
Last week we wrote about multidimensional linear models. We discussed a case in which a k-dimensional vector of the dependent variables is related to a grouping variable. We look at matrices E and H in order to find out whether there is any relationship (see the previous blog).
Table of contents
We still haven’t solved one problem, though. The dependent variable has k dimensions so the matrices of H and E effects have kxk dimensions. As a result these matrices can be viewed on a plot only when they are projected onto some two-dimensional space. But which two-dimensional subspace should we choose? We can try various projections of E and H matrices but is any of them better than the others?
Let us remember that our goal is to see whether the subgroups of the independent variable really diversify the multidimensional dependent variables. So, we will reduce dimension in the dependent variables so as to preserve the greatest between groups variation (groups determined by the independent variable).
Canonical discriminant analysis is a very popular technique used to perform such reduction of dimension. It identifies orthogonal vectors in the dependent variable space which explain the greatest possible between-group variation. If we choose the first two coordinates, we will get a subspace in which the analyzed groups are characterized by the highest between group variation. Now we can compare matrices H and E in this particular subspace. R program obviously has (many) packages allowing for simple construction of CDA. The one I used is called candisc.
We need to load the data, select only the data concerning Poland and build a multidimensional linear model (like the one we built a week ago).
library(PISA2012lite) pol = student2012[student2012$CNT == "Poland",] model = lm(cbind(PV1MATH, PV1READ, PV1SCIE)~ST28Q01+ST04Q01, pol)
Next, using the candisc function we perform CDA analysis for the chosen grouping variable (you can choose only one variable) and we build a HE plot for this variable.
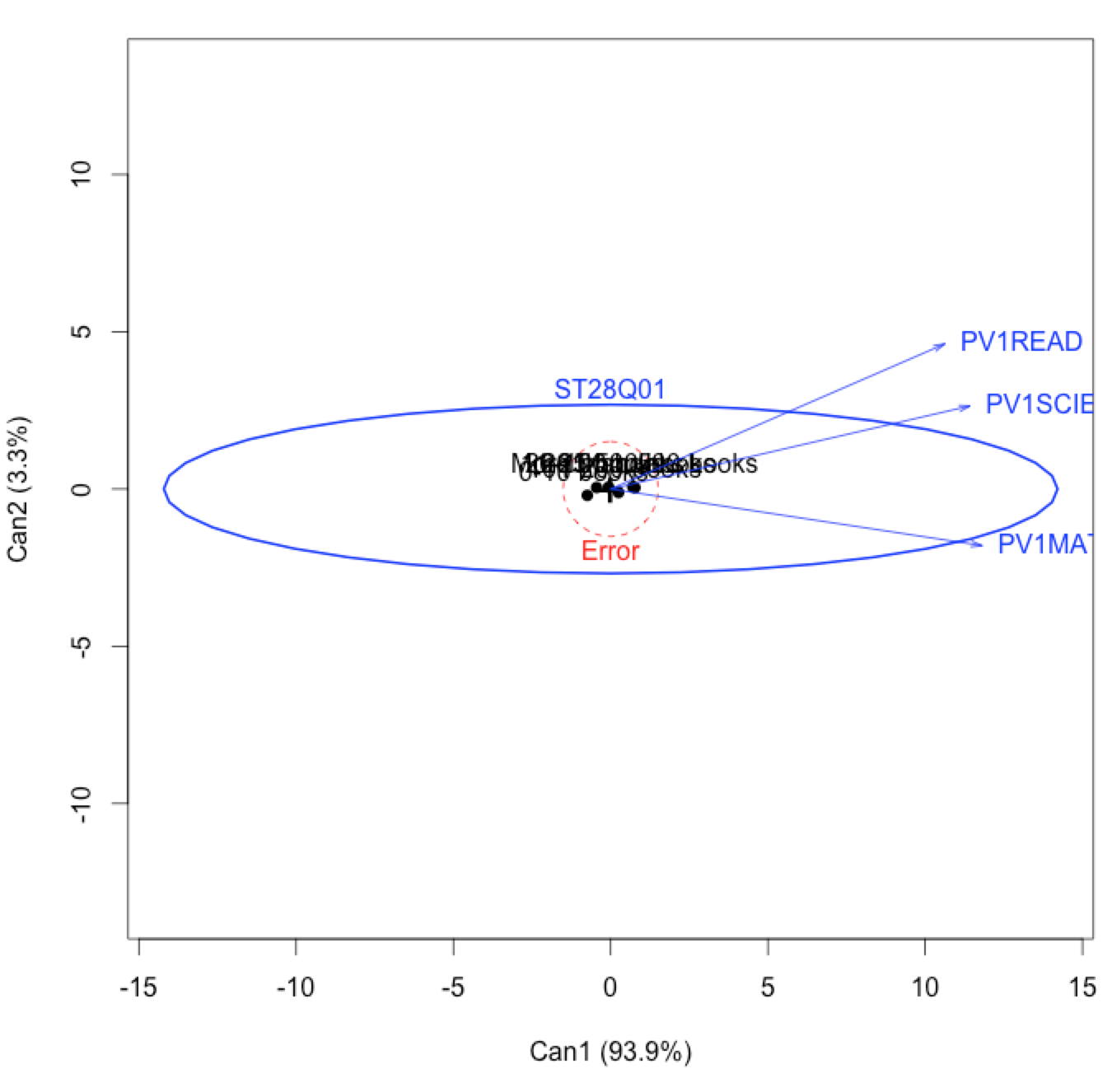
library(candisc) model2 = candisc(model, "ST28Q01") heplot(model2)
Matrices H and E were transformed on the plot –they were multiplied by E^{-1} on the right side. As a result we can see HE^{-1} and a unit matrix. Where does this transformation come from? It is much easier to compare the blue effect ellipsis to a circle than to another ellipsis. The diagram presented above suggests that the three dimensions of the dependent variable are strongly correlated along the axis differentiating the groups of ST8Q01 variable (code for number of books at home).
Notice that if the variable has got two levels (such as gender) we need only one dimension to achieve maximum linear separation. This is why the canonical components of such variables are one-dimensional and the corresponding HE plots look in the following way.
model3 = candisc(model, "ST04Q01") heplot(model3)
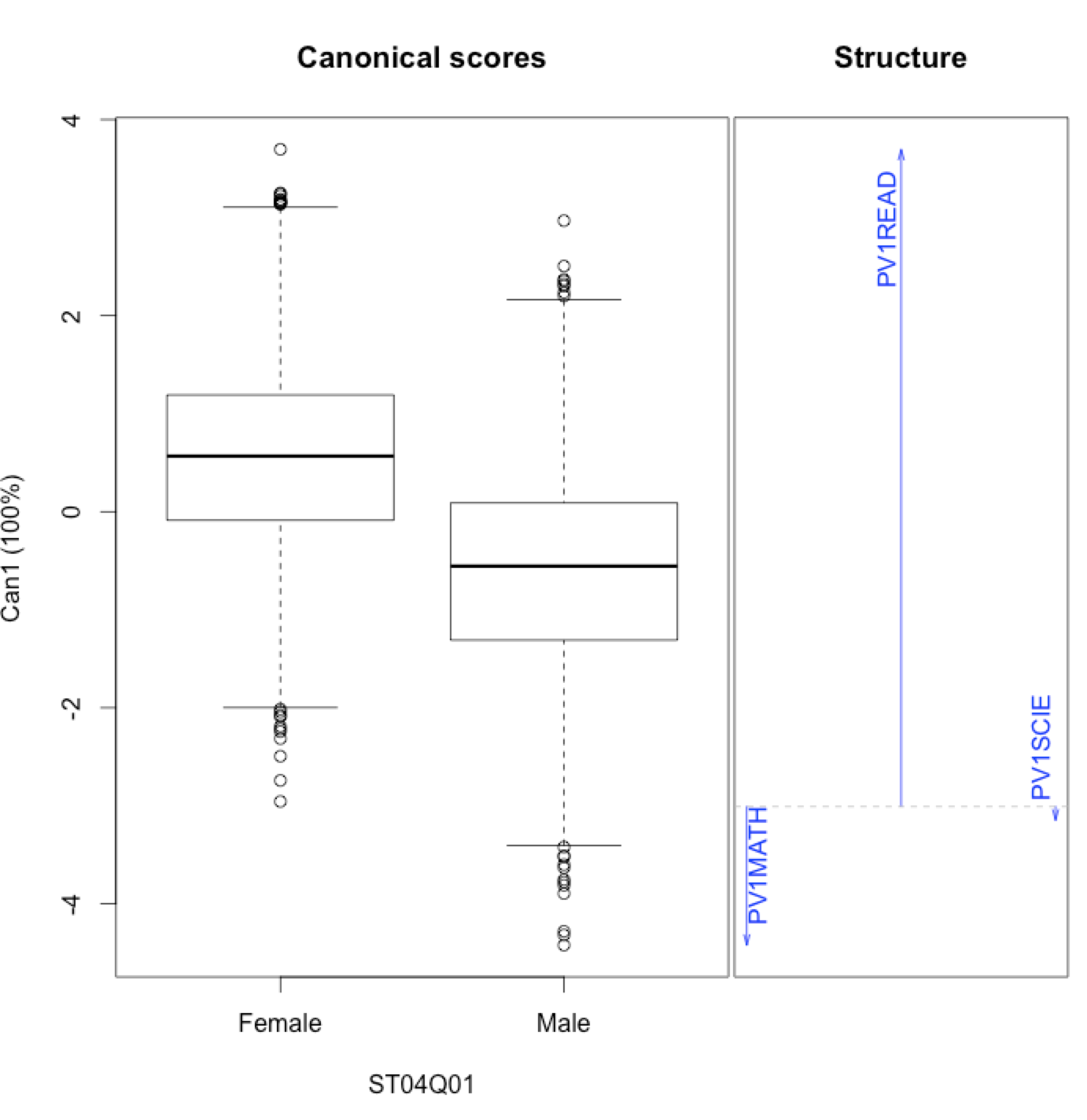
The figure on the right hand-side shows that the first canonical component is mostly influenced by reading comprehension component and also that this component is most strongly diversified by gender.
More information:
- Visualizing Generalized Canonical Discriminant and Canonical Correlation Analysis
Michael Friendly and John Fox - Canonical Variate Analysis and Related Methods with Longitudinal Data
Michael Beaghen
Przemyslaw Biecek





