
Table of contents
In recent years, we have seen rapid development in the field of artificial intelligence, which has led to increased interest in areas that have not often been previously addressed. As AI becomes more and more advanced, beyond model effectiveness, experts are being challenged to understand and retrace how the algorithms came up with their results, and how the models are reasoning and why [Samek and Muller, 2019].
Table of contents
Introduction
Such knowledge is necessary for many reasons: one is ensuring that the AI-driven solutions comply with regulations, particularly in finance. Another reason is a better understanding of how a model works, which translates into reducing errors and anticipating the strengths and weaknesses of the model, as well as avoiding unexpected behavior already in production. And last, but not least, it allows for the creation of models that are inclusive and eliminate the impact of social biases which can appear in the training data. The use of explainable AI (xAI) translates into increased trust and confidence when deploying an AI-powered solution.
The need for an explanation of AI models is especially noticeable in natural language processing tasks. A common part of many solutions in this domain is the use of vector representations of words. As it turns out, these representations also model human biases that are found in the data. Examples of such biases include: gender bias, racial bias, or social bias towards people with disabilities [Hutchinson et al., 2020].
Categorization of Explanations
The approaches used in explainable artificial intelligence can be divided in several ways. Some of the most functional in both practice and science are the divisions by what is being explained and by at which stage of model usage the explanation is happening.
The first one tells us what we are explaining:
- local explanation – presents an explanation of one particular decision, e.g. by showing which words in the input example were important
- global explanation – shows the entire model’s behavior. In this article, we focus on local methods.
The second possible split is based on how the explanation is created:
- explanation by design – the models that are intrinsically explainable, like decision trees
- post-hoc explanation – the model is a black-box; however, with post-processing methods it is possible to determine how the decision was made
This taxonomy allows us to organize and characterize the available methods.
Methods walk-through
LIME and SHAP
Let me start by describing the LIME [Ribeiro et al., 2016] and SHAP [Lundberg and Lee, 2017] AI explanation methods, which are examples of post-hoc local explanation algorithms. The idea behind LIME is to create a simpler, interpretable model that approximates the behavior of a complex model in the neighborhood of the analyzed example, and is visualized in the picture below:
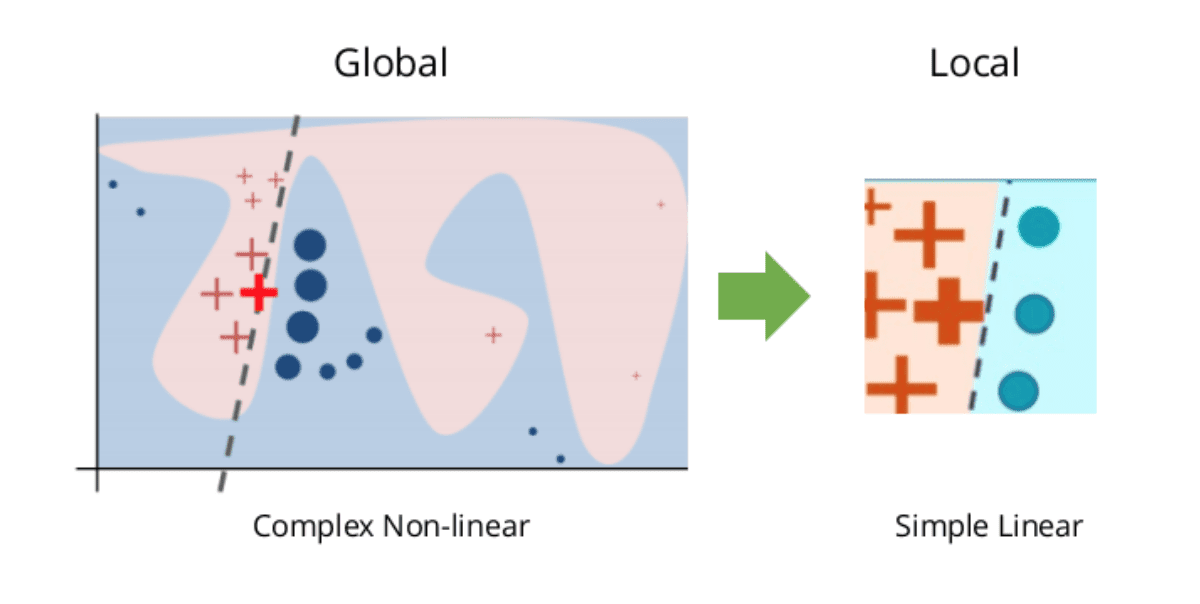
The simpler model is trained on the data coming from the perturbations of the input data, where the ground truth is the result returned by the complex model. In the case of textual data, perturbations are usually made by removing words from the analyzed example. SHAP, on the other hand, leverages game theory and using Shapley Values determines the importance of perturbed examples.
They are very handy to use as they can work with any black-box model and with most data types. Another reason for the growing popularity of this approach is the great SHAP library (https://github.com/slundberg/shap) which is easy to use and provides well designed visualizations. Below, we can see an example of an explanation from SHAP documentation presenting why the model predicted the sentiment of a movie review to be positive.
Firstly, we initialize the pretrained model from Huggingface for predicting sentiment:

Next, we import the SHAP library and initialize the model explainer as well as give it an example to predict and analyze:

Finally, we use the visualization module to transform the resulting values into a graph showing the marginal contribution of each word (in simplified terms, we can think of this as feature importance):

And the result is presented below:

We can see here that the phrase ‘great movie’ had the highest contribution to predicting the phrase as positive and the model was unable to capture the sarcasm.
Unfortunately, no approach is without its flaws. Researchers point out that an explanation actually comes from another model, which may have fidelity problems in reproducing the actual model.
Gradient-based explanations
Another group of approaches used in explaining NLP model predictions are methods that analyze the gradient appearing in a neural network. More precisely, they analyze the change of the selected decision class with respect to the input example. Since one backward pass is enough to create a saliency map, and they do not use a surrogate model, they are free of the problem that plagued the perturbation approaches because they analyze the model explicitly.
A great tool that allows simultaneous decision analysis using multiple gradient approaches (and also the LIME algorithm described earlier) is LIT – Language Interpretability Tool (https://pair-code.github.io/lit). It also provides a comprehensive analysis of the model and dataset. The concept of this tool is a little different from SHAP. It works as a standalone web service, which can also be run in Jupyter Notebook.
Below, you can see the script that loads the dataset together with a pretrained model and runs the service in Jupyter Notebook:

We run the same example as in the SHAP section. The outcome is presented in figure 3:
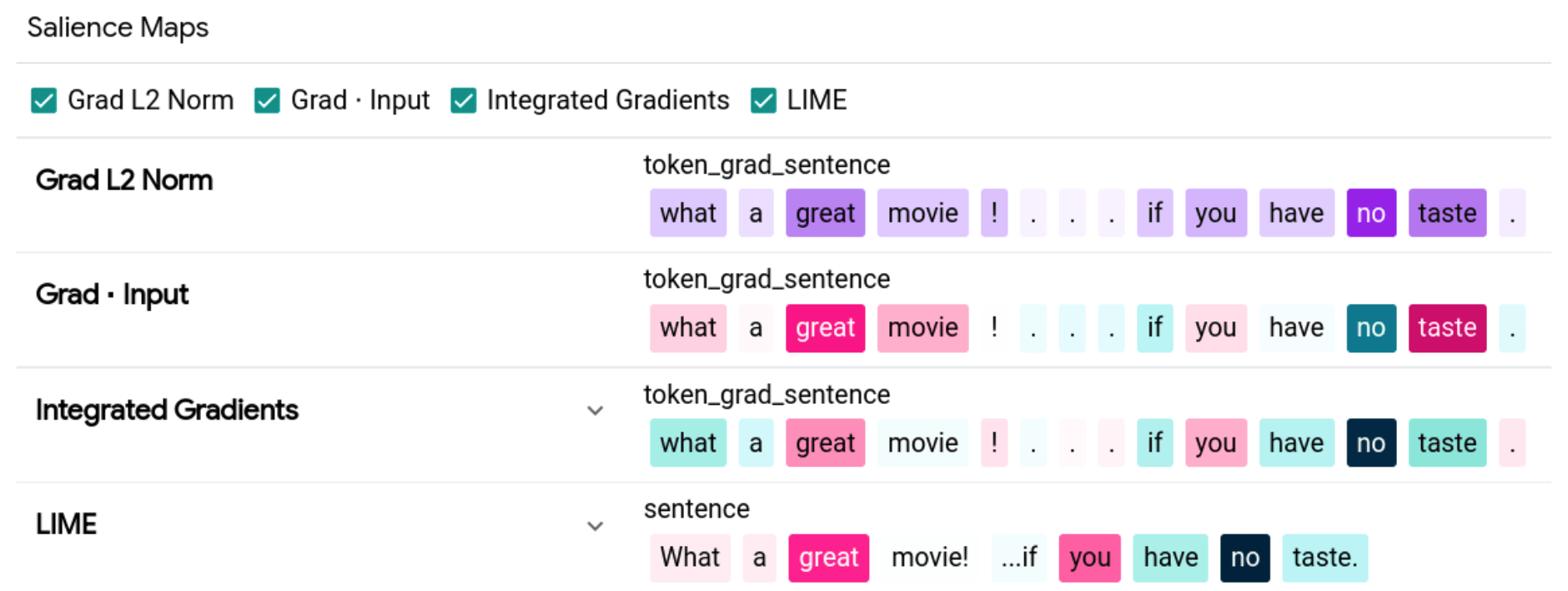
The result clearly shows that the key phrases in the prediction were ’great’ and ’no taste’. Unfortunately, even in this example we can observe a divergence of the contribution of the word ’taste’, which seems to be relevant for correct prediction.
Recent research shows that explanations generated by gradient methods should be used with caution because the largest gradient tends to be concentrated in high frequency areas. In other words, where there is a lot going on in the input example (this is easier to understand in an image example where we have a background and an object in the foreground – the higher frequency will occur in areas of the object contours) [Adebayo et al., 2018]. As an alternative to such approaches, the intrinsically explainable models could be used, in which the decision mechanism is understandable by humans [Rudin, 2019].
Using attention to generate explanation
Recently, approaches that use an attention mechanism have become very popular for xAI in NLP. The attention indicates to the network which words it should focus on. It can be incorporated into many networks, e.g., by adding an attention module between the encoder and decoder in an LSTM, or one can build an entire network based on this mechanism, as in Transformer which is based on self-attention blocks. As it requires a specific architecture it will not work with every model, so it represents a group of methods in which the models explain themselves.
The Language Interpretability Tool also allows you to visualize all the heads and attention layers in the Transformer-based model (BERT) used in the earlier example. An example can be seen below:
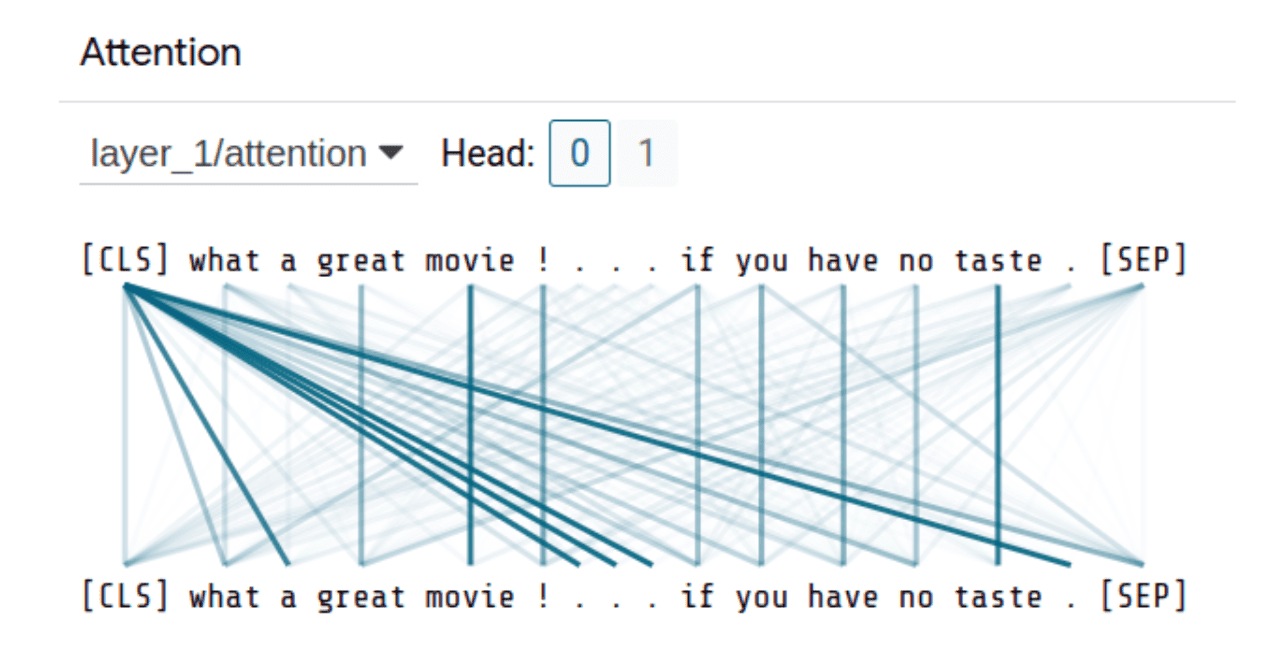
Already in this single example, we observe that this mechanism pays a lot of attention to punctuation marks. Researchers also point this out and indicate that the attention mechanism, despite its great performance, does not always focus on data parts that are meaningful from a human’s point of view, and thus may be less plausible [Jain & Wallace, 2019; Wiegreffe & Pinter, 2019]. If you would like to explore a method that uses the attention mechanism but creates a saliency map like previous methods and simultaneously addresses the problem of too much focus on punctuation marks, we encourage you to check out the publication Towards Transparent and Explainable Attention Models by Akash Kumar Mohankumar et al.
Example-based explanation
The example-based explanations will be the last group of methods mentioned in this article. There are many approaches here, but what they have in common is showing a data point that is in some way relevant to explaining a particular example. The simplest example might be the Nearest Neighbor algorithm, which identifies the most similar example from the training set and presents it as an explanation. An extension of this approach are prototypes, where the most representative examples in the training set for each class are found and a prediction is made as in Nearest Neighbor by analyzing which prototype is most similar to the input example. On the other hand, there are counterfactual explanations, which attempt to change the input example as little as possible so that the classifier’s decision changes, i.e., they implicitly explain the decision boundary.
At this time, to the best of our knowledge, there is no production-level quality library for example-based explanation. The simplest approach would be using the Nearest Neighbor algorithm while encoding texts with the Universal Sentence Encoder [Cer et al., 2018] or other pretrained models. For more advanced examples, we should use more research-oriented methods.
An example could be ProSeNet [Ming et al., 2019]. The authors train the neural network to learn to find prototypes that best represent the entire dataset while being very diverse. The model makes predictions like the Nearest Neighbor algorithm, making it intrinsically explainable. For an example of explanation, see the image below:

Here we can see an input example together with most similar prototypes that were used to make a prediction.
The advantage of example-based approaches is that they usually work with numerous models and explain decisions very well. On the other hand, these methods are usually very simple and do not allow fits in complex pipelines, or in the case of models adapted to be explainable in such approaches (e.g., neural prototype finding like ProSeNet or concept learning), they offer poorer performance than their corresponding black-boxes.
Summary
Explaining artificial intelligence is still a developing area, and the available tools are not always ready for use in production. In each project we are driven by individual customer needs, and we tailor solutions to the requirements. In this article, I have shown several methods that are often used to explain NLP models. Each of them has its advantages, but also its limitations. Knowing them allows us to use the appropriate methods depending on our needs.
For those who would like to learn more about xAI, I recommend checking out the book Interpretable Machine Learning by Christoph Molnar.
References
Wojciech Samek and Klaus-Robert M ̈uller. Towards explainable artificial intelligence. CoRR, abs/1909.12072, 2019. URL http://arxiv.org/abs/1909.12072.
Ben Hutchinson, Vinodkumar Prabhakaran, Emily Denton, Kellie Webster, Yu Zhong, and Stephen Denuyl. Social biases in NLP models as barriers for persons with disabilities. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5491–5501, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.487. URL https://aclanthology.org/ 2020.acl-main.487.
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. ”why should i trust you?”: Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, page 1135–1144, New York, NY, USA, 2016. Association for Computing Machinery. ISBN 9781450342322. doi: 10.1145/2939672.2939778. URL https://dl.acm.org/doi/10.1145/2939672.2939778.
Scott M. Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 4768–4777, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9781510860964.
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. Sanity checks for saliency maps. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems, vol- ume 31. Curran Associates, Inc., 2018. URL https://proceedings.neurips.cc/paper/2018/file/294a8ed24b1ad22ec2e7efea049b8737-Paper.pdf.
Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Machine Intelligence, 1(5):206–215, 2019. ISSN 25225839. doi: 10.1038/s42256-019-0048-x. URL https://doi.org/10.1038/s42256-019-0048-x.
Sarthak Jain and Byron C. Wallace. Attention is not Explanation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 3543–3556, Stroudsburg, PA, USA, 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1357. URL http://aclweb.org/anthology/N19-1357.
Sarah Wiegreffe and Yuval Pinter. Attention is not not explanation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 11–20, Hong Kong, China, November 2019. Association for Computational Linguistics. doi: 10.18653/v1/D19-1002. URL https://aclanthology.org/D19-1002.
Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua, Nicole Limtiaco, Rhomni St. John, Noah Constant, Mario Guajardo-Cespedes, Steve Yuan, Chris Tar, Yun-Hsuan Sung, Brian Strope, and Ray Kurzweil. Universal sentence encoder. CoRR, abs/1803.11175, 2018. URL http://arxiv.org/abs/1803.11175.
Yao Ming, Panpan Xu, Huamin Qu, and Liu Ren. Interpretable and steerable sequence learning via prototypes. In Ankur Teredesai, Vipin Kumar, Ying Li, R ́omer Rosales, Evimaria Terzi, and George Karypis, editors, KDD, pages 903–913. ACM, 2019. ISBN 978-1-4503-6201-6.





