

R, rvest and web-harvesting
Data harvested from the web pages is a source of interesting information. Pulling data used to require quite a lot of resilience and misshapen Perl scripts struggling with messy sources of web pages. Today’s web pages more and more frequently comply meet the standards. There are also more and more civilized tools for parsing websites.

A package rvest has lately gained my sympathy. Harvesting data from web pages with that package is very easy. I would like to present it on the example of scrapping ratings from television series separately for age group and gender of the reviewer. We will make use of this data next week. Today I will only show you how to download it.
When you visit the Internet Movie DataBase (IMDB) and find the tab “user ratings” (see here for example), you will find ratings of given movies broken down by age and gender groups. When you use the package rvest to download the data and parse the html page into html tree, the whole procedure comes down to two lines.
library(rvest)
page = html("http://www.imdb.com/title/tt0903747/ratings")
We can choose only the interesting elements/nodes from that tree. In order to select particular elements we will use an extraordinary tool SelectGadget (http://selectorgadget.com/). The only thing that we need to do now is to click on the content that we want to read and the content that we want to ignore. SelectorGadget will suggest the so-called Css.selector and will highlight in yellow the elements compatible with it. The selector that we need in case of our films is “table:nth-child(11) td:nth-child(3)”.
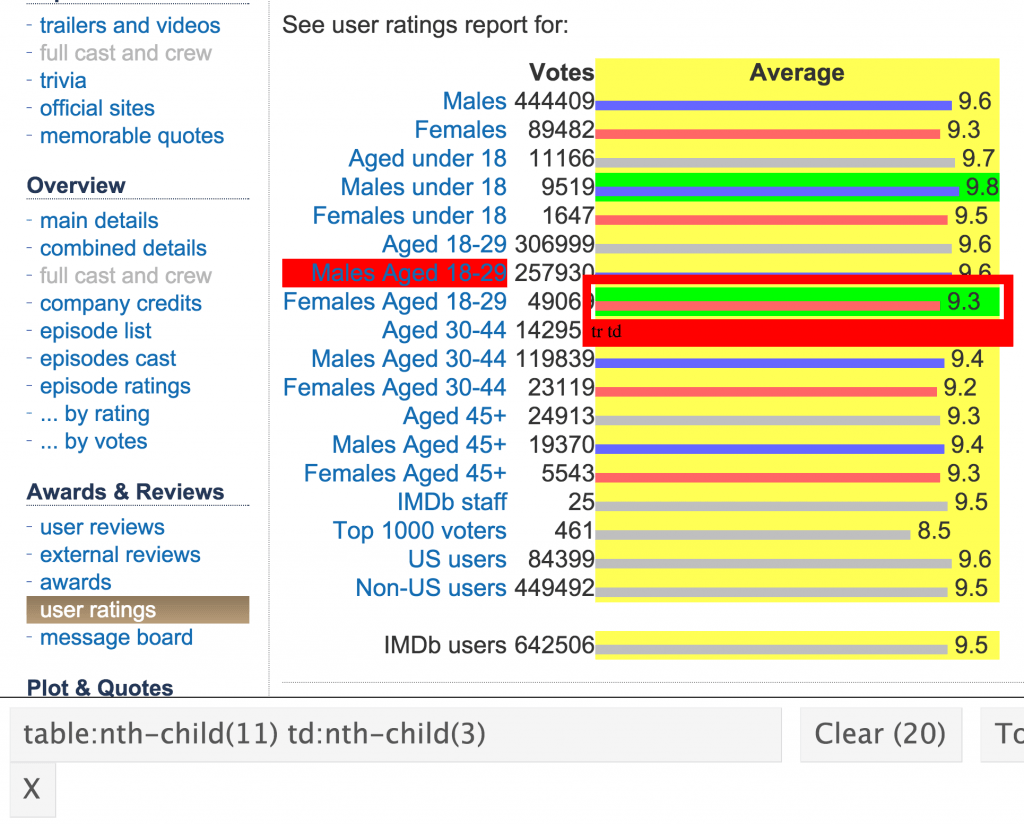
Screenshot of the webpage with elements highlighted by SelectorGadget. All nodes that match the css selector are marked yellow.
In order to harvest the interesting data we need to:
1. Select the nodes of the html tree compatible with the selector (using the function html_nodes),
2. Extract the text from the nodes (using the function html_text). If there is something else apart from numbers, we can clean the nodes with a regular expression.
The three lines presented below will reveal to us assessments of a given movie (in this case BreakingBad) of various age groups and different genders.
nodes = html_nodes(page, "table:nth-child(11) td:nth-child(3)") html_text(nodes) as.numeric(gsub(html_text(nodes), pattern="[^0-9.]", replacement=""))
Seems so trivial!
Let us repeat this for all the tv series. We will check which of them are preferred by women and which by men. We can also see which series gain recognition among the younger audience and which among the older audience.
Instead of titles of the series the addresses of the web pages of IMDB service use identification numbers. The identification number for BreakingBad is tt0903747.
Where can we find the identification numbers of the movies? We can use the data set serialeIMDB from the package PogromcyDanych. It contains identification numbers of over 200 most popular television series gathered in the column imdbId.
The following code will download the webpage with ratings of each series. Then, it will extract the ratings broken down by age and gender and save it in the table called ratings.
library(rvest)
library(PogromcyDanych)
serialsToParse = levels(serialeIMDB$imdbId)
# prepare matrix for results
ratingsGroup = matrix("", length(serialsToParse), 14)
rownames(ratingsGroup) = serialsToParse
colnames(ratingsGroup) = c("Males", "Females", "Aged under 18", "Males under 18",
"Females under 18", "Aged 18-29", "Males Aged 18-29", "Females Aged 18-29",
"Aged 30-44", "Males Aged 30-44", "Females Aged 30-44", "Aged 45+",
"Males Aged 45+", "Females Aged 45+")
# for all series
for (serial in serialsToParse) {
page = html(paste0("http://www.imdb.com/title/",serial,"/ratings"))
nodes3 = html_nodes(page, "table:nth-child(11) td:nth-child(3)")
ratingsGroup[serial,] = gsub(html_text(nodes3)[-1], pattern="[^0-9.]", replacement="")[1:14]
}
Below you will find 10 first rows and four selected columns from the collected dataset.
ratingsGroup[1:10, c(1,2,6,12)] Males Females Aged 18-29 Aged 45+ tt0903747 "9.6" "9.3" "9.6" "9.3" tt2395695 "9.4" "9.5" "9.5" "9.1" tt0795176 "9.5" "9.5" "9.5" "9.4" tt0944947 "9.5" "9.4" "9.6" "9.2" tt2356777 "9.3" "9.1" "9.4" "9.0" tt0306414 "9.5" "8.6" "9.4" "9.1" tt1475582 "9.2" "9.4" "9.4" "9.0" tt0081846 "9.4" "9.2" "9.2" "9.4" tt0141842 "9.3" "9.0" "9.4" "9.1" tt1831164 "9.1" "9.3" "9.4" "7.1"
Next week I will show you an application presenting differences in assessments of female and male audience.
Przemyslaw Biecek
