
Table of contents
Diffusion models operate in a generative capacity that empowers them to create images using varying data sources. The resultant outputs are of impressive quality, and in some instances, they attain a photorealistic standard. However, to harness these newly generated data for the purpose of training supervised models, it requires the use of labels. These labels play an integral role in identifying the elements contained in an image and are an essential tool in training learning models to recognize various objects. One of the most challenging tasks is generating labels intended for semantic segmentation – deciphering which pixels in an image are associated with specific objects. At deepsense.ai, we have embraced the challenge of devising a novel approach that simultaneously generates images complete with precise segmentation masks. We are sharing the results of our work below.
Table of contents
Demanding data for semantic segmentation
Obtaining segmentation masks is a challenging process. Even though advanced tools for automatic labeling exist, such as Label Studio or CVAT, they have certain limitations. Recently Meta AI was in the spotlight with the introduction of a groundbreaking new model, the Segment Anything Model (SAM) [1], along with the SA-1B Dataset consisting of 11m images with 1.1bn mask annotations. Despite the availability of this extensive dataset, there remains a persistent need for customized datasets tailored to specific, often niche tasks.

The ability to generate large, annotated datasets is critical in effectively training deep-learning models for semantic segmentation. Objects within images can have a wide range of appearances, such as varying shapes, sizes, and colors. This variability can make it difficult for automated segmentation algorithms to consistently identify and segment objects, especially when objects have overlapping or ambiguous boundaries. We often deal with high-quality images depicting many objects of diverse classes. Thus, it is still common to label them manually. Unfortunately, this is time-consuming, and therefore expensive.
Data generation before diffusion models
Many researchers and Data Science practitioners have faced up to the challenge of overcoming the above-mentioned limitations. Their methods take advantage of the power of deep neural networks and GANs to generate high-quality images with accurate segmentation masks.
Generative Adversarial Networks (GANs) have shown impressive results in generating high-quality images that resemble real-world images. However, generating images with accurate segmentation masks has remained a challenge. Traditional methods for generating segmented images require separate models for segmentation and image generation, leading to slower and less efficient processes.
In “DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort”, Zhang et al. [2] demonstrated how the latent code of GANs can be deciphered to produce a semantic segmentation of the image. When trained to generate images, GANs must acquire a sophisticated understanding of the semantics of objects in order to produce diverse and lifelike examples. Researchers used a pre-trained GAN to generate a few images, which were then labeled by a human annotator. The next step was to train a simple ensemble of MLP classifiers on the feature vectors of the GAN to interpret the knowledge in the pixel feature vector into the pixel label.

To improve the accuracy and efficiency of semantic segmentation, researchers are investigating novel approaches that leverage recent advances in deep learning. One of the areas of focus for researchers is the integration of multimodal inputs, such as using both RGB images and text prompt, to improve the creation of segmentation masks. By combining these inputs, researchers hope to capture more comprehensive information about the scene.
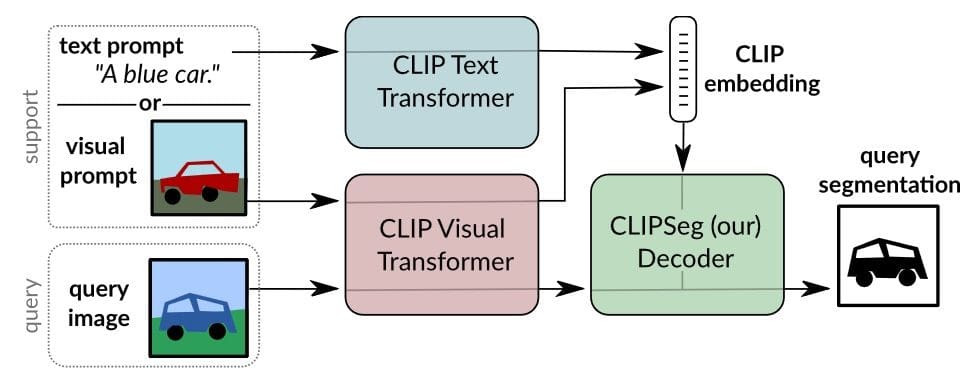
One of the most interesting proposals modifies the CLIP model. CLIPSeg [5], proposed by Timo Lueddecke and Alexander Ecker, can generate image segmentations based on arbitrary prompts at test time, including text or image prompts. The system extended the CLIP to include a transformer-based decoder for dense prediction. It enables a unified model for three common segmentation tasks: referring expression segmentation, zero-shot segmentation, and one-shot segmentation. The system was trained on an extended version of the PhraseCut dataset. It is capable of generating a binary segmentation map for an image based on a text prompt or an additional image expressing the query.
Generation of images with segmentation masks using diffusion models
More recent approaches to data and annotation creations touch on the topic of Stable Diffusion or simply parts of its architecture. We have covered the exciting subject of diffusion models and how to use them in our comprehensive earlier post, and we highly recommend checking it out here [3] and [4] to dive deeper into this topic.
One such idea worth mentioning is the DiffuMask [6] technique, which utilizes attention maps generated by the diffusion model to create highly realistic images with corresponding mask annotations. It employs cross-attention information guided by text to pinpoint regions specific to certain classes or words.
At deepsense.ai, we took a different approach to exploiting the incredible capabilities of diffusion models to generate data. Our approach involves integrating an extra component into the Stable Diffusion architecture to generate segmentation masks alongside images during the creation process. This additional component operates on the hidden states of the Stable Diffusion autoencoder, producing the corresponding segmentation mask. Notably, the extra component can be trained independently of the original autoencoder, leading to more efficient training. Additionally, the model may be lightweight as it leverages some of the weights from the original decoder.
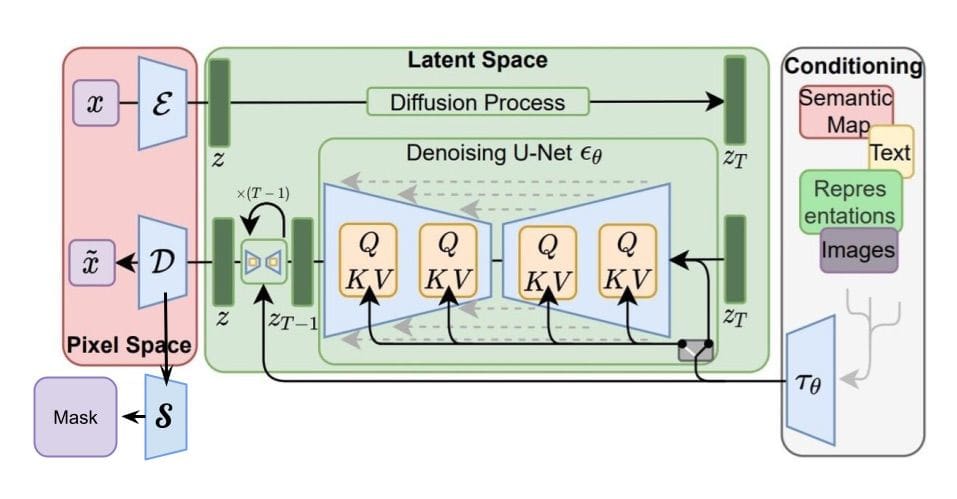
The visual description of the proposed approach is shown in the above figure. The crucial parts of the Stable Diffusion are not changed. The segmentation component is integrated with the VAE decoder.
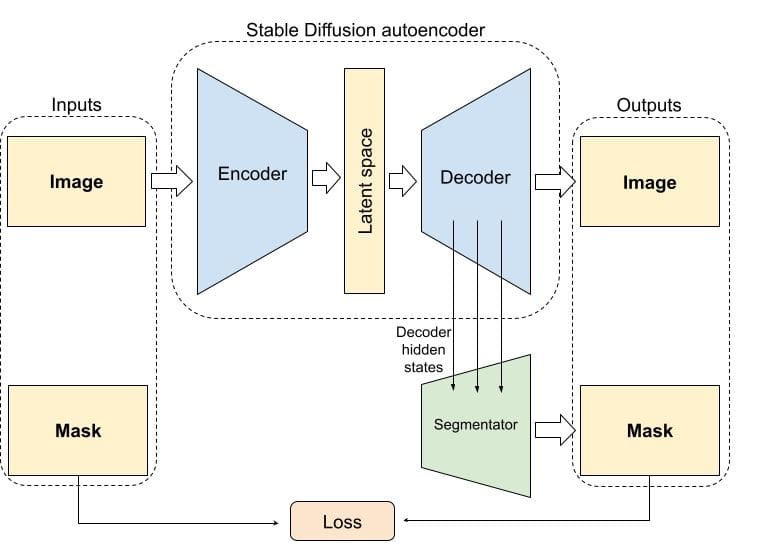
The training procedure of our approach is shown in Fig. 5. Our training process involves a pair of input data: an image and its corresponding segmentation mask. The image is encoded into a latent space and then decoded by the Stable Diffusion autoencoder. The hidden states of the decoder are then passed through the Segmentator module to generate the segmentation mask. The goal of the training is to teach the model to generate output masks that are similar to the input masks. During the training, only the Segmentator module is trained, and the weights of the Stable Diffusion autoencoder are frozen.
By using this approach, we are able to efficiently train the segmentation module while leveraging the power of the pre-trained autoencoder. This technique significantly reduces training time and computational complexity in comparison to the training of the external segmentation model.
Pet dataset
We started with simple photos of pets from the Oxford-IIIT Pet Dataset [8]. This dataset contains several thousand images of cats and dogs with corresponding segmentation masks. We trained our model to accurately reproduce the segmentation masks of pets. Following the completion of the training process, we were able to successfully generate pairs of images and corresponding segmentation masks. The results below demonstrate the ability of our model to identify the pets in the image:

While it performs well for simple examples, it remains to be seen how well it fares in more complex scenarios. Let’s explore its effectiveness in more intriguing cases.

Cityscapes dataset
While generating pets may be a relatively straightforward task with limited practical applications, our approach can also be extended to much more complex scenarios. Let’s investigate its effectiveness in the context of urban scenes.

We focus on the Cityscapes dataset [9], which is widely used in computer vision tasks. The dataset contains several thousand images from a few cities in Germany. Each image is annotated with pixel-level semantic labels for 30 different object categories. The images from this dataset have unique characteristics, such as lightning or the layout, which rule out the possibility of completing data from other urban datasets. But by using the presented approach, we can generate any number of annotated data exactly in the style of Cityscapes.
To do this, we need to train not only the segmentation module but also retrain Stable Diffusion to be able to generate pseudo-Cityscapes images. We accomplish this by training the LoRA model described in our previous blog post [3].
In the table below, we present the results for newly generated images with corresponding masks:

Combining the different diffusion model methods, we are able to generate the annotated data in exactly the style we want!
Conclusions
In this post, we discussed different approaches to generating images along with segmentation masks. We proposed a novel method, which changes the original Stable Diffusion architecture by adding a Segmentator module. This custom approach enables us to reduce the training time needed in comparison to the external segmentation model with similar outputs.
References:
[1] Segment Anything, Meta AI Research
[2] “DatasetGAN: Efficient Labeled Data Factory with Minimal Human Effort” Zhang et. al.
[3] “Diffusion models in practice. Part 1: The tools of the trade”
[4] “Data generation with diffusion models – part 1”
[5] “Image Segmentation Using Text and Image Prompts” Lüddecke, Ecker
[6] ”DiffuMask: Synthesizing Images with Pixel-level Annotations for SemanticSegmentation Using Diffusion Models”
[7] https://deepsense.ai/wp-content/uploads/2023/07/2112.10752.pdf
[8]: https://www.robots.ox.ac.uk/~vgg/data/pets/ [9]: https://www.cityscapes-dataset.com/dataset-overview/





