
With the increasing popularity of RAGs, selecting the right data source to complement them is crucial. Specialized tools are needed to handle large volumes of data effectively. OpenSearch, combined with Flink for indexing, offers a scalable and efficient solution for managing large workloads. Using AWS will simplify the setup and long-term maintenance of our solution.
In this cookbook, we will set up OpenSearch, Flink, and Kafka on AWS to create a simple and robust indexing pipeline that will keep documents up to date.
Problem Statement
We manage a large volume of document data that requires rapid retrieval. Our documents may require updates or deletions, and new documents will be added in the future. We need a setup that ensures no data loss and allows for safe recovery in case of any issues.
Proposed Solution
We will create a setup comprising OpenSearch as a search engine, fed data through a Flink pipeline with Kafka as the source of update events.
OpenSearch is a popular search engine that scales horizontally well. On AWS, there are several options for setting it up, ranging from EC2 through EKS to ‘serverless’. We will focus on Managed OpenSearch as an option that offers easy setup while providing significant control over resources and costs.
Flink is a framework for processing data streams. It integrates easily with many different applications and offers safety nets to prevent data loss, making jobs created with it safe and easy to scale. It also supports state creation, which can be helpful in some types of pipelines, like the one we will create here. Kafka is used as an example of an unbounded source of streaming data. In practical applications, you may have limited choices regarding your data source, but Flink offers a multitude of “connectors” to help you interface with other services, and even if that fails, you can implement your own connector.
Detailed Code Walkthrough
In this cookbook, we will use multiple AWS services:
- Amazon MSK – for setting up Kafka
- Managed Apache Flink – for hosting the Flink job
- Amazon OpenSearch Service – for hosting OpenSearch
- Amazon S3 – where the jar with Flink jobs needs to be uploaded
For testing purposes, it is possible to set up all required services (Kafka, Flink, OpenSearch) locally via Docker, and the pipeline we will write here could be run with minor adjustments. However, we will not cover that in this cookbook.
We will also not delve deeply into setting up all the Amazon services. Both Amazon MSK and Amazon OpenSearch Service are set up in the same VPC for ease of use. This VPC needs to have at least 3 subnets in 3 different availability zones to be accepted by those services. To later access the OpenSearch dashboard, we will need either a VPN connection with access to the VPC or a tunnel via an EC2 instance made in the same VPC.
Creating a Flink application is straightforward. On the Amazon Managed Service for Apache Flink starting page, clicking

will bring us to a menu with a few relevant options. We will keep Flink version 1.20 and choose the Development template.
Writing the Flink Pipeline
Before we start coding, let’s define the input data we will work with. Imagine that the data we have available in Kafka was originally stored in a relational database, so Question and Answer were separate tables. When translated into Kafka messages, they are now JSONs stored in two different topics. The questions topic has messages like:
{
"id": "01b35860-8df0-4198-83ea-2d76129cf38d",
"content": "how to java script"
}
and the answers topic has:
{
"id": "9e97038e-9bc4-407e-b168-81b1937b72da",
"questionId": "01b35860-8df0-4198-83ea-2d76129cf38d",
"content": "use google"
}
The pipeline we will create will roughly follow this diagram:
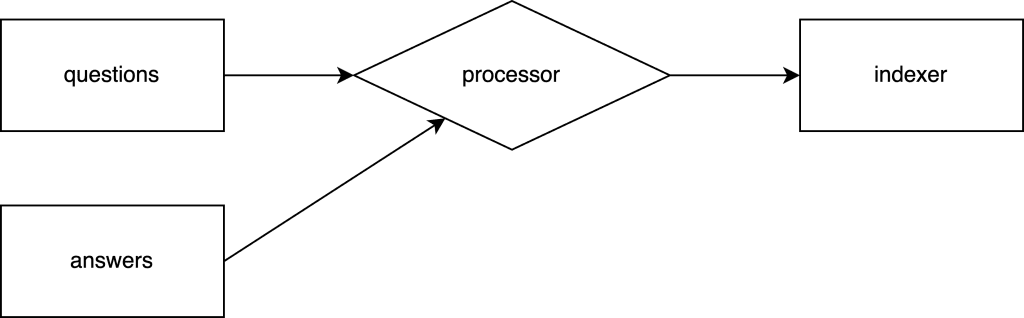
In Flink terms, these components correspond to specific types:
- questions and answers are of KafkaSource type. For them to work, we will need to create classes that implement KafkaRecordDeserializationSchema, which is responsible for deserializing Kafka messages.
- processor is a KeyedCoProcessFunction. It is responsible for “joining” answers with questions.
- indexer is an OpenSearchSink. For it to work, we need a class implementing OpenSearchEmitter that will create documents based on input data.
When working with Flink, we are limited to Java 11. Flink also offers experimental support for Java 17, so you could use it if you are feeling adventurous.
Let’s start the implementation with KafkaSources. We need some helper data types into which we will deserialize data. These implementations are simplified for brevity. Normally, the fields should be private with appropriate getters and setters.
public class Question {
public String id;
public String content;
}
public class Answer {
public String id;
public String questionId;
public String content;
}
Next, we will create QuestionDeserializer.
public class QuestionDeserializer implements KafkaRecordDeserializationSchema<Question> {
The generic argument is the type of objects the deserializer will produce. We need to implement a few methods.
private transient ObjectMapper jsonMapper;
@Override
public void open(DeserializationSchema.InitializationContext context) throws Exception {
KafkaRecordDeserializationSchema.super.open(context);
jsonMapper = new ObjectMapper();
jsonMapper.setVisibility(PropertyAccessor.FIELD, JsonAutoDetect.Visibility.ANY);
}
Flink often serializes and deserializes objects, and when that happens, the constructor will not be called. open serves a similar function as a constructor would and allows us to initialize objects with data that depends on the runtime context, or just fields that are better left transient, like ObjectMapper here.
@Override
public TypeInformation<Question> getProducedType() {
return TypeInformation.of(Question.class);
}
Generic types are erased during runtime, but for some operations, Flink needs to know the exact types that are produced by different classes. TypeInformation is used to represent types that would not be visible during runtime.
@Override
public void deserialize(ConsumerRecord<byte[], byte[]> consumerRecord, Collector<Question> collector) throws IOException {
var question = jsonMapper.readValue(consumerRecord.value(), Question.class);
collector.collect(question);
}
Lastly, the central part of the implementation. To unmarshal a JSON message, that is all we need.
The AnswerDeserializer implementation is nearly identical; just replace Question with Answer where needed.
Next, we have DataProcessor.
public class DataProcessor extends KeyedCoProcessFunction<String, Question, Answer, QuestionDocument> {
Generic attributes in KeyedCoProcessFunction are as follows:
- key type
- first input type
- second input type
- output type
QuestionDocument is a new class representing a question with its answers.
public class QuestionDocument {
public String id;
public String content;
public Map<String, AnswerDocument> answers;
public QuestionDocument() {
answers = new HashMap<>();
}
}
public class AnswerDocument {
public String id;
public String content;
}
The key is important to understand. Some processing functions will work only on keyed streams. Turning a normal stream into a keyed one is simple – you just define a function that will be able to extract the key from objects found in the stream. In return for having keys defined, Flink gives us a promise that all events with the same key will be processed in the same order as they arrived and that two events with the same key will not be processed at the same time in our processor. Those promises by themselves solve a lot of potential issues that could be created by parallel data processing.
private static final String QUESTION_STATE_NAME = "questionState";
private transient ValueState<QuestionDocument> state;
@Override
public void open(OpenContext openContext) throws Exception {
super.open(openContext);
state = getRuntimeContext().getState(new ValueStateDescriptor<>(QUESTION_STATE_NAME, QuestionDocument.class));
}
To be able to join data from questions with answers, we will use ValueState. It must be initialized in open using the runtime context we get by calling getRuntimeContext().
Next, we need to create two separate processing functions, one for question input, the other for answer input.
@Override
public void processElement1(Question question, Context ctx, Collector<QuestionDocument> out) throws Exception {
QuestionDocument stateValue = getStateValue();
stateValue.id = question.id;
stateValue.content = question.content;
state.update(stateValue);
out.collect(stateValue);
}
private QuestionDocument getStateValue() throws Exception {
QuestionDocument stateValue = state.value();
if (stateValue == null) {
stateValue = new QuestionDocument();
}
return stateValue;
}
When we receive a question event, we do as follows:
- Get the current state or a default value.
- Update data based on the event.
- Put updated data into the state.
- Create an event with new data.
Notice how the state is accessed – both when initializing open and when accessing via state.value() we do not specify id; Flink knows what the id is and does it in our place.
@Override
public void processElement2(Answer answer, Context ctx, Collector<QuestionDocument> out) throws Exception {
QuestionDocument stateValue = getStateValue();
AnswerDocument answerDocument = new AnswerDocument();
answerDocument.id = answer.id;
answerDocument.content = answer.content;
stateValue.answers.put(answerDocument.id, answerDocument);
state.update(stateValue);
if (stateValue.id != null) {
out.collect(stateValue);
}
}
The only real difference in the answer process is at the very end. While we treat a question with no answers as valid, it is not true the other way around. We check if the question data is present before creating an event. If a question is processed after its answers, we are safe since it will still generate an event in processElement1.
Lastly, we have CookbookOpensearchEmitter.
public class CookbookOpensearchEmitter implements OpenSearchEmitter<QuestionDocument> {
@Override
public void emit(QuestionDocument q, SinkWriter.Context context, RequestIndexer indexer) {
var answers = q.answers.values().stream()
.map(a -> Map.of("id", a.id, "content", a.content))
.collect(Collectors.toList());
var document = Map.of(
"id", q.id,
"content", q.content,
"answers", answers
);
indexer.add(Requests.indexRequest()
.index("cookbook_index")
.id(q.id)
.source(document));
}
}
emit receives a single event and needs to create an indexing event. The input data is transformed into a map with String keys that closely resembles how the JSON documents will look in OpenSearch. We also get the indexer object, which we use to create indexRequest – this type of event is capable of both creating and updating.
Now all the parts need to be put together.
public class Main {
public static void main(String[] args) throws Exception {
var env = StreamExecutionEnvironment.getExecutionEnvironment();
env is an execution environment. That’s how we interact with Flink to tell it what it actually needs to run.
var opensearchSink = new OpensearchSinkBuilder<QuestionDocument>()
.setEmitter(new CookbookOpensearchEmitter())
.setHosts(HttpHost.create("OPENSEARCH"))
.build();
Next, we create a sink. A sink is where the data exits the pipeline. OPENSEARCH is your cluster’s address in VPC, which you should find in the AWS console under Domain endpoint (VPC).

var questionSource = KafkaSource.<Question>builder()
.setBootstrapServers("KAFKA_BOOTSTRAP")
.setGroupId("test_group")
.setTopics("questions")
.setDeserializer(new QuestionDeserializer())
.build();
var questionWatermarkStrategy = WatermarkStrategy
.<Question>forBoundedOutOfOrderness(Duration.ofMinutes(1))
.withIdleness(Duration.ofMinutes(1));
var questionStream = env.fromSource(questionSource, questionWatermarkStrategy, "questionSource", TypeInformation.of(Question.class));
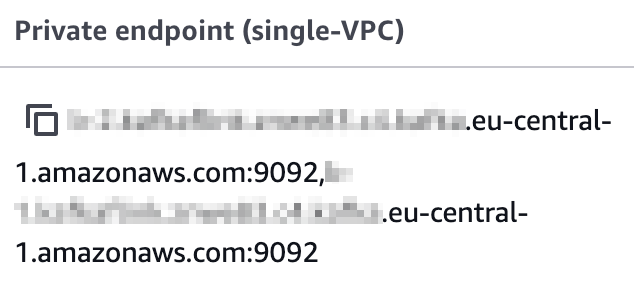
Creating questionSource is straightforward. KAFKA_BOOTSTRAP is a list of Kafka bootstrap servers. You can find it by clicking View client information in the Amazon MSK dashboard.

Transforming it into questionStream involves choosing WatermarkStrategy. This is a complex topic, but in our case, we configure it to handle out-of-order timestamps and partitions with widely varying timestamps.
The input for answers is nearly identical:
var answerSource = KafkaSource.<Answer>builder()
.setBootstrapServers("KAFKA_BOOTSTRAP")
.setGroupId("test_group")
.setTopics("answers")
.setDeserializer(new AnswerDeserializer())
.build();
var answerWatermarkStrategy = WatermarkStrategy
.<Answer>forBoundedOutOfOrderness(Duration.ofMinutes(1))
.withIdleness(Duration.ofMinutes(1));
var answerStream = env.fromSource(answerSource, answerWatermarkStrategy, "answerSource", TypeInformation.of(Answer.class));
All the components need to be put together:
questionStream.keyBy(question -> question.id).connect(answerStream.keyBy(answer -> answer.questionId)).process(new DataProcessor()).sinkTo(opensearchSink);
We define what is a key for question and answer streams. For question, it is their id. For answers, it is questionId. Using questionId allows us to “join” question and answer data in our processor under the same keys.
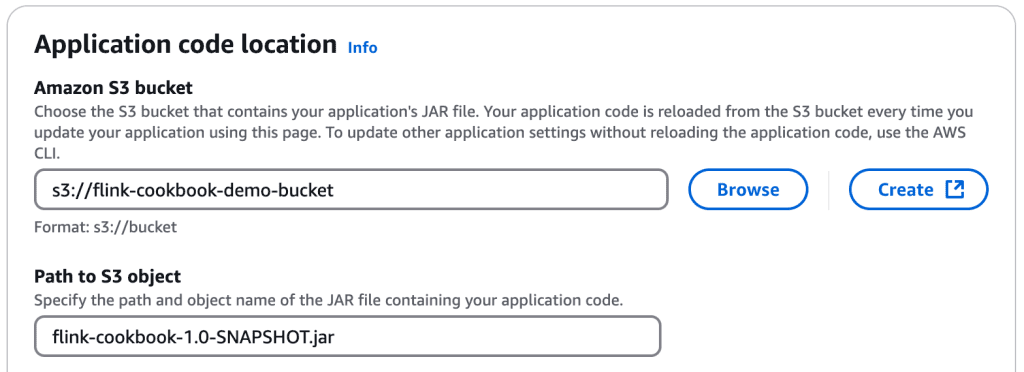
It’s time to build the project and put the resulting jar on S3. Once we have that ready, let’s head over to Flink’s dashboard. On the top right, we have several buttons.

First, we need to Configure our job. For this cookbook, let’s focus only on a few settings.
Bucket with jar
And now we have network settings
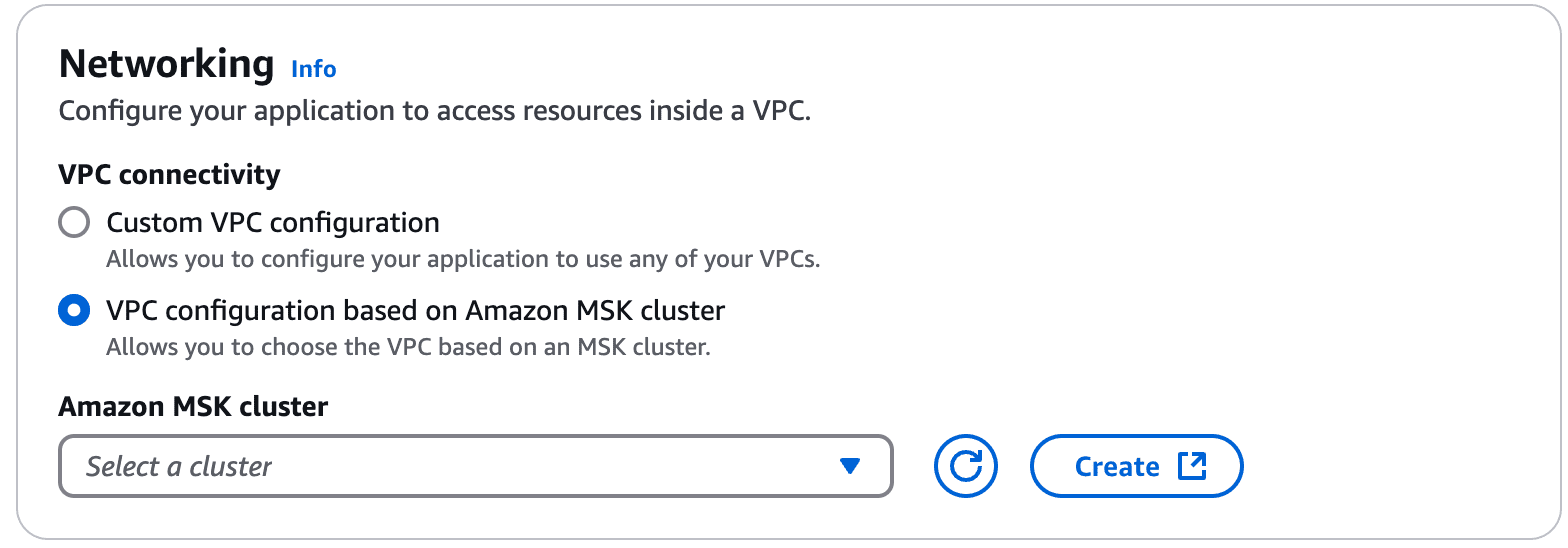
VPC configuration based on Amazon MSK cluster is very convenient if you are using MSK as a source, as we are in this cookbook.
Time to save changes.

Applying changes may take a moment.
Testing and Validation
After that, we need to run the job

and check it on Flink’s dashboard.

Under Running jobs

we can find our pipeline.
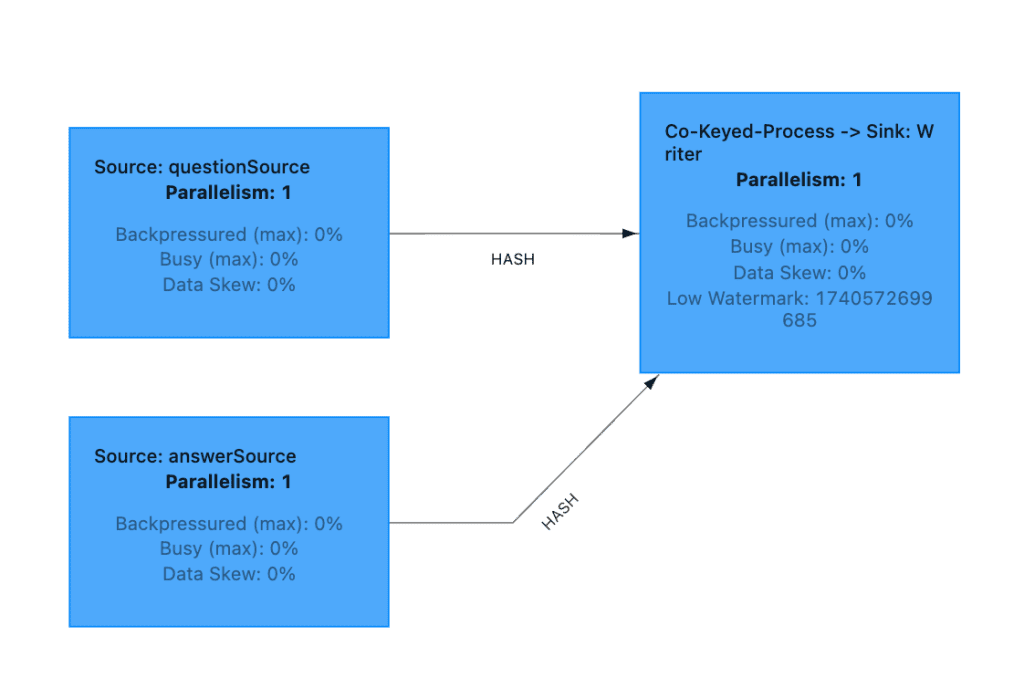
It’s slightly different from the first diagram we sketched since Flink decided the last two blocks can be merged.
Now let’s go to OpenSearch and verify that we actually created any documents. Running GET in the developer console:
GET cookbook_index/_search
{
"query": {
"match_all": {}
}
}
gives a list of results:
{
"took": 681,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "cookbook_index",
"_id": "01b35860-8df0-4198-83ea-2d76129cf38d",
"_score": 1,
"_source": {
"id": "01b35860-8df0-4198-83ea-2d76129cf38d",
"content": "how to java script",
"answers": [
{
"id": "9ef44297-1d97-4c17-92a2-2de9ed296d96",
"content": "read a book"
},
{
"id": "9e97038e-9bc4-407e-b168-81b1937b72da",
"content": "use google"
},
{
"id": "c5a15a93-0f47-4317-86f7-0873dc1f28d1",
"content": "you no java script, you type script"
}
]
}
},
{
"_index": "cookbook_index",
"_id": "8543a503-d412-4cca-a47b-9287327ccd62",
"_score": 1,
"_source": {
"id": "8543a503-d412-4cca-a47b-9287327ccd62",
"content": "there is no question",
"answers": []
}
},
{
"_index": "cookbook_index",
"_id": "19a0d777-2348-47fe-b46e-15806edcd454",
"_score": 1,
"_source": {
"id": "19a0d777-2348-47fe-b46e-15806edcd454",
"content": "is the cat alive?",
"answers": [
{
"id": "a34ff54c-d697-4653-866f-7f2ea5e74faa",
"content": "yes"
}
]
}
}
]
}
}
Summary & Next Steps
With that, we have created a simple indexing pipeline for OpenSearch using Flink. It can run indefinitely and update documents as needed. For the next steps, we can explore multiple directions. In this cookbook, we assumed that we have messages on Kafka ready, but they must have originated from somewhere. Creating pipelines that generate events based on updates to a SQL database or entirely different sources is worth exploring. On the other end of the pipeline, we used a mechanism creating a simple default index. For production use, it would be wise to properly define an index with appropriate stemmers and analyzers as well as search templates. Examining indices is also a good opportunity to investigate how to configure an index capable of holding vectors and supporting vector search.
Authors
Mateusz Twaróg
Senior Software Engineer






