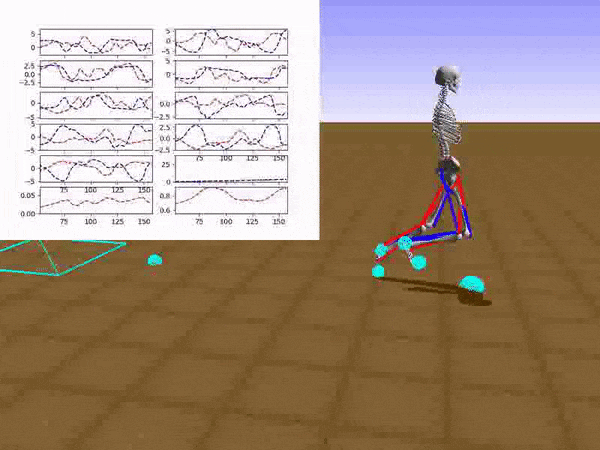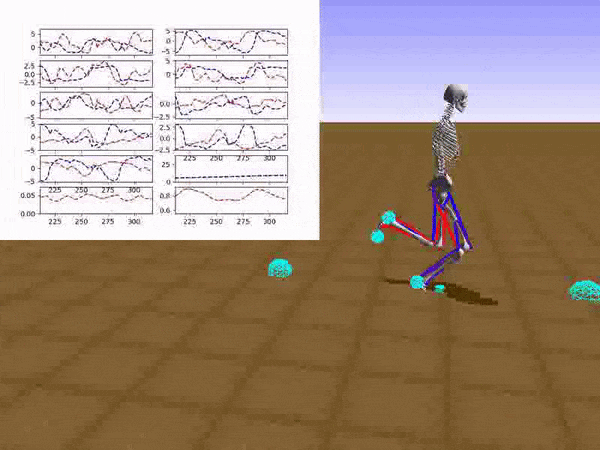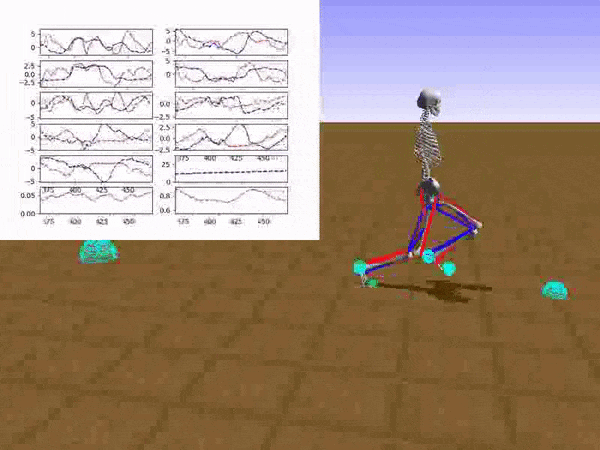
With policy blending and enough computational power, Stephen managed to run in a human way without falling. With 10 random obstacles to navigate, Stephen fell in less than 8% of trials. When he was moving more carefully (about 20% slower), the falls ratio fell (pardon the pun) to below 0.5%.
After the run – the effects of reinforcement learning
The experiment brought a few significant outcomes.
First, it is possible for a computer to perform the tremendously complicated task of walking with separate and coordinated control of the muscles. The agent was able to figure out how to do that using reinforcement learning alone – it did not need to observe human movement. Moreover, the policy blending method proved effective and outperformed the standard behaviour cloning approach. Although it is not certain that it will be more efficient in every possible case, it is another, sometimes better way to transfer knowledge from one trained network to another.
Finally, we handled the resource-demanding environment by effectively splitting the computations between nodes of a large cluster. So even within the complex and heavy simulator, reinforcement learning may be not only possible, but effective.





