
Table of contents
It is widely known that computer vision models require large amounts of data to perform well. The reason for this is the complexity of these tasks, which usually involve the recognition of many different features, such as shapes, textures, and colors. Therefore, to train state-of-the-art, advanced models, it is necessary to use vast datasets like, for example, ImageNet, containing 14 million images.Unfortunately, in many business cases we are left with a small amount of data.
Table of contents
Small datasets may be due to the high cost of data collection, privacy concerns, or the limited availability of data. This causes various problems such as underrepresentation of the rarest classes, being prone to overfitting and the limitations of the machine learning algorithms or deep learning models that can be used.
When working with limited data, it can be difficult to train a model that is accurate and generalizes well to new examples. There are several approaches to overcoming the issue of insufficient data, one of which is supplementing the available dataset with new images, which is discussed in this article.
Diffusion models to the rescue
Diffusion models are a class of generative models that have become increasingly popular in recent years due to their ability to generate high-quality images. At a high level, diffusion models work by firstly adding a certain amount of random noise to the images from the training set. Then the reverse process happens, that is, during training the model learns to remove the noise to reconstruct the image. The advantage of this approach is that it allows the model to generate high-quality samples that are indistinguishable from real data, even with a small number of training examples. This is particularly useful in situations such as in medical imaging, where obtaining high-quality images is expensive and time-consuming. Popular diffusion models include Open AI’s Dall-E 2, Google’s Imagen, and Stability AI’s Stable Diffusion.
You can read more about the recent rise of diffusion-based models in our recent post.
Related Work
In recent years, there has been growing interest in the application of diffusion-based models in creating new images based on those which already exist. Many architectures modify the baseline to achieve the best quality of output. Below we discuss a few of them, to give you an overview of what can be accomplished.
Medfusion
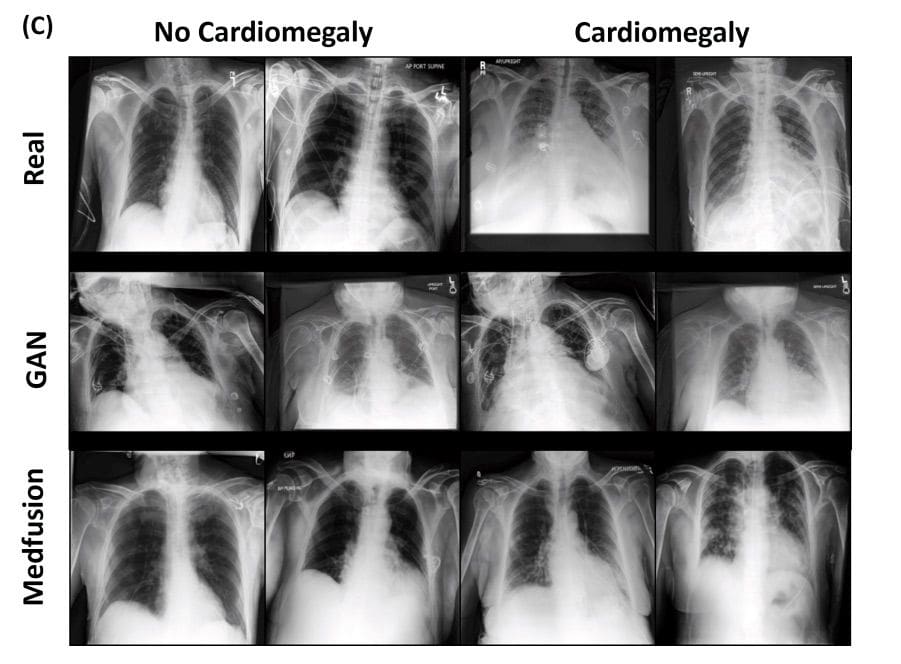
One of the fields where there is a need to complement datasets is medical imaging. The use of real patient data is encumbered with privacy and ethical concerns. What is more, there is a lack of process standardization when it comes to sharing sensitive data, even between hospitals and other medical research facilities. To overcome the barrier of privacy issues and a lack of available medical data, Medfusion architecture was proposed by Muller-Franzes et al. in [1].
In the past, it was common to use generative adversarial models (GANs) to generate data based on existing training data. However, it has been proven that GANs suffer from unstable training behavior, among other things [2].
In [1] the authors present a novel approach based on Stable Diffusion [3]. The model consists of two parts: an autoencoder and a Denoising Diffusion Implicit Model (DDIM). The autoencoder compresses the image space into a latent space. During training, the latent space is decoded back to the image space. Then they use a pre-trained autoencoder to get the image to the latent space which is then diffused into Gaussian noise. A UNet model is used to denoise the latent space, and samples are generated with the DDIM. During their research they first investigated whether the autoencoder was sufficient to encode images into a compressed space and decode them back without losing medically relevant details. Then they studied whether the Stable Diffusion Model’s autoencoder, pre-trained on natural images, could be used for medical images without further training. The results showed that the Medfusion model was effective in compressing and generating images while retaining medically relevant details, and the Stable Diffusion Model’s pre-trained autoencoder could be used for medical images without the loss of any relevant details, and could outperform GANs in terms of the quality of output images. The study highlights the potential of the Medfusion model for medical image compression and generation, which could have significant implications for healthcare providers and researchers.
They explored three domains of medical data: ophthalmologic data (fundoscopic images), radiological data (chest x-rays) and histological data (whole slide images of stained tissue).
ControlNet
While working with diffusion models, one can encounter the problem that the output changes even in terms of the parts of the picture that we would like to stay the same. In the case of generating new images to supplement the existing dataset, we would prefer, e.g., the semantic masks or the edges (possibly obtained by Canny or Hugh lines detector) that we already have to still apply to the newly created image.

In the article “Adding Conditional Control to Text-to-Image Diffusion Models” by Lvmin Zhang and Maneesh Agrawala [4], ControlNet architecture is presented in more detail. ControlNet makes it possible to augment Stable Diffusion by making use of additional inputs like segmentation masks, keypoints or edges. The architecture makes two copies of the network – one locked and the other one trainable. The locked copy preserves the network capability learned from billions of images, while the trainable copy is trained on task-specific datasets to learn the conditional control. The trainable and locked neural network blocks are connected with a layer called “zero convolution”. Training using the zero convolution is efficient because it does not introduce any new noise to deep features. Consequently, it is just as fast as fine-tuning a diffusion model, as opposed to starting the training process from scratch when new layers are added.
The authors trained several ControlNets with various datasets of different conditions, such as Canny edges, Hough lines, user scribbles, human key points, segmentation maps, shape normals, and depths. The results showed that ControlNet was effective in controlling large image diffusion models to learn task-specific input conditions.

Data augmentation with diffusion models – DA-Fusion
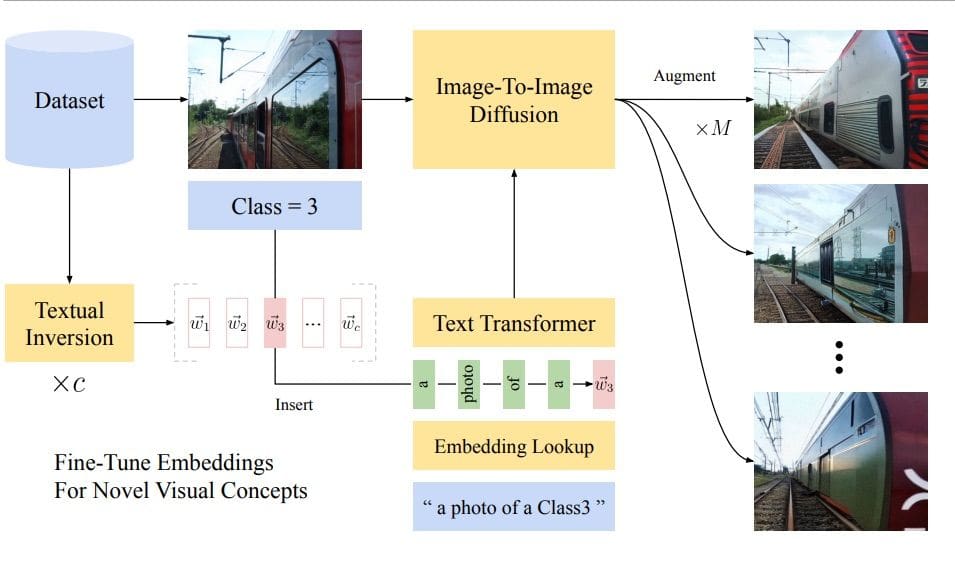
Standard data augmentation techniques are image transformations such as flips, rotations or changes in color. Unfortunately, they do not allow more sophisticated changes in the appearance of the object. Suppose we would like to have a model detect and recognize a plastic bottle in the wild, e.g., while creating a waste detector – it would be very helpful to be able to vary the appearance of the bottle in terms of the label or the color of the bottle, etc. Unfortunately this is not possible with classical data augmentation. The DA-Fusion [5] method, based on text-to-image diffusion models, was proposed to address this issue.
The authors utilize pre-trained diffusion models to generate high-quality augmentations for images, even those with visual concepts not previously known to the base model. In the text-encoder, new tokens were used to adapt the diffusion model to new domains. In order to do so, Textural Inversion [6] was applied – a technique for capturing novel concepts in the embedding space of a text encoder.
Our interest
At deepsense.ai we strongly believe that data is crucial to the performance of machine learning models. Therefore, we are constantly searching for new approaches to make the most of the data that we have available. Recently, we have been exploring the use of generative models as well as novel diffusion models and variations thereof.
Stay tuned for our next post to find out more about our approach to applying these methods to synthesizing datasets from different domains (i.e. medical images, street view) for classification and segmentation tasks.
Bibliography
- [1] “Diffusion probabilistic models beat GAN on medical 2D images” Gustav Müller-Franzes et al., 2022
- [2] “What is going on with my GAN?” Fabiana Clemente, 2020 https://towardsdatascience.com/what-is-going-on-with-my-gan-13a00b88519e
- [3] “High-Resolution Image Synthesis with Latent Diffusion Models” Robin Rombach et al., 2021
- [4] ”Adding Conditional Control to Text-to-Image Diffusion Models” Lvmin Zhang et al., 2023
- [5] “Effective Data Augmentation With Diffusion Models” Trabucco et al., 2023
- [6] “An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion” Rinon Gal et al., 2022





