
Table of contents
When teams start deploying agentic systems beyond controlled demos, a familiar pattern emerges. These systems rarely fail gracefully. Instead, one overloaded agent stalls, retrieval misses a critical document, bot detection shuts the door, the prompt grows too long, and suddenly the entire workflow feels brittle.
On paper, the architecture often looks elegant.
In production, it turns out the system needed more structure, more parallelism, better visibility, and more humility about what LLMs can reliably handle.
This article distills a set of recurring lessons from real-world agent deployments. Not theoretical failures, but practical breakpoints that surface once agentic systems meet scale, latency constraints, user expectations, and the open internet.
Why Production Agentic Systems Collapse Instead of Degrading Gracefully
Modern AI stacks don’t win by concentrating more intelligence inside a single agent. They win by distributing responsibility across many components, each with a clearly defined role.
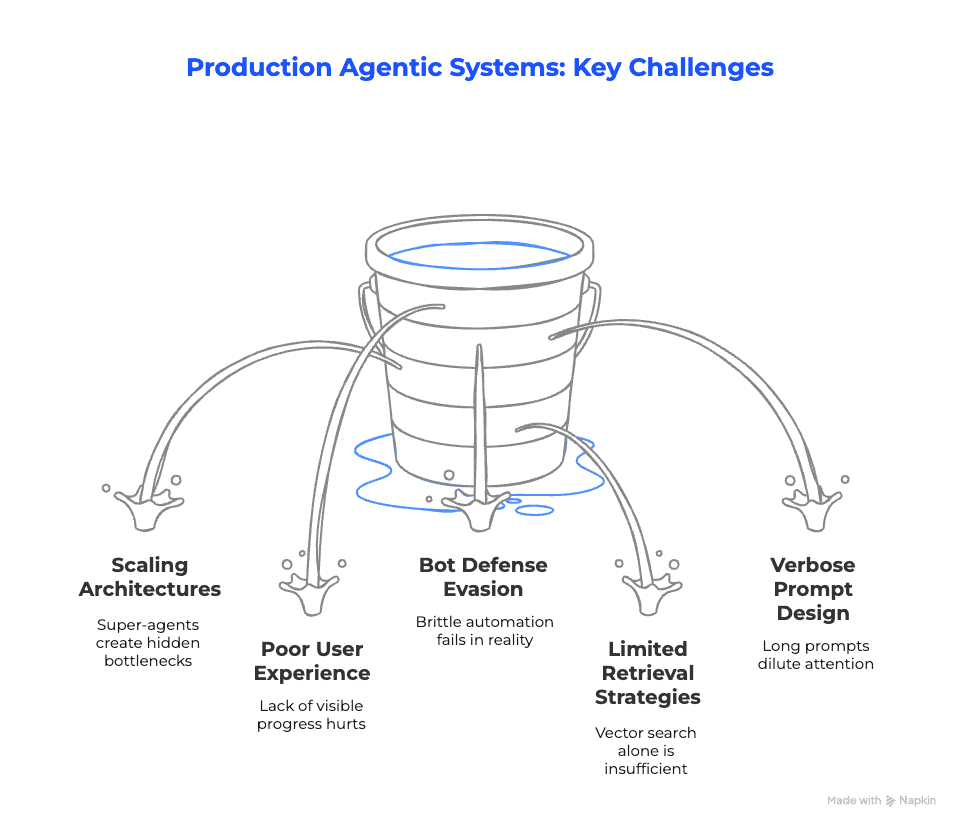
Across deployments, the same core problems keep appearing:
- Single “super-agents” become latency bottlenecks when forced to handle multi-domain tasks.
- Users lose trust when long workflows execute silently with no visible progress.
- Bot-detection systems break functional agents the moment they leave localhost.
- Pure vector search misses critical context, creating false confidence.
- Verbose prompts dilute attention and reduce accuracy instead of improving it.
The following sections break down each of these failure modes — and what consistently works instead.
AI Agents: Lessons Learned in the Field

1. When One Agent Tries to Do Everything, Everything Slows Down
We’ve repeatedly seen monolithic “expert” agents collapse under multi-source or multi-domain tasks. Symptoms are familiar: slow responses, skipped steps, and reasoning loops that look like the agent is second-guessing itself.
A single agent can’t juggle retrieval, analysis, planning, and execution across heterogeneous inputs. It inevitably becomes the bottleneck.
In practice, what made the difference was decomposition and parallelization.
Once the system was split into an Orchestrator Agent and several specialized downstream agents, each responsible for a narrow slice of the workflow, tasks began running in parallel instead of queueing behind one overworked brain.
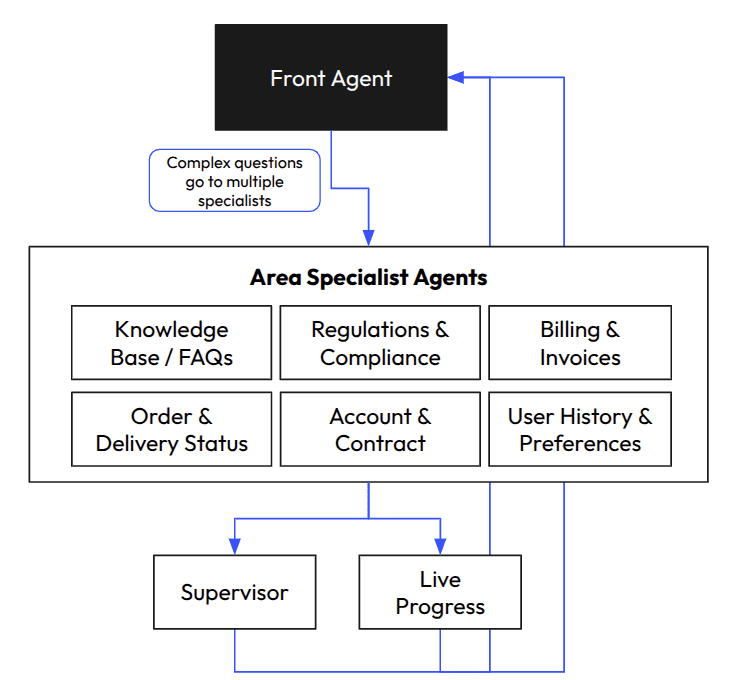
Most importantly, user interactions started to feel faster, clearer, and more coherent, even for complex analytical tasks. The system stopped thinking in a line and started thinking as a team.
Takeaway: Don’t just scale the agent. Scale the coordination.
2. Latency and UX in Production Agentic Systems: Why Transparency Matters
Users tolerate computation time. They do not tolerate silence.
When multi-step plans ran with no visible progress, workflows felt broken — even when everything was functioning correctly behind the scenes. The moment plan previews, editable steps, and streamed partial results were introduced, those same workflows suddenly felt responsive and trustworthy.
Planner and supervisor-style architectures, in particular, can feel opaque unless users see:
- what the system intends to do,
- which step it’s on,
- and how far along it is.
Once users can observe the system’s thinking in real time, the interaction shifts. Partial results reinforce that progress is happening, and the interface starts to feel like a partner rather than a black box.
Takeaway: Make the system think out loud. Humans trust what they can see.
3. Bot Detection and Web Constraints in Real-World Agent Automation
Agents that worked flawlessly in controlled environments were often blocked instantly in the wild:
- fingerprint checks,
- mouse-movement heuristics,
- CAPTCHAs,
- rate limits.
The gap between localhost and the open internet is enormous — and detection systems evolve constantly.
Most websites now rely on layered bot-detection systems that block not only malicious scrapers, but also legitimate automation. We learned quickly that mimicking human-like clicks isn’t enough. Intent-awareness and proper authentication matter far more than evasion.
This is why the ecosystem is shifting toward:
- extended robots.txt directives,
- emerging llms.txt files,
- purpose-specific user agents.
OpenAI’s crawler framework already reflects this shift, with separate agents like GPTBot, OAI-SearchBot, and ChatGPT-User, each configurable by site owners. It’s an early move toward declared intent and negotiated access, rather than fragile heuristics.
Takeaway: Real-world automation requires consent, not evasion.
4. Retrieval in Agentic Systems: Why Vector Search Alone Is Not Enough
Pure top-N vector retrieval can fail silently. Nothing crashes, but critical context never appears because the embedding model didn’t surface it.
The issue isn’t that vector search is too broad — it’s that it’s too narrow.
What worked better was flipping the usual approach:
- use a small, fast LLM for breadth,
- then apply vector search for precision.
The lightweight model scanned candidate documents and judged which chunks might matter. Vector search then ranked results within that smaller, filtered set. This hybrid workflow dramatically improved coverage, capturing edge cases and subtle signals that would never make it into a top-N cutoff.
Takeaway: Combine semantic search with LLM-based reasoning to avoid blind spots.
5. Prompt Design for Agentic Systems: Why Brevity Beats Verbosity
As prompts grew longer, performance consistently degraded:
- constraints diluted,
- focus drifted,
- the model emphasized the wrong parts of the task.
Studies like Context Rot and An Empirical Study on Prompt Compression confirm what showed up in practice: as input length increases, models lose coherence and accuracy. This is classic attention decay — the needle disappears as the haystack grows.
Brevity isn’t aesthetic. It’s an accuracy hack.
Short, direct prompts with clearly reinforced constraints worked best. Beyond a certain point, repetition added noise rather than stability.
Takeaway: Prompt design is about precision and emphasis, not exhaustiveness.
What Actually Matters When Building Enterprise-Grade Agentic Systems
Across real deployments, the same principles surface again and again:
- Architectures scale through parallelization, not model size.
- UX drives perceived performance through visible progress.
- Automation must cooperate with real-world defenses.
- Retrieval needs LLM judgment alongside embeddings.
- Prompt clarity beats verbosity every time.
For developers, this means designing for coordination, observability, and failure from the start. For architects, it means prioritizing system structure over diagram elegance. For product and engineering leaders, it means recognizing that agentic systems demand ongoing engineering discipline, not just better models.
Table of contents





