Table of contents
In applied AI projects, teams often build datasets and benchmarks before validating the method with real users. Offline metrics improve. Accuracy looks solid. Confidence grows.
OThen UAT begins – and structural flaws surface: task framing is off, orchestration is brittle, latency feels wrong, outputs are unusable.
Our hypothesis is simple:
Automated evaluation doesn’t establish correctness. It amplifies whatever you’ve built.
In this issue, we explain why early metrics mislead, where agent systems actually break, and the sequencing that consistently works in production.
The Dataset Trap in Enterprise Agentic Systems
In applied AI projects, the pattern is consistent.
Teams start by building datasets. They design benchmarks. They run an offline evaluation. Metrics improve. The numbers look reassuring. Progress feels measurable.
And while this approach works well for more traditional AI applications, it breaks down for GenAI-powered systems. We’ve seen it time and again: UAT begins – and the system changes.
That’s because early evaluation answers the wrong question. It measures consistency against predefined examples. It does not test whether the method itself is sound.
We’ve repeatedly seen that approximately 10 intentionally diverse, real inputs with manual inspection are enough to expose core structural flaws:
- Latency feels unacceptable.
- Output formats are confusing or unusable.
- Task decomposition doesn’t match how users think.
- Agent boundaries are fragile.
None of this showed up in offline metrics.
Offline datasets didn’t reveal these issues. Real users did.
Evaluation is a multiplier. It scales confidence in the current implementation. If the approach is directionally correct, that multiplier compounds the value. If it isn’t, it compounds the illusion.
Before investing in datasets and large-scale evaluation, make sure the method survives contact with reality.
Where Production Agentic Systems Actually Break
Large datasets measure aggregate performance across predefined scenarios. They don’t evaluate whether the system behaves correctly in context.
Context is where things collapse.
- UAT force 180° changes that no offline validation detected.
- Workflows that technically execute but are cognitively wrong.
- Output formats that pass automated checks, yet users cannot work with.
- Response timing that feels broken, even though latency was within expected bounds.
The same pattern appears with hallucinations. They don’t emerge randomly. They spike when inputs are oversized or inconsistent.
Large structured payloads – especially JSON – introduce ambiguity. If expected fields are absent, models silently backfill. The output looks complete, it’s just wrong.
Chunking large payloads item-by-item and enforcing strict output validation changes that failure mode. If required structured fields are missing, fail fast. Otherwise, the system appears reliable while quietly inventing values.
All of this sits outside traditional accuracy metrics.
Until task decomposition, orchestration, latency, and output format are accepted by real users, evaluation scores are measuring stability of an unstable design. The system may be consistent. That doesn’t mean it works.
The Only Order That Works in Production
In multiple projects, UAT led to fundamental redesigns – not small prompt tweaks, but changes in workflow structure and behavior.
When that happens early, iteration remains fast. When it happens after large-scale dataset investment, weeks of evaluation work become partially irrelevant. Pipelines need to be rebuilt. Benchmarks lose meaning. What looked like progress turns into rework.
A practical threshold emerges from this pattern: reach >75% reliable behavior with real users before scaling evaluation. Once that level is reached, dataset creation starts compounding value. Automated evaluation reinforces a stable method instead of locking in instability.
Method first. Then data.
Secure AI Agents in Production
Why safety and guardrails matter in production AI systems

Scale Structure, Not Chaos
Once the method works, a different failure mode tends to appear: growth without structure.
As agent systems expand — often to 100+ skills — orchestration starts to fray.
Prompts fill up with long “when to use” descriptions. Ordering assumptions stay implicit. Tool selection works fine in isolation, but becomes unpredictable once everything is connected.
The problem is coordination.
Hierarchical tool-calling changes that dynamic. Instead of a flat set of competing skills inside a single prompt, responsibilities are organized. Clear prerequisites replace long prose. Ordering constraints become machine-enforceable rather than implied.
The result is immediate: behavior becomes more predictable as the system scales.
The same discipline applies to internal handoffs.
Generating handoff prompts with an LLM introduces unnecessary variance and latency.
A simpler pattern works better: let the planner select the next agent and pass a compact, shared context.
It means:
- no generated handoff prompt,
- no reinterpretation layer,
- fewer tokens,
- less drift.
In one of our IT support automation projects, we reduced latency by several seconds by eliminating unnecessary instructions during the handoff. In applications with voice interfaces, for example, this kind of performance improvement can turn a solution from unusable into one that users rely on heavily.
Retrieval follows the same principle. When retrieval quality is poor, defaulting to RAG introduces noise. Broad context with loosely ranked chunks expands the reasoning space without improving correctness.
In practice, short, curated prompt “mini-docs” per category can outperform RAG when retrieval precision is low. They constrain reasoning rather than dilute it.
In fact, this approach recently allowed us to move from a simple RAG-based solution that didn’t even pass internal tests to a production-ready system, achieving an 85% user satisfaction score.
Separate content from presentation. Reduce ambiguity.
All of these adjustments share the same principle: before scaling evaluation or adding more skills, ensure the orchestration model is stable.
Otherwise, you are not scaling intelligence. You are experiencing scaling inconsistency.
The Payoff
Teams that sequence correctly see the difference immediately. They iterate faster early. They avoid rebuilding datasets after UAT. Their systems behave predictably as they scale.
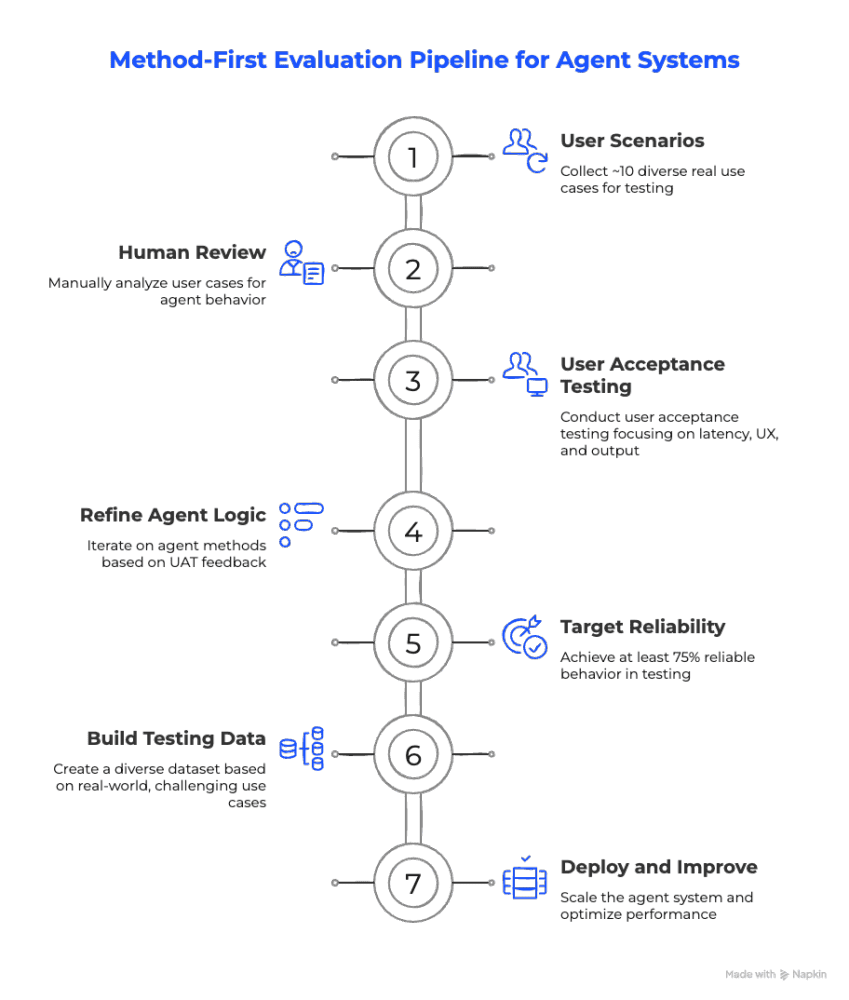
So, what to do?
- Start with ~10 real cases.
- Manually inspect structural failures.
- Let UAT challenge the method.
- Reach >75%+ reliable behavior.
- Then scale evaluation.
At that point, datasets reinforce something stable. Optimization compounds value. Architecture scales without collapsing under its own weight.
Data scales confidence. Correctness begins with the method.
Table of contents