Table of contents
The AI landscape is entering a new architectural phase. After years of optimizing Large Language Models through scale and next-token prediction, emerging research points to a different frontier: systems that learn internal models of the world, capturing state, dynamics, and cause-and-effect rather than surface-level text patterns.
We are seeing this play out in real-time. Google’s release of Genie 3 has reportedly sent shockwaves through the gaming ecosystem, challenging the dominance of traditional engines such as Unity by generating interactive environments solely from learned latent dynamics.
Simultaneously, the industry is closely watching Yann LeCun’s pivot from Meta to his new venture, AMI (Advanced Machine Intelligence) Labs. His thesis remains consistent and compelling: AGI requires World Models—systems that understand cause and effect and are grounded in physical reality rather than merely statistical correlations in text.
Why World Models Matter for Enterprise AI
- Lower inference cost: Non-autoregressive prediction reduces sequential decoding overhead.
- Improved determinism: Embedding prediction is less sensitive to prompt perturbations.
- Reduced hallucinations: Predicting latent state instead of surface text constrains output space.
- Better multimodal fusion: Shared latent space simplifies system composition.
This converts theory into strategy.
The Rise of Non-Autoregressive Reasoning
For technical decision-makers, the signal here is the move away from pure autoregression. The recent “LeJEPA” (Balestriero and LeCun #) publication demonstrated, with mathematical rigor, that pretraining Joint Embedding Predictive Architectures (JEPA) (LeCun #) can be achieved without heuristic tricks, specifically by aligning embeddings with isotropic Gaussians. In the meantime, the newly released VL-JEPA (Vision-Language JEPA) (Chen et al. #) provides a concrete illustration of the benefits of applying JEPA to multimodal tasks.
VL-JEPA: Abstraction Over Generation
VL-JEPA (Vision-Language Joint Embedding Predictive Architecture) (Chen et al. #) is a novel approach to integrating visual perception and textual understanding. Unlike standard Multimodal LLMs (MLLMs) that process inputs to autoregressively generate discrete tokens, VL-JEPA operates entirely within a continuous latent space.
This distinction is crucial for engineering leaders to understand:
- Higher-Level Abstraction: By predicting representations rather than pixels or tokens, the model captures semantic meaning (e.g., understanding that “the room is dark” and “the lamp is off” are state-equivalent) without being unduly influenced by surface-level variability.
- One-Shot Generation: It is non-autoregressive and can predict the entire target embedding sequence in a single forward pass.
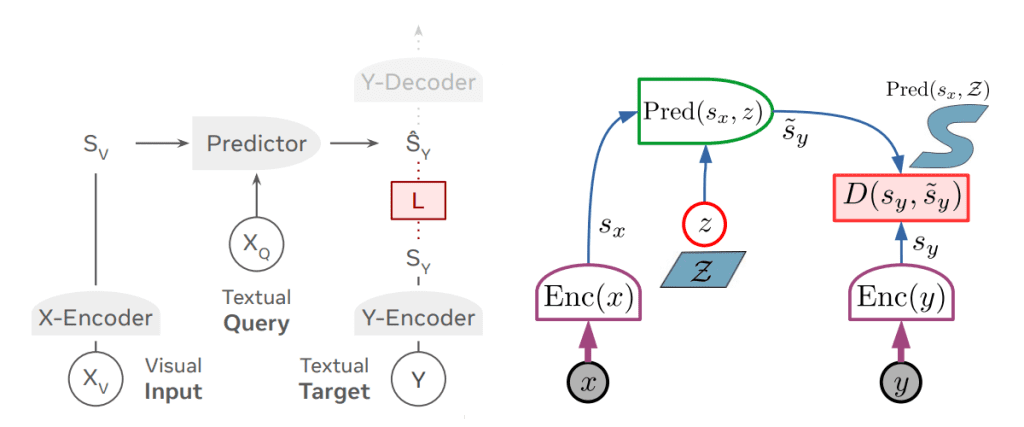
Figure 1. Comparison of VL-JEPA Architecture with standard JEPA diagram (LeCun #) (Chen et al. #)
Architectural Breakdown
The architecture of VL-JEPA is a masterclass in component reusability and efficiency. It adapts the standard JEPA design (see Figure 1) for multimodal data by integrating specialized encoders:
- Vision Encoder Enc(Xv): It utilizes a pretrained V-JEPA 2 model. Crucially, this encoder is frozen during training, with only the projection layers being fine-tuned. This leverages V-JEPA 2’s existing understanding of video and physical dynamics.
- Text Encoder/Latent Z(XQ): Embedding layer that converts text tokens to embeddings.
- The Predictor: This is where the reasoning occurs. It comprises the top 8 transformer layers of a Llama 3 (1B) model, repurposed to predict the target-text embedding from the visual input. It has removed causal attention and is not autoregressive.
- Y-Encoder Enc(Y): Initialized with EmbeddingGemma-300M, it generates target embeddings from target text (Y) used during training.
The Mathematics of Alignment: InfoNCE Loss
To ensure that the predicted representations are both meaningful and distinct, VL-JEPA employs the InfoNCE loss function. This objective balances two competing forces:
- Representation Alignment: Pulling embeddings of positive pairs (matching image-text) closer together.
- Uniformity Regularization: Pushing embeddings of negative pairs (batch noise) apart to prevent representation collapse.
The loss can be formalized as:
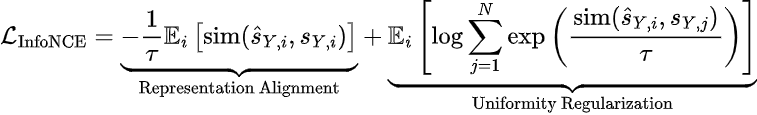
Where SY,i is the target representation, ŜY,i is the prediction, and τ is the temperature parameter. This regularization enables the model to learn a structured world model without requiring pixel-perfect reconstruction.
Performance and Efficiency
The evidence for this approach is compelling. Despite being trained on fewer samples and having significantly fewer trainable parameters (approximately 50% fewer than standard baselines), VL-JEPA demonstrates superior performance on established benchmarks. In comparative analyses, it holds its own against heavyweights like Gemini 2, GPT-4o, and Claude 3.5 in specific vision-language tasks.
Our Perspective
At deepsense.ai, we regard VL-JEPA not merely as a research novelty but as a blueprint for efficient, scalable AI. For our clients, this shift towards embedding-based prediction promises systems that are faster, less prone to hallucination, and capable of deeper reasoning. As we continue to build custom AI solutions, architectures that prioritize understanding over predicting the next word will be key to unlocking value in complex enterprise environments.
Works Cited
- Balestriero, Randal, and Yann LeCun. “Lejepa: Provable and scalable self-supervised learning without the heuristics.” arxiv, vol. 2511, no. 08544, 2025, https://arxiv.org/pdf/2511.08544.
- Chen, Delong, et al. “Vl-jepa: Joint embedding predictive architecture for vision-language.” arxiv, vol. 2512, no. 10942, 2025, https://arxiv.org/pdf/2512.10942.
- LeCun, Yann. “A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27.” Open Review, vol. 62, no. 1, 2022, pp. 1-62, https://openreview.net/pdf?id=BZ5a1r-kVsf..