
Table of contents
Distribute by and cluster by clauses are really cool features in SparkSQL. Unfortunately, this subject remains relatively unknown to most users – this post aims to change that.
Table of contents
In order to gain the most from this post, you should have a basic understanding of how Spark works. In particular, you should know how it divides jobs into stages and tasks, and how it stores data on partitions. If you ’re not familiar with these subject, this article may be a good starting point (besides spark documentation, of course). Please note that this post was written with Spark 1.6 in mind.
Cluster by/Distribute by/Sort by
Spark lets you write queries in a SQL-like language – HiveQL. HiveQL offers special clauses that let you control the partitioning of data. This article explains how this works in Hive. But what happens if you use them in your SparkSQL queries? How does their behavior map to Spark concepts?
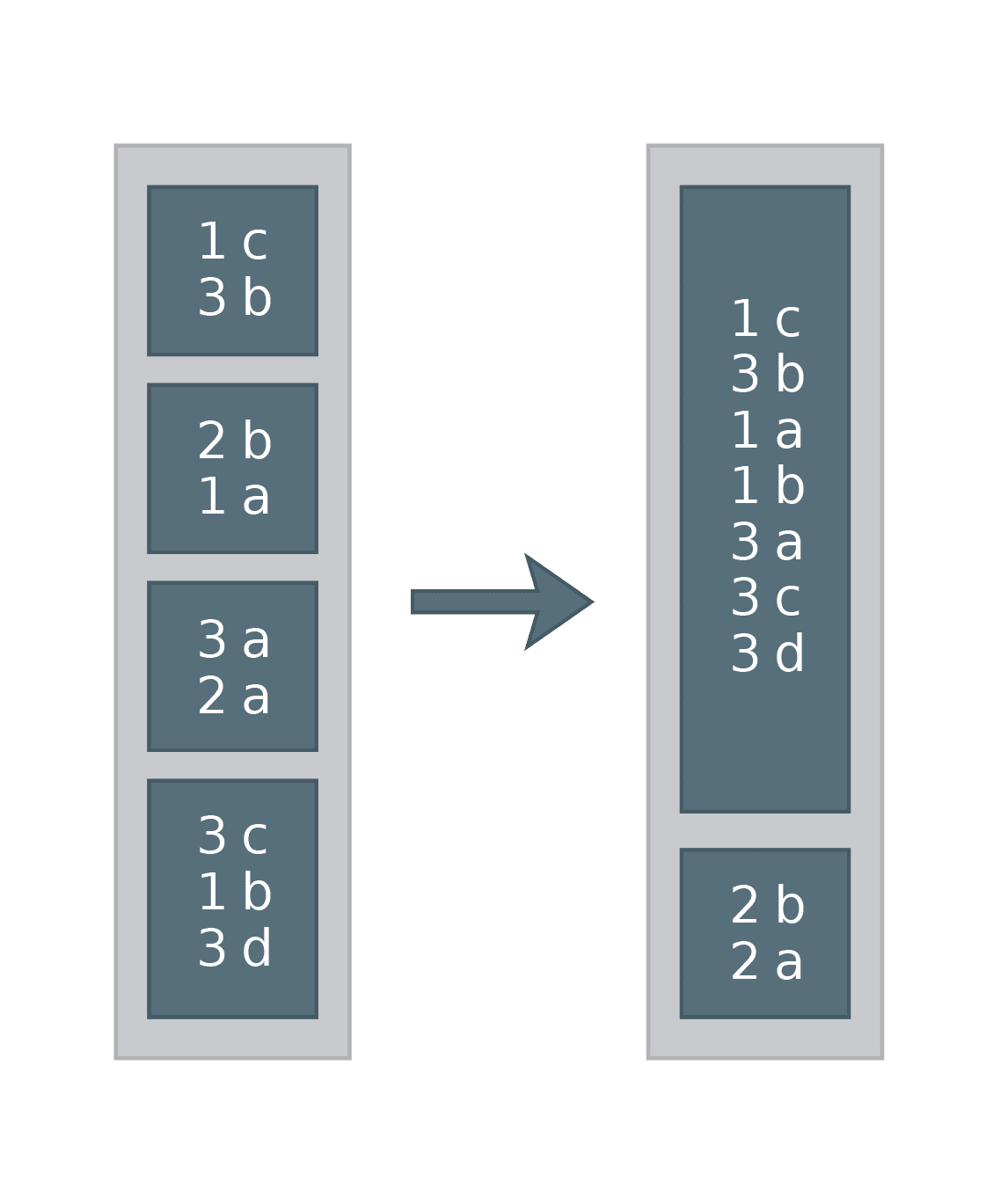
Distribute By
Repartitions a DataFrame by the given expressions. The number of partitions is equal to spark.sql.shuffle.partitions. Note that in Spark, when a DataFrame is partitioned by some expression, all the rows for which this expression is equal are on the same partition (but not necessarily vice-versa)! This is how it looks in practice. Let’s say we have a DataFrame with two columns: key and value.
SET spark.sql.shuffle.partitions = 2 SELECT * FROM df DISTRIBUTE BY key
Equivalent in DataFrame API:
df.repartition($"key", 2)
Example of how it could work:
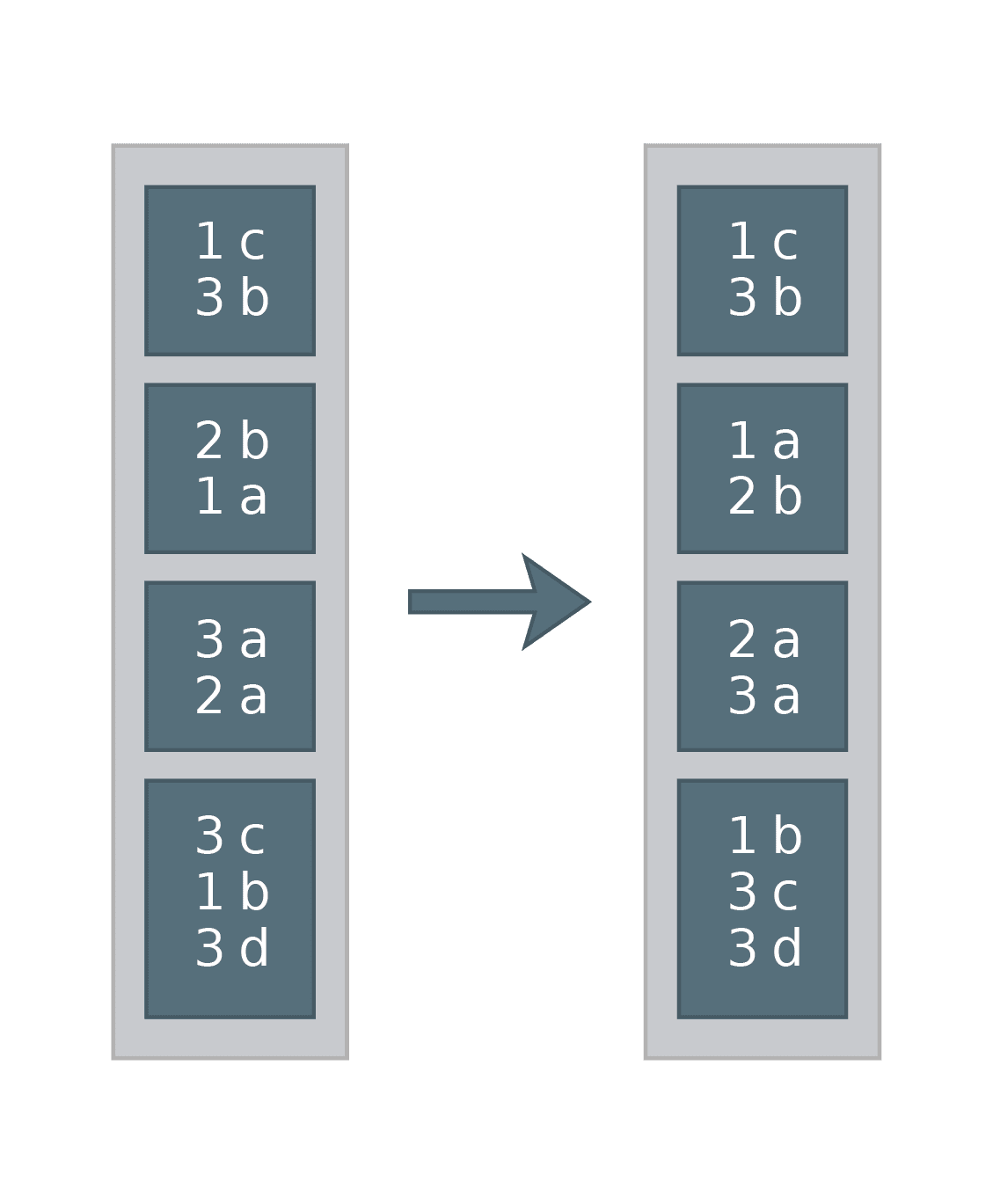
Sort By
Sorts data within partitions by the given expressions. Note that this operation does not cause any shuffle. In SQL:
SELECT * FROM df SORT BY key
Equivalent in DataFrame API:
df.sortWithinPartitions()
Example of how it could work:
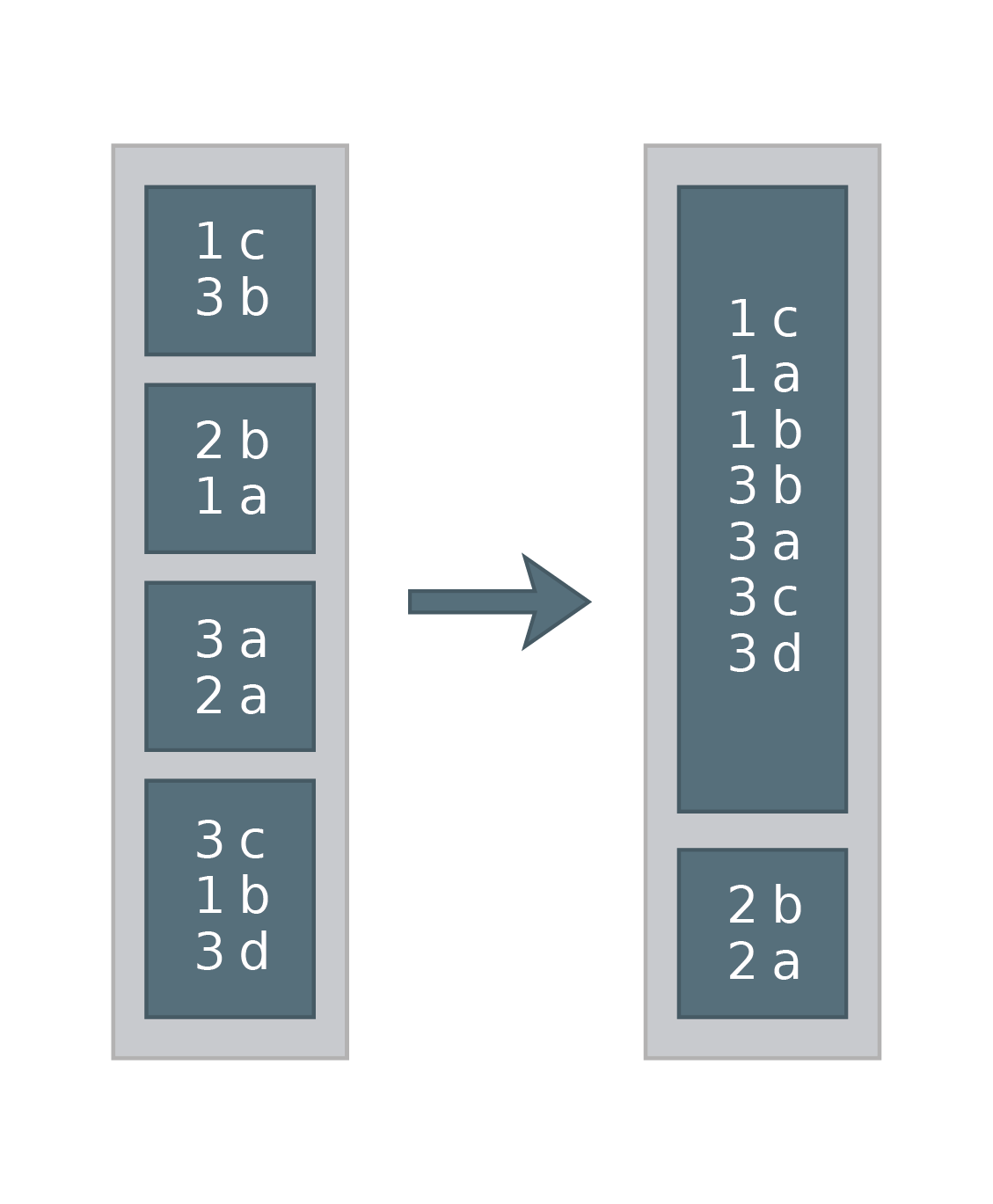
Cluster By
This is just a shortcut for using distribute by and sort by together on the same set of expressions. In SQL:
SET spark.sql.shuffle.partitions = 2 SELECT * FROM df CLUSTER BY key
Equivalent in DataFrame API:
df.repartition($"key", 2).sortWithinPartitions()
Example of how it could work:
When Are They Useful?
Why would you ever want to repartition your DataFrame? Well, there are multiple situations where you really should.
Skewed Data
Your DataFrame is skewed if most of its rows are located on a small number of partitions, while the majority of the partitions remain empty. You really should avoid such a situation. Why? This makes your application virtually not parallel – most of the time you will be waiting for a single task to finish. Even worse, in some cases you can run out of memory on some executors or cause an excessive spill of data to a disk. All of this can happen if your data is not evenly distributed. To deal with the skew, you can repartition your data using distribute by. For the expression to partition by, choose something that you know will evenly distribute the data. You can even use the primary key of the DataFrame!
For example:
SET spark.sql.shuffle.partitions = 5 SELECT * FROM df DISTRIBUTE BY key, value
could work like this:
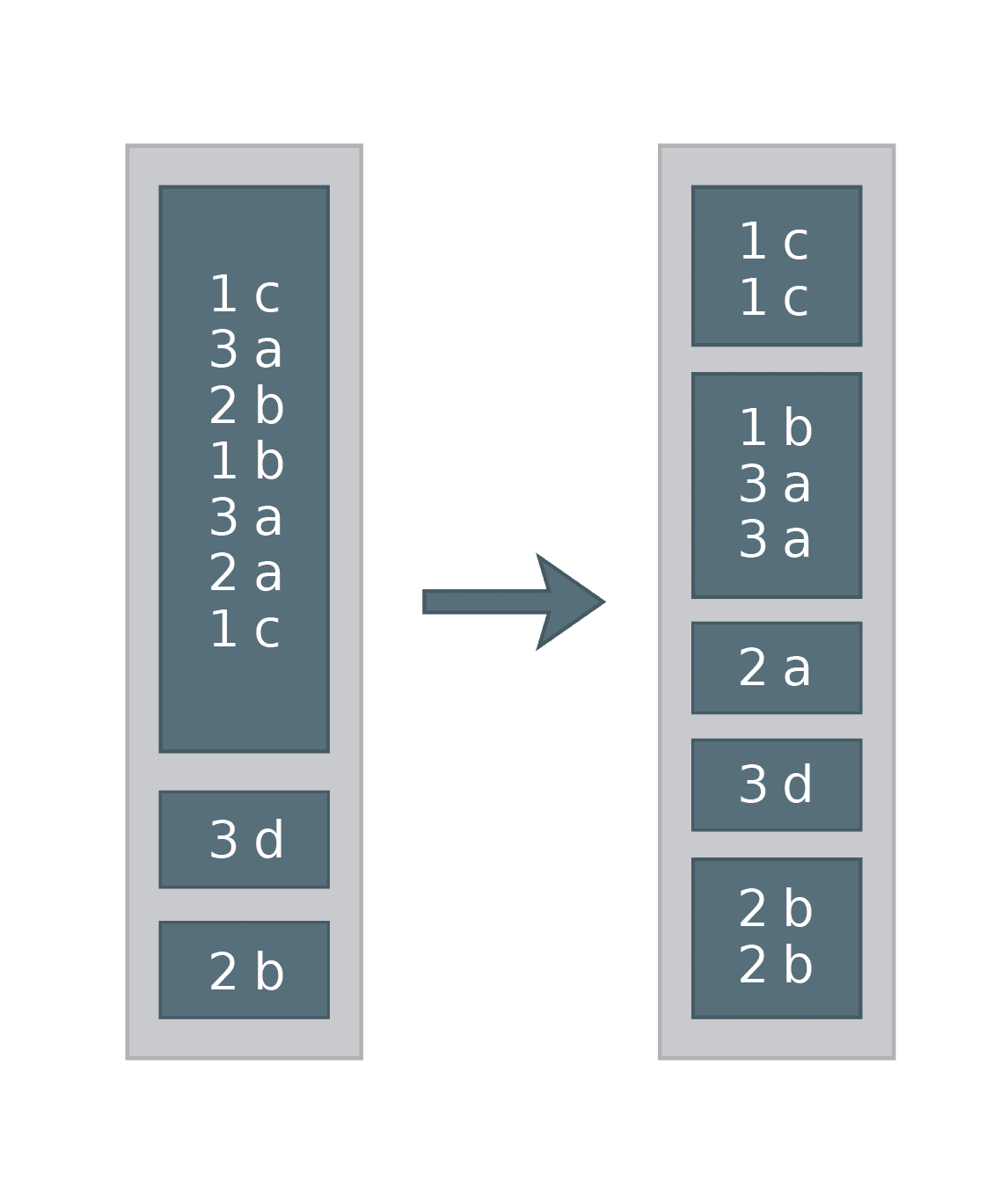
Note that distribute by does not guarantee that data will be distributed evenly between partitions! It all depends on the hash of the expression by which we distribute. In the example above, one can imagine that the hash of (1,b) was equal to the hash of (3,a). And even when hashes for two rows differ, they can still end up on the same partition, when there are fewer partitions than unique hashes! But in most cases, with bigger data samples, this trick can mitigate the skew. Of course, you have to make sure that the partitioning expression is not skewed itself (meaning that expression is equal for most of the rows).
Multiple Joins
When you join two DataFrames, Spark will repartition them both by the join expressions. This means that if you are joining to the same DataFrame many times (by the same expressions each time), Spark will be doing the repartitioning of this DataFrame each time. Let’s see it in an example. Let’s open spark-shell and execute the following code. First, let’s create some DataFrames to play with:
val data = for (key <- 1 to 1000000) yield (key, 1)
sc.parallelize(data).toDF("key", "value").registerTempTable("df")
import scala.util.Random
sc.parallelize(Random.shuffle(data)).toDF("key", "value").registerTempTable("df1")
sc.parallelize(Random.shuffle(data)).toDF("key", "value").registerTempTable("df2")
While performing the join, if one of the DataFrames is small enough, Spark will perform a broadcast join. This is actually a pretty cool feature, but it is a subject for another blog post. Right now, we are interested in Spark’s behavior during a standard join. That’s why – for the sake of the experiment – we’ll turn off the autobroadcasting feature by the following line:
sqlContext.sql("SET spark.sql.autoBroadcastJoinThreshold = -1")
Ok, now we are ready to run some joins!
sqlContext.sql("CACHE TABLE df")
sqlContext.sql("SELECT * FROM df JOIN df1 ON df.a = df1.a").show
sqlContext.sql("SELECT * FROM df JOIN df2 ON df.a = df2.a").show
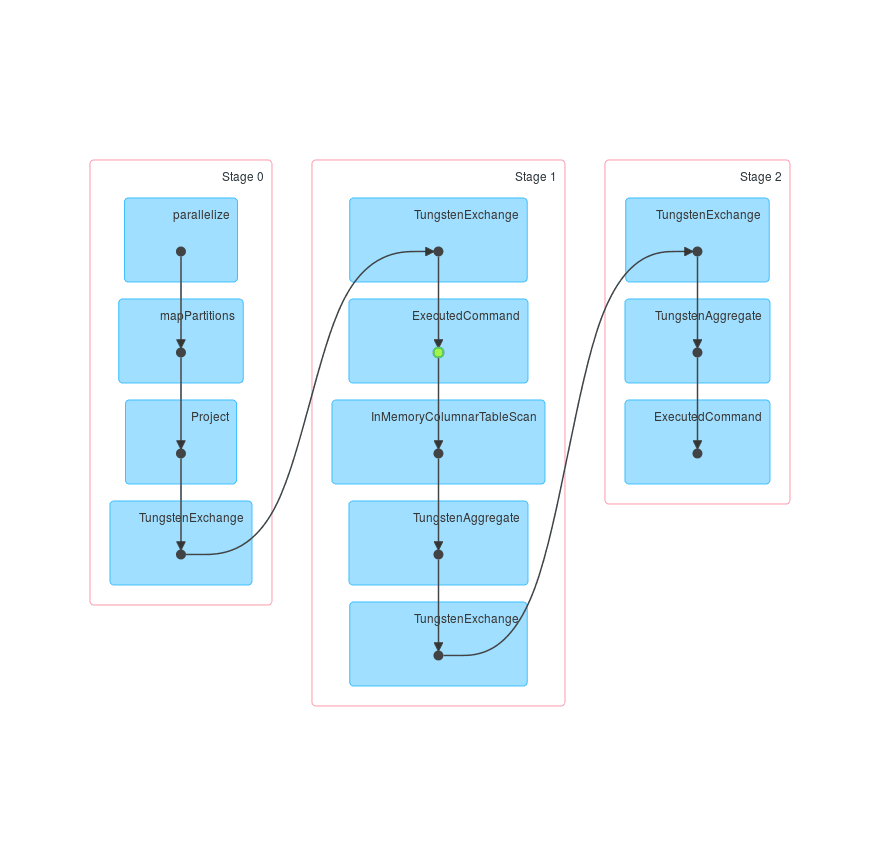
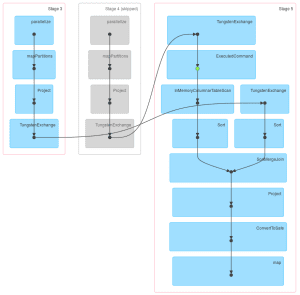
Let’s see how it looks in SparkUI (for spark-shell it usually starts on localhost:4040). Three jobs were executed. Their DAGs look like this:
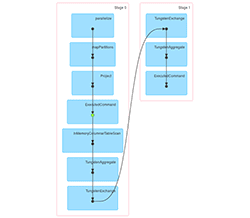
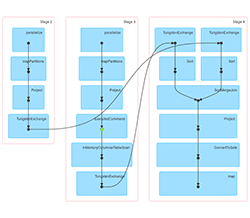
The first job just creates df and caches it. The second one creates df1 and loads df from the cache (this is indicated by the green dot) and then repartitions both of them by key. The third DAG is really similar to the second one, but uses df2 instead of df1. So it is transparent that we repartitioned df by key two times.
How can this be optimised? The answer is, you can repartition the DataFrame yourself, only once, at the very beginning.
val dfDist = sqlContext.sql("SELECT * FROM df DISTRIBUTE BY a")
dfDist.registerTempTable("df_dist")
sqlContext.sql("CACHE TABLE df_dist")
sqlContext.sql("SELECT * FROM df_dist JOIN df1 ON df_dist.a = df1.a").show
sqlContext.sql("SELECT * FROM df_dist JOIN df2 ON df_dist.a = df2.a").show
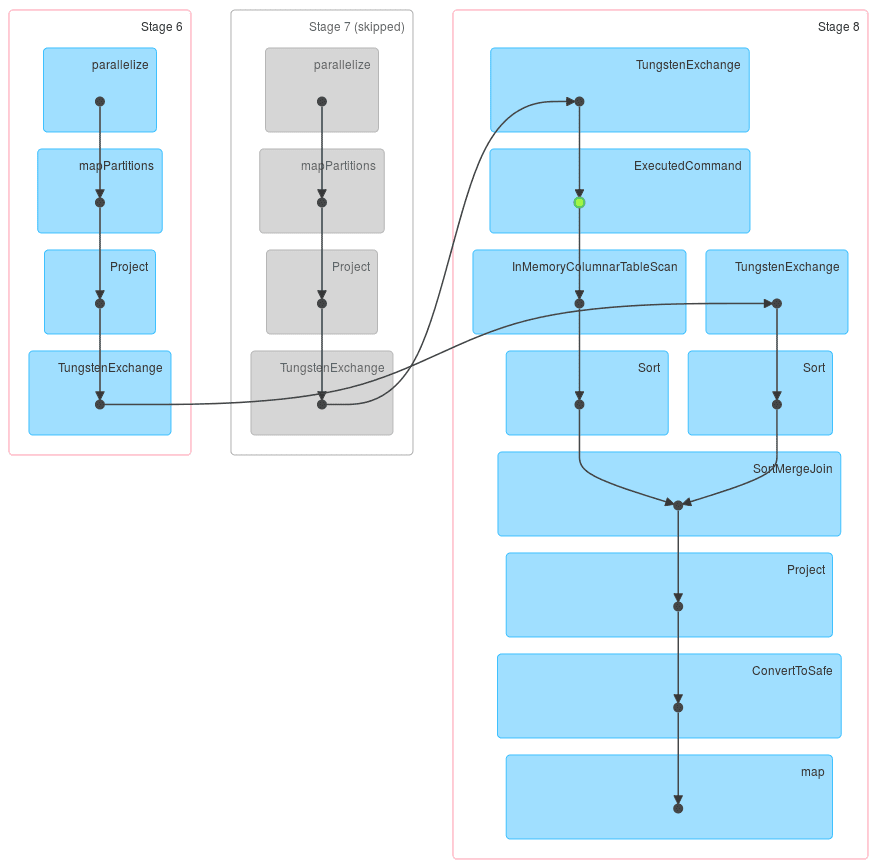
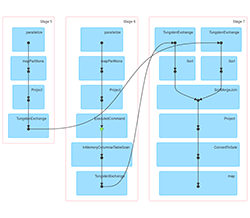
This time the first job has an additional stage – we perform repartitioning by key there. But in both of the following jobs, one stage is skipped and the repartitioned DataFrame is taken from the cache – note that green dot is in a different place now.
Sorting in Join
There is one thing I haven’t yet tell you about yet. Starting from version 1.2, Spark uses sort-based shuffle by default (as opposed to hash-based shuffle). So actually, when you join two DataFrames, Spark will repartition them both by the join expressions and sort them within the partitions! That means the code above can be further optimised by adding sort by to it:
SELECT * FROM df DISTRIBUTE BY a SORT BY a
But as you now know, distribute by + sort by = cluster by, so the query can get even simpler!
SELECT * FROM df CLUSTER BY a
Multiple Join on Already Partitioned DataFrame
Ok, but what if the DataFrame that you will be joining to is already partitioned correctly? For example, if it is a result of grouping by the expressions that will be used in join? Well, in that case you don’t have to repartition it once again – a mere sort by will suffice.
val dfDist = sqlContext.sql("SELECT a, count(*) FROM some_other_df GROUP BY a SORT BY a")
dfDist.registerTempTable("df_dist")
sqlContext.sql("CACHE TABLE df_dist")
sqlContext.sql("SELECT * FROM df_dist JOIN df1 ON df_dist.a = df1.a").show
sqlContext.sql("SELECT * FROM df_dist JOIN df2 ON df_dist.a = df2.a").show
In fact, adding an unnecessary distribute by can actually harm your program! In some cases, Spark won’t be able to see that the data is already partitioned and will repartition it twice. Of course, there is a possibility that this behaviour will change in future releases.
Final Thoughts
Writing Spark applications is easy, but making them optimal can be hard. Sometimes you have to understand what is going on underneath to be able to make your Spark application as fast as it can be. I hope that this post will help you achieve that, at least when it comes to distribute by and cluster by.






