

Achieving accurate image segmentation with limited data: strategies and techniques
Harnessing the power of deep learning for image segmentation is revolutionizing numerous industries, but often encounters a significant obstacle – the limited availability of training data. Collecting a large, diverse, and accurately annotated dataset consisting of pairs of images and corresponding segmentation masks can be time-consuming, expensive, and challenging due to privacy concerns.
Fortunately, in 2023 we underwent a minor revolution in the task of image segmentation. It all began with the Segment Anything Model (SAM) from Meta AI, followed by rapid advancements in zero- and few-shot image segmentation. These approaches aim to provide accurate segmentation without access to extensive datasets, reducing the costs and time of implementation.
In this blog post, we will explore techniques and strategies that leverage the latest advancements in the field to address the challenges of image segmentation with limited training data.
Fundamental concepts
Before delving into the methods, it is essential to refresh our knowledge regarding the concepts that will be useful for our discussions.
Image segmentation
Image segmentation involves partitioning images into multiple segments or objects. This task has applications in various fields such as medical analysis, autonomous driving, and augmented reality. Typically, we can classify segmentation tasks into four categories:
- Semantic Segmentation aims to associate a label with every pixel in an image.
- Instance Segmentation involves segmenting every instance found by the object detector. However, we are not interested in segmenting uncountable entities like the sky or grass.
- Panoptic Segmentation integrates both instance and semantic segmentation, providing a holistic understanding of an image by assigning each pixel a semantic label and an instance identifier.
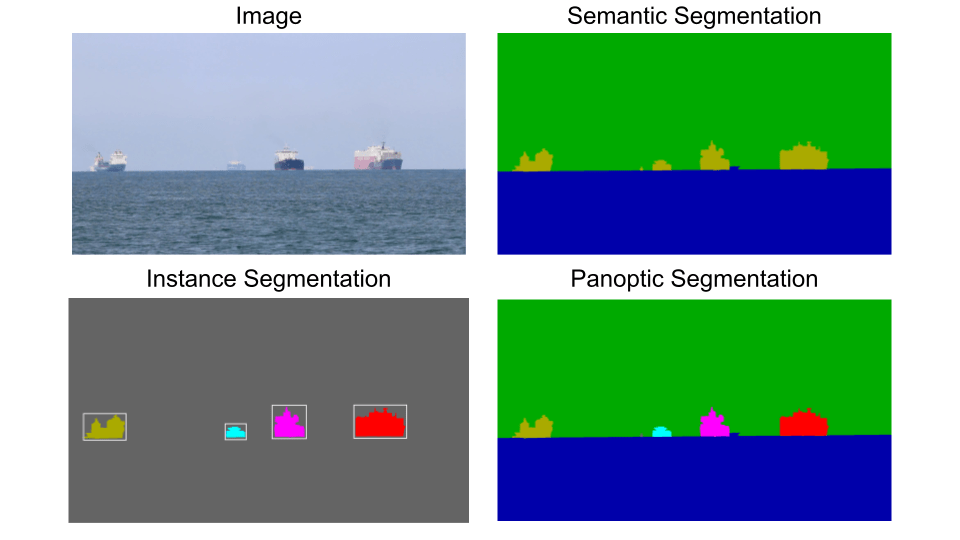
Figure 1. Different segmentation types. Source: own study.
Supervised learning
Supervised learning is a widely used approach in machine learning, where algorithms are trained using a large number of input examples paired with their corresponding expected outputs. In the case of image segmentation, this involves providing raw images as input and the corresponding segmentation masks as the expected output. The algorithm learns from these examples and aims to find a function that can accurately transform the input images into the expected segmentation masks. Over the years, various successful deep learning architectures have been developed for this task, such as U-Net or SegFormer.
In numerous scenarios, communities have successfully collected large amounts of data covering the full distribution of expected inputs, leading to impressive results in image segmentation. However, in many real-world use cases, gathering a significant amount of data is infeasible, resulting in the suboptimal performance of supervised learning.
Zero-shot learning
Zero-shot learning aims to solve classification, image segmentation, and other tasks for classes that were not observed during training. Instead, we rely on descriptions of these classes or tasks. This technique is based on knowledge transfer, which is already contained in the concepts learnt during training. For example, if our training dataset includes horses and the concept of stripes, a zero-shot learning system should have the capability to recognize zebras.
Recently, the most popular approaches have utilized natural language as a proxy for describing new classes, exemplified by the CLIP model. The key idea behind CLIP is to leverage pre-training on a large amount of easily accessible Internet data consisting of images and their corresponding descriptions. The objective is to create embedding space for both text and images, where the embedding of the textual description of an image is close to the described image embedding. This is achieved through the use of contrastive learning.
Coming back to the zebra example, we could describe the concept of the zebra as follows: “A horse-like animal with black and white stripes”. The embedding of this description should be close to the images of zebras, allowing for classification based on the similarity. With common objects we can be even more direct and provide a prompt: “a photo of a zebra”.
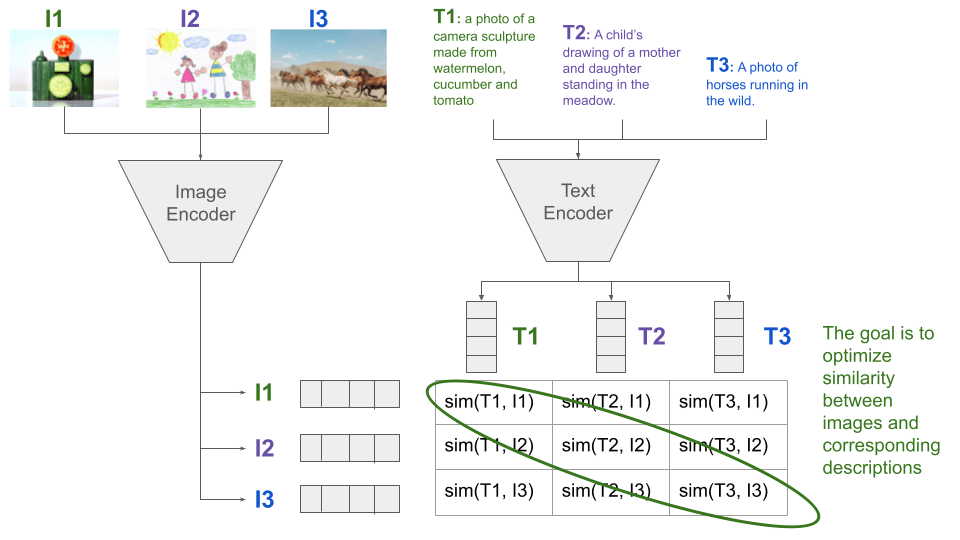
Figure 2. Illustration of the CLIP training process. Source: own study.
Few-shot learning
In the previous example, the model relied on abstract descriptions rather than labeled examples. Now, let’s explore few-shot learning, which involves having a small set of labeled images known as a support set. This support set is presented to the neural network, and the expectation is for the network to correctly classify unseen examples of the newly introduced concept.
In this scenario, when training a network with a large dataset, the objective is not simply to learn classification but rather to learn how to associate similarities and differences between objects. Few-shot learning is a bit simpler than zero-shot learning, but it still poses significant challenges. In the context of image segmentation, few-shot learning may be represented as follows:
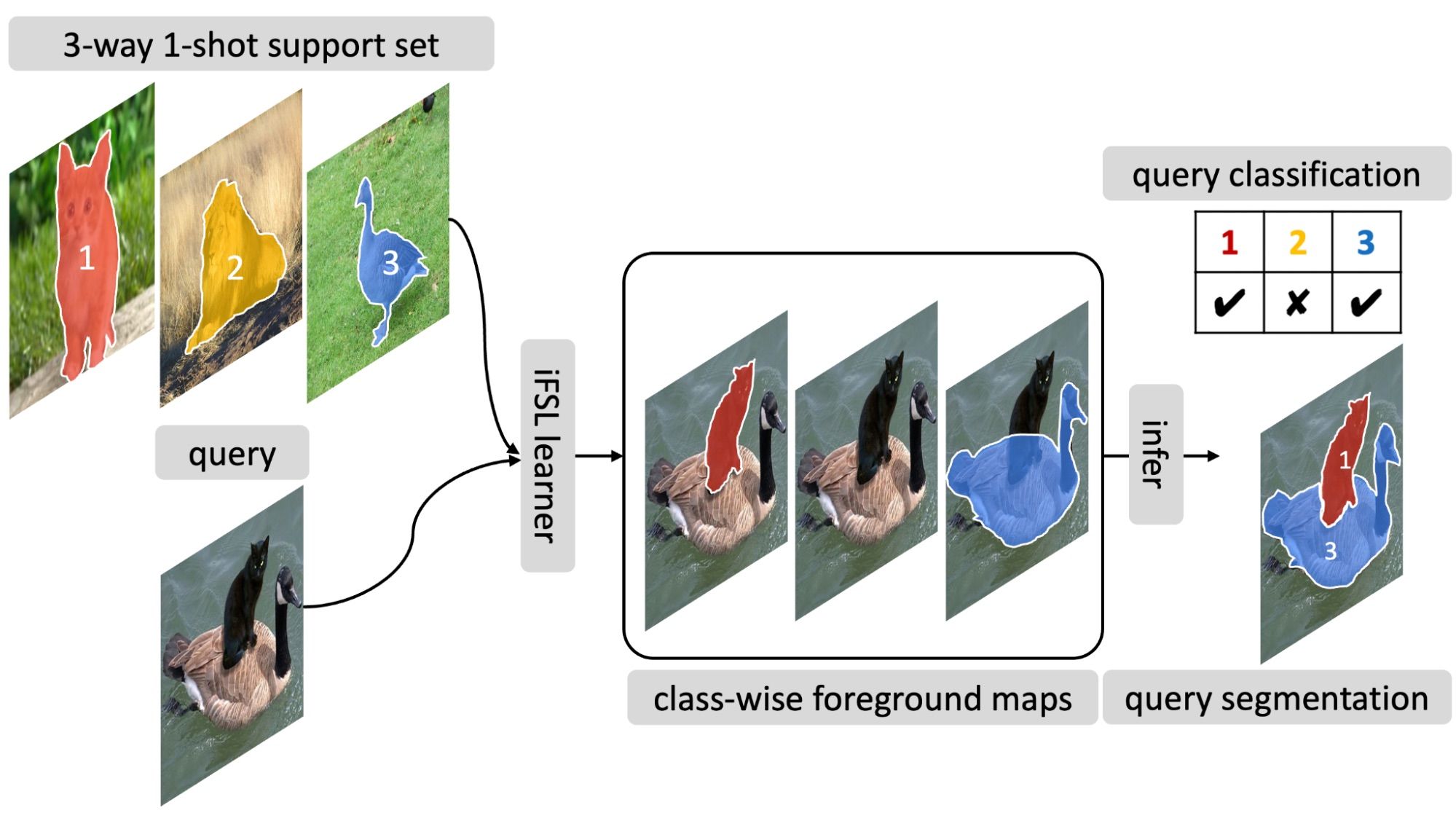
Figure 3. Illustration of a few-shot segmentation process. Source: https://arxiv.org/pdf/2203.15712.pdf.
Segment Anything Model (SAM)
Inspired by the success of prompting techniques utilized in the field of natural language processing, researchers from Meta AI proposed the Segment Anything Model (SAM), which aims to perform image segmentation based on segmentation prompts. These prompts can take various forms, such as a point, bounding box, initial binary mask, or even text, indicating what specific area of the image to segment.
To achieve this, SAM utilizes two encoders: one for encoding the image and another for encoding the prompt. The embeddings from both encoders are then connected and passed through the segmentation decoder to generate the segmented output. This modular approach allows the exchange or fine-tuning of all three models separately. Additionally, SAM brings computational efficiency through the reuse of embeddings. Once the embedding for a given image is calculated, it can be reused for every inference on that image. Only new prompt embeddings need to be computed, resulting in a faster overall process.
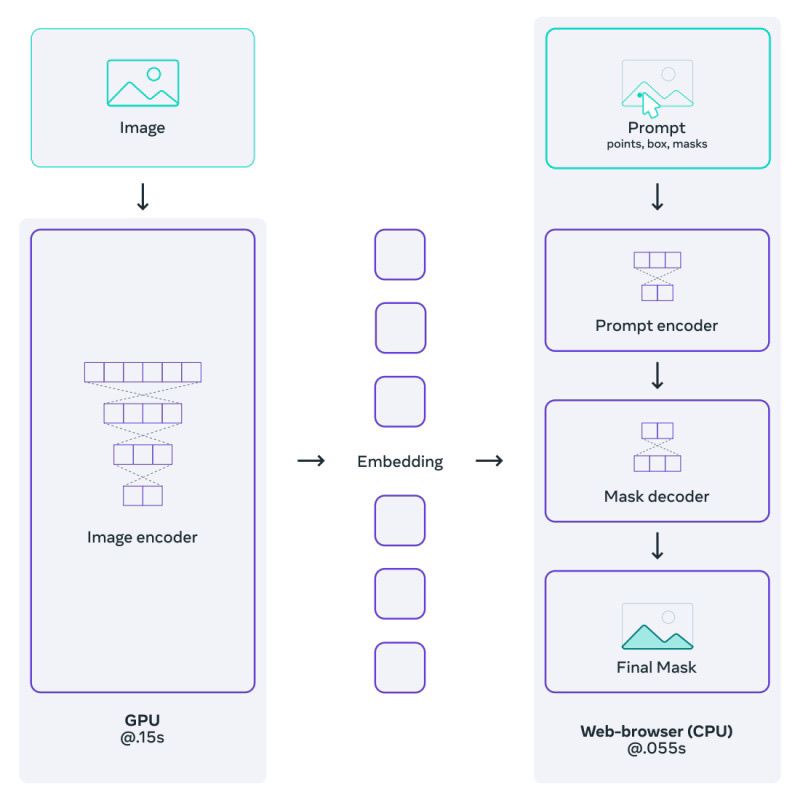 |
  |
Methods
Lang SAM and Grounded Segment Anything
After the introduction of SAM, several projects, such as LangSAM and Grounded SAM, have emerged with the goal of improving text-based prompts. The pipeline for this approach involves several steps. Initially, an image-text pair is processed through Grounding Dino, a zero-shot object detector that detects objects within the image and provides a set of bounding boxes. These bounding boxes, along with the corresponding image, are then fed into SAM, which generates segmentation masks.
Note that we still have to provide textual description. The entire process can be further automated incorporating automatic image tagging using modules like RAM or Tag2Text. Using an image tagger, one can automatically obtain the image description, which is subsequently passed to Grounding Dino. Grounded SAM provides many other nice features, like inpainting or voice-based prompts, and supports various versions of SAM, such as EfficientSAM and EdgeSAM. Unfortunately, this approach has one drawback – it is multistage. If any of the previous stages fails, there is no way to recover.
When using Grounded SAM, there are several important aspects to consider:
- Types of objects: Grounded SAM performs exceptionally well with common objects like umbrellas or cars. However, it may face challenges when attempting to segment specific types of objects, such as transistors on a circuit board. Additionally, be aware of the object detection process happening before segmentation, which makes the segmentation of patterns instead of objects very hard.
- Prompt engineering: the provided prompt plays a crucial role, especially when dealing with compound nouns. By using “car lamp” as a prompt, we are very likely to detect cars instead of car lamps. Using “headlight” as a prompt may be better. Moreover, remember to separate classes with a dot, which is treated as a sentence separator. For example, the prompt “egg. banana. apple. orange.” should be used instead of “egg, banana, apple, orange.”
 |
 |
SEEM
While previous methods attempted to incorporate the original SAM into larger pipelines, numerous approaches have also emerged with the aim of improving the raw SAM. Examples include SAM-HQ, SemanticSAM, and SAM-Adapter, each targeting different aspects of the method.
One method that particularly caught our attention was SEEM (Segment Everything Everywhere All at Once), which extends SAM by introducing more types of prompts such as scribbles, audio, and images. SEEM also enhances text prompt handling and provides additional semantic labels. As in SAM, we can mix these prompts freely.
From our perspective, the most exciting capability of SEEM is its segmentation based on an exemplary image. This feature enables one-shot inference, where a reference image with the desired object’s mask is provided only once. Subsequently, any number of images containing the desired object can be processed without the need for supervision or additional prompting.
 |
 |
 |
SegGPT
Many successful approaches from NLP are now being translated into computer vision. For instance, the analogy of the masked token prediction task used to train BERT is known as masked image modeling in computer vision. Similarly, the capability of solving multiple tasks through next-token prediction in NLP can be transferred to CV by using image inpainting, the goal of which is to reconstruct missing regions in the image. Of course, don’t forget about the concept of few-shot inference, where one provides a few examples and then asks the model to solve a new example based on the context. It sounds like ChatGPT for images, and it is actually named SegGPT.
While training such a model is a complex topic on its own, using it for inference is relatively straightforward. First, we provide at least one example of how the task should be solved, consisting of an input image and its corresponding expected image mask. Then, we prompt the model with an input image and an empty image, and the model is expected to inpaint a mask on the empty image based on the previously shown examples.

Figure 7. Comparison of few-shot inference between NLP and CV. Source: own study.
Unfortunately, the amount of prompt we can provide to the SegGPT is limited, as we can simply run out of GPU memory. What if we were able to collect 50 images? Since we have already seen 3 inspirations from NLP, let’s go further and try to translate two more concepts.
The first concept is prompt engineering. In NLP, this refers to finding the most optimal text to feed the Large Language Model for enhanced performance. Analogously, in SegGPT, we can find the most effective image prompts from the training set. We can employ an approach similar to forward variable selection commonly used in classic Machine Learning. Starting with an empty prompt, we continuously expand it by adding images. We include those images that, when added to the prompt, result in the largest increase in performance accuracy on the validation set. We continue this process until there is no further improvement or until we reach the maximum capacity of our GPU memory.
The second approach is reminiscent of Retrieval Augmented Generation (RAG), where we aim to provide the best matches based on the actual query. In this case, we compute embeddings for all training images using any image encoder of choice. During the inference phase, we determine the most similar image from the training set as the prompt by comparing the input image embedding with precalculated embeddings.
The authors of SegGPT also propose a third strategy – learning the optimal prompt from the training data. This involves freezing the entire pretrained model and optimizing only the input context tensor.
PerSAM
Can we obtain good point prompts without human interaction? This is the question PerSAM tries to answer. Given a training instance (image, mask), it calculates the embedding of the masked region. During inference, it compares the embedding of the input with the one it has precalculated and looks for a region that is most similar to the one from the training image.
As this region is found, a point is placed here and the decoding stage of SAM is run. But this is not the end. After we obtain our first mask, we pass it as a prompt to SAM so that it can improve itself. In the third pass we calculate the bounding box from the returned mask and ask SAM to improve once again. If you are interested in this approach, two more studies try to improve upon it: Matcher and SamAug.
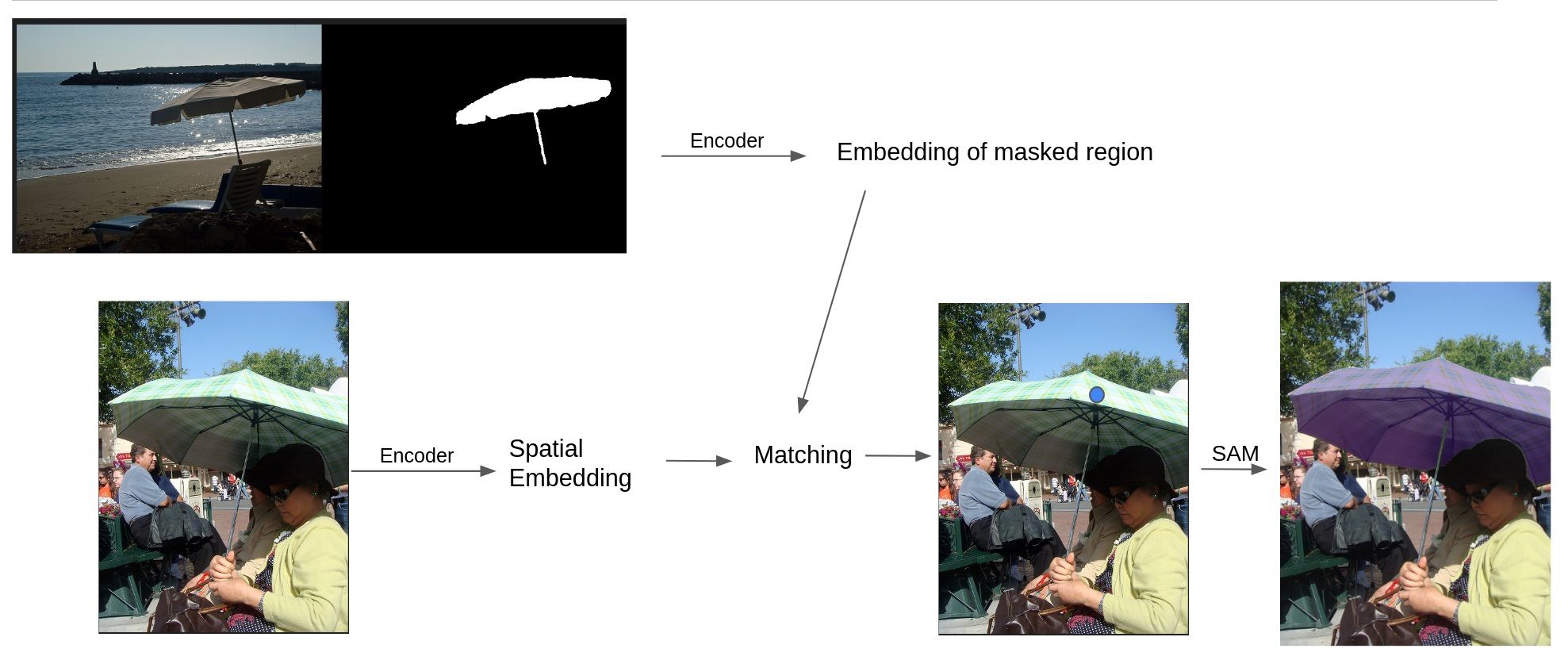
Figure 8. A diagram illustrating the operation of PerSAM. Source: own study.
ClipSeg
CLIP was created to combine knowledge of language concepts with semantic knowledge of images via embeddings. It soon became a vital part of models such as DALL·E 2 or Stable Diffusion. The fact that researchers tried to utilize it for image segmentation is nothing special; this is how ClipSeg emerged. This method can work in both zero- and one-shot scenarios, taking both image and/or text as a prompt. During inference, it calculates embeddings of the prompt utilizing a CLIP encoder and passes it to a transformer-based segmentation decoder. The biggest advantage of this method lies in its simplicity – it doesn’t parse prompts in a complicated way; it is end-to-end; and its backbone is a very well-known model.
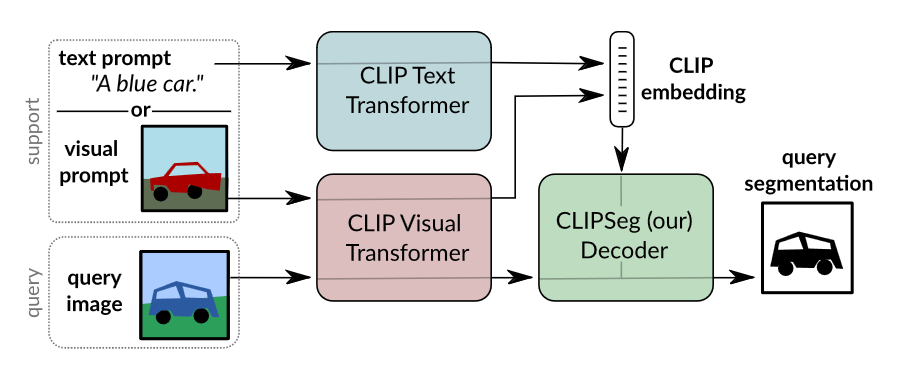
Figure 9. The ClipSeg pipeline involves the initial embedding of both the prompt and query into a unified representation, which is then input to the decoder. Source: https://arxiv.org/pdf/2112.10003.pdf.
Comparison
To facilitate the comparison of the models, we have prepared a table highlighting the differences between the presented methods. Each method is compared against the base Segment Anything Model (SAM), with each row representing a separate method and the columns representing the different capabilities of the models:
- Zero-shot: The model is capable of zero-shot inference given text, point, or bounding box inputs.
- Few-shot: The model is capable of making inferences given a few examples of how the task should be solved.
- Text: The model accepts text prompts.
- Image: The model accepts image prompts.
- More prompts: The model extends the set of prompts available in SAM.
- Prompt engineering: The model allows prompt engineering to improve performance.
- Instance segmentation: The model can perform the task of instance segmentation.
- End-to-end: There is only one stage of processing, and input is transformed directly into a mask.
- Modular: The model’s components can be easily exchanged without requiring retraining.

Figure 10. Comparison of all introduced methods from different viewpoints. Source: own study.
We also performed quantitative comparison using the task of umbrella segmentation, with the goal of determining the amount of training data required for the supervised model to achieve comparable accuracy to the zero-shot and few-shot learners. To evaluate the performance, we utilized the mean intersection over union (mIoU) metric, which is commonly used in image segmentation tasks. The mIoU metric quantifies the overlap between the model’s predictions and the ground truth labels. A value of 1 indicates perfect overlap, representing an excellent model, while a value of 0 indicates no overlap, indicating poor model performance.

Figure 11. Some examples from the dataset used for evaluation. Source: own study.

Figure 12. Experimental results for the umbrella dataset. Observe that we need thousands of instances to match the performance of zero-shot models. Source: own study.
Conclusions
The release of the Segment Anything Model has brought about a revolution in addressing data scarcity in image segmentation. Our experiment reveals that in certain cases, we can surpass the performance of a model trained on thousands of examples with absolutely no data. But what if objects and concepts to be segmented are not recognized by the zero-shot learners? In such scenarios, we can turn to the few-shot models with a little more effort. Exciting, isn’t it? So the next time you face an image segmentation problem, before spending weeks on data collection, spend a day exploring the techniques presented in this blog post, and hopefully the problem will be solved.
