
Table of contents
It was far and away the most popular Kaggle competition, gaining the attention of more than 8,000 data scientists globally. The team of Paweł Godula, team leader and deepsense.ai’s Director of Customer Analytics, Michał Bugaj and Aliaksandr Varashylau took fifth place and 1st on the public leaderboard.
Table of contents
The goal of the competition launched by Home Credit Group was to build a model that could predict the probability of a bank’s customer repaying a cash loan (90% of the training data) or installment loan (10% of the training data). Combining an exciting, real-life challenge and a high-quality dataset, this competition became the most popular ever featured competition on Kaggle.
The sandbox raiders
There can be no doubt that being a data scientist is fun. Playing with various datasets, finding patterns and exploring the needles hidden in the depths of the digital haystack. This time, the dataset was a marvel to behold. Why?
- The bank behind the competition provided data on roughly 300,000 customers, including details on credit history, properties, family status, earnings and geographic location.
- To enrich the dataset the bank provided information about the customers’ credit history taken from external sources, mostly from customer-ratings institutions.
- The level of detail provided was astonishing. Participants could analyze the credit history of customers at the level of a single installment of a single loan.
- While the personal data was of course perfectly anonymized, the features were not. This enabled endless feature engineering, which is every data scientist’s dream.
In other words, the dataset was the perfect sandbox, allowing all of the participants to get into the credit underwriters’ shoes for more than 3 months. Our solution was based on three steps, described briefly below.
1. Hand crafting more than 10,000 features
Out of 10,000 features, we carefully chose the 2,000 strongest for the final model. Endless brainstorming, countless creative sessions and discussions gave us more than 10,000 features that could possibly explain the default on a loan. As most of these features carried largely duplicate information, we used an algorithm for automatic feature selection based on feature importance. This procedure enabled us to eliminate ~8,000 features and reduce the training time significantly, while improving the cross validation score at the same time. The heavily tuned, five-fold bagged, LightGBM model based on these 2,000 features was our submission’s workhorse.
2. Using deep learning to extract interactions among different data sources
We wondered how we could capture the interactions between signals coming from different data sources. For example, what if 20 months ago someone was rejected in an external credit Bureau, had a late payment in their installment payments, and applied for a loan at our branch? These types of interactions are very hard to capture by humans because of the number of possible options. So, we turned to deep learning and turned this problem into an image classification problem.
How?
We created a single vector of user characteristics coming from different data sources for every month of user history, going as far back as 96 months(8 years was the cutoff in most data sources). We then stacked those vectors and created a very sparse “user image” and, finally, fed this image into a neural network.
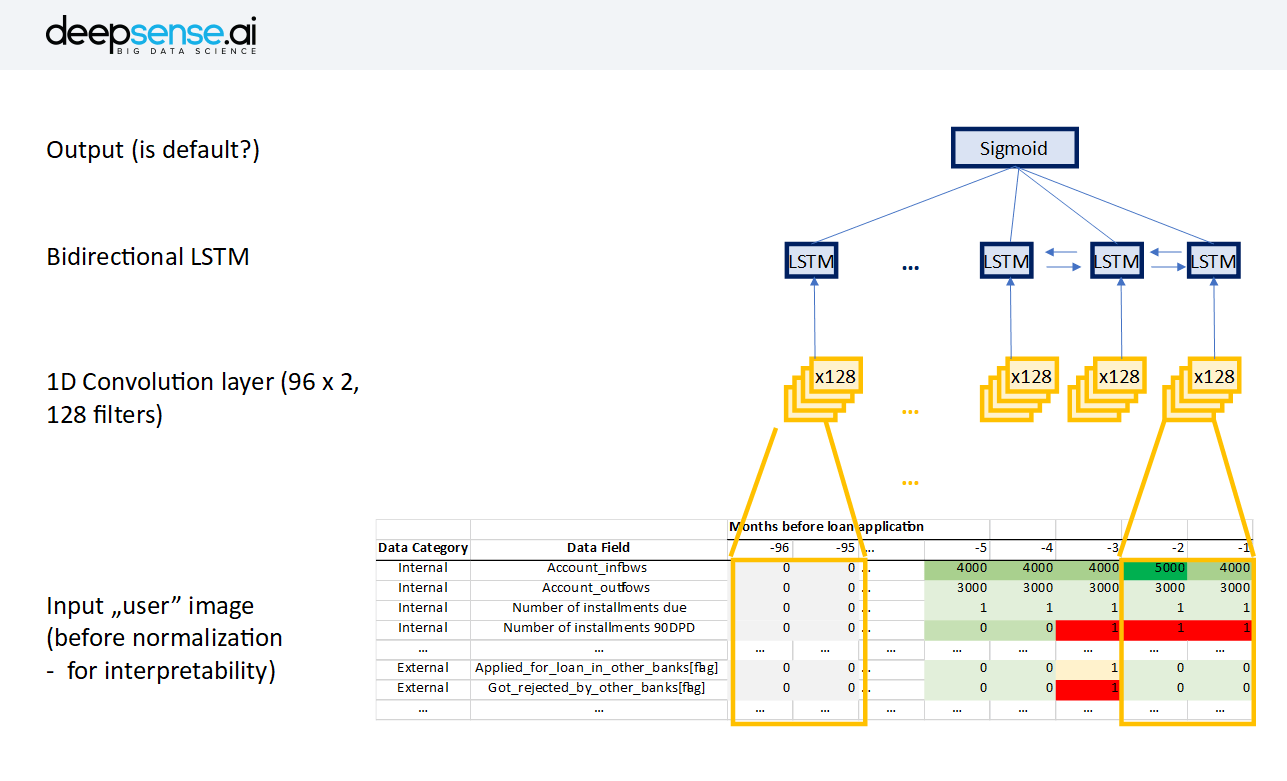
The network architecture was as follows:
- Normalization – division by global max in every row
- Input (the “user image” in format of n_characteristics x 96 months – we looked 8 years into the past)
- 1-D convolution spanning 2 consecutive months (to see the change between periods)
- Bidirectional LSTM
- Output
This model trained rather quickly–around 30 mins on a GTX 1080–and gave us a significant improvement on an already very strong model with 2000 hand-crafted features. This means that the network was able to extract some information on top of >2000 hand-crafted features. We believe in this approach, particularly for more commercial settings, where the actual metric of the model is not only accuracy, but also the time the data science team (i.e. cost) requires to develop the model. For us, the opportunity cost was only the sleep we missed, which we gladly gave up to take part in this amazing competition. However, most businesses have a more rational and less emotional approach to data science and prefer cheap models to expensive ones. Deep learning offers an attractive alternative to manual feature engineering and is able to extract meaningful information from time-series bank data.
3. Using nested models
One of the things that bothered us throughout the competition was the somewhat arbitrary nature of various group-bys that we performed on data while doing the hand-crafted features. For example, we supposed that an overdue installment from five years ago would be less important than one from just a month ago. However, what is the exact relationship? The traditional way is to test different thresholds using a cv score, but there is also a more elegant way for the model to figure it out.
What we did was build a bunch of “limited-power” models using only only a single source of data (for example, only a credit card’s history). The purpose of that was to force the model to find all possible relationships in the given data source, even at the cost of accuracy. Below are the AUC (area under curve metric) scores that we got from models using only one data source:
- Previous application: 0.63
- Credit card balance: 0.58
- Pos cash balance: 0.54
- Installment payments: 0.58
- Bureau: 0.61
- Bureau balance: 0.55
The very low AUC scores for these models were hardly surprising, as they carry enormous amounts of noise. Even for default clients, the majority of their past behaviors (past loans, past installments, past credit cards) were OK. The point was to identify those few behaviors that were common across defaulters.
The way to use those models is to extract the most “default-like” behaviors and use them to describe every user. For example, a very strong feature in the final model was “the maximum default score on a single behaviour of a particular user”. Another very strong feature was “Number of behaviors with default score exceeding 0.2 for a particular user”. Using features from these models further improved an already very strong model: The models learned to abstract whether a particular behavior would lead to a default or not. In summary, the final model used the following features:
- More than 2,000 hand-crafted features, selected out of 10,000 features created during brainstorming and creative sessions
- one feature from the neural network from Step 2
- Around 40-50 features coming from “nested models” described in Step 3
The portfolio of models we tested included an XGBoost, LightGBM, Random Forest, Ridge Regression and Neural Nets. A LightGBM proved to be the best model, especially with heavily tuned hyperparameters for regularization (the two most important parameters were feature fraction and L2 regularization).
The model was prepared by Michał Bugaj, Aliaksandr Varashylau and Paweł Godula (Customer Analytics Director at deepsense.ai), who led the team. They were able to predict if a lender would default on a loan with 80% AUC (meaning that there was an 80% probability that a randomly selected “defaulter”, or person who defaulted on a loan, would be ranked by the model as a defaulter before a non-defaulter). Our solution ranked fifth, and a tenth of a percentage point less effective than the leader on the private leaderboard. We took 1st place on the public leaderboard. The competition itself was a great experience, both for the organization behind it and the participants, as the models provided appeared to be effective and business oriented. Remember our blog post about launching a Kaggle competition? This competition may qualify as perfect, one that might fit right in Sevres.





