
Table of contents
With an estimated market size of 7.35 billion US dollars, artificial intelligence is growing by leaps and bounds. McKinsey predicts that AI techniques (including deep learning and reinforcement learning) have the potential to create between $3.5T and $5.8T in value annually across nine business functions in 19 industries. Although machine learning is seen as a monolith, this cutting-edge technology is diversified, with various sub-types including machine learning, deep learning, and the state-of-art technology of deep reinforcement learning.
Table of contents
What is reinforcement learning?
Reinforcement learning is the training of machine learning models to make a sequence of decisions. The agent learns to achieve a goal in an uncertain, potentially complex environment. In reinforcement learning, an artificial intelligence faces a game-like situation. The computer employs trial and error to come up with a solution to the problem. To get the machine to do what the programmer wants, the artificial intelligence gets either rewards or penalties for the actions it performs. Its goal is to maximize the total reward.
Although the designer sets the reward policy–that is, the rules of the game–he gives the model no hints or suggestions for how to solve the game. It’s up to the model to figure out how to perform the task to maximize the reward, starting from totally random trials and finishing with sophisticated tactics and superhuman skills. By leveraging the power of search and many trials, reinforcement learning is currently the most effective way to hint machine’s creativity. In contrast to human beings, artificial intelligence can gather experience from thousands of parallel gameplays if a reinforcement learning algorithm is run on a sufficiently powerful computer infrastructure.
Examples of reinforcement learning
Applications of reinforcement learning were in the past limited by weak computer infrastructure. However, as Gerard Tesauro’s backgamon AI superplayer developed in 1990’s shows, progress did happen. That early progress is now rapidly changing with powerful new computational technologies opening the way to completely new inspiring applications. Training the models that control autonomous cars is an excellent example of a potential application of reinforcement learning. In an ideal situation, the computer should get no instructions on driving the car. The programmer would avoid hard-wiring anything connected with the task and allow the machine to learn from its own errors. In a perfect situation, the only hard-wired element would be the reward function.
- For example, in usual circumstances we would require an autonomous vehicle to put safety first, minimize ride time, reduce pollution, offer passengers comfort and obey the rules of law. With an autonomous race car, on the other hand, we would emphasize speed much more than the driver’s comfort. The programmer cannot predict everything that could happen on the road. Instead of building lengthy “if-then” instructions, the programmer prepares the reinforcement learning agent to be capable of learning from the system of rewards and penalties. The agent (another name for reinforcement learning algorithms performing the task) gets rewards for reaching specific goals.
- Another example: deepsense.ai took part in the “Learning to run” project, which aimed to train a virtual runner from scratch. The runner is an advanced and precise musculoskeletal model designed by the Stanford Neuromuscular Biomechanics Laboratory. Learning the agent how to run is a first step in building a new generation of prosthetic legs, ones that automatically recognize people’s walking patterns and tweak themselves to make moving easier and more effective. While it is possible and has been done in Stanford’s labs, hard-wiring all the commands and predicting all possible patterns of walking requires a lot of work from highly skilled programmers.
For more real-life applications of reinforcement learning check this article.
Challenges with reinforcement learning
Creating realistic simulation environments
The main challenge in reinforcement learning lays in preparing the simulation environment, which is highly dependant on the task to be performed. When the model has to go superhuman in Chess, Go or Atari games, preparing the simulation environment is relatively simple. When it comes to building a model capable of driving an autonomous car, building a realistic simulator is crucial before letting the car ride on the street. The model has to figure out how to brake or avoid a collision in a safe environment, where sacrificing even a thousand cars comes at a minimal cost. Transferring the model out of the training environment and into to the real world is where things get tricky.
Scaling and tweaking neural networks
Scaling and tweaking the neural network controlling the agent is another challenge. There is no way to communicate with the network other than through the system of rewards and penalties.This in particular may lead to catastrophic forgetting, where acquiring new knowledge causes some of the old to be erased from the network (to read up on this issue, see this paper, published during the International Conference on Machine Learning).
Overcoming local optimum and task evasion
Yet another challenge is reaching a local optimum – that is the agent performs the task as it is, but not in the optimal or required way. A “jumper” jumping like a kangaroo instead of doing the thing that was expected of it-walking-is a great example, and is also one that can be found in our recent blog post.
Finally, there are agents that will optimize the prize without performing the task it was designed for. An interesting example can be found in the OpenAI video below, where the agent learned to gain rewards, but not to complete the race.
What distinguishes reinforcement learning from deep learning and machine learning?
In fact, there should be no clear divide between machine learning, deep learning and reinforcement learning. It is like a parallelogram – rectangle – square relation, where machine learning is the broadest category and the deep reinforcement learning the most narrow one. In the same way, reinforcement learning is a specialized application of machine and deep learning techniques, designed to solve problems in a particular way.
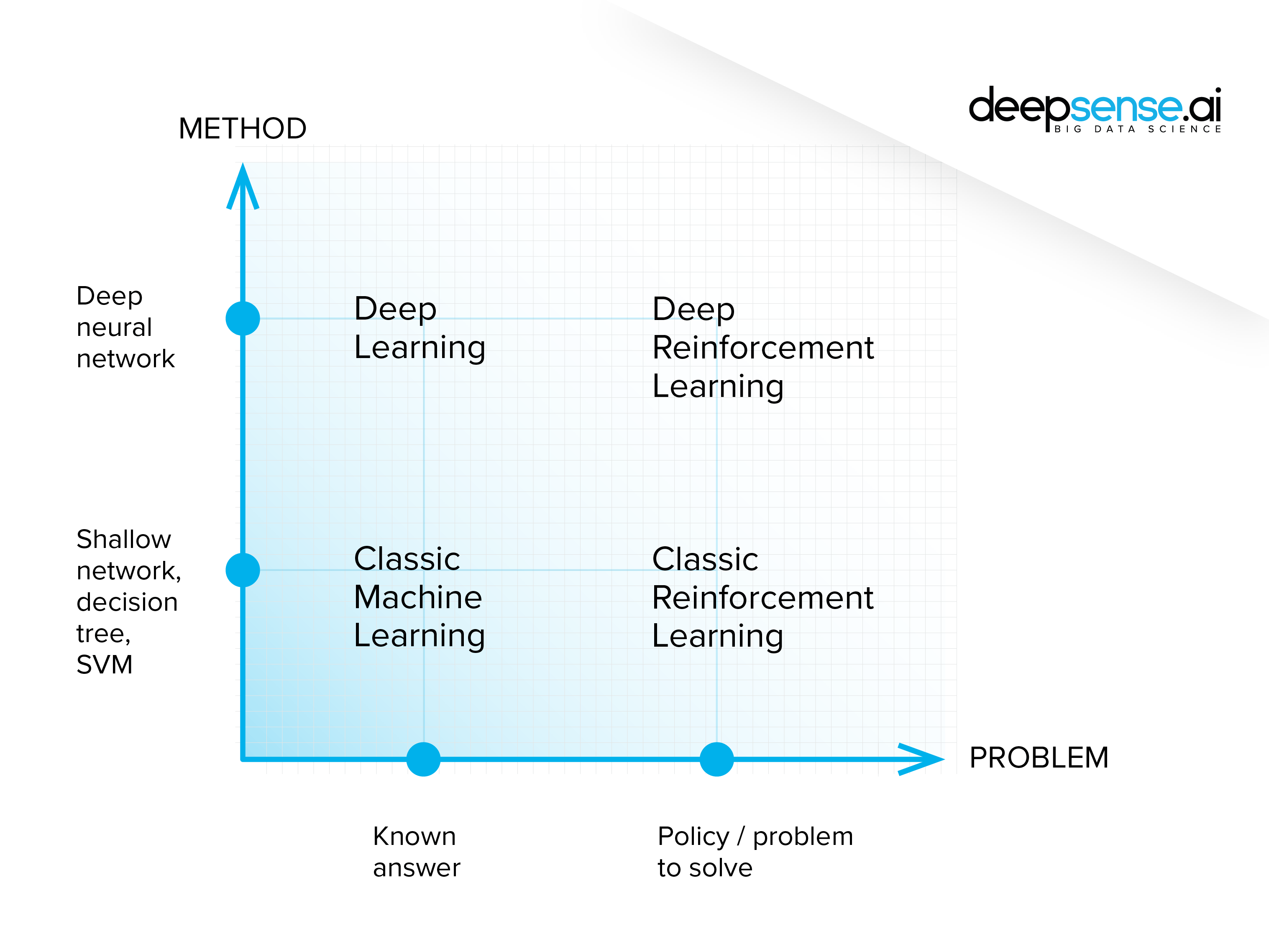
Although the ideas seem to differ, there is no sharp divide between these subtypes. Moreover, they merge within projects, as the models are designed not to stick to a “pure type” but to perform the task in the most effective way possible. So “what precisely distinguishes machine learning, deep learning and reinforcement learning” is actually a tricky question to answer.
What is machine learning?
Machine learning is a form of AI in which computers are given the ability to progressively improve the performance of a specific task with data, without being directly programmed ( this is Arthur Lee Samuel’s definition). He coined the term “machine learning”, of which there are two types, supervised and unsupervised machine learning Supervised machine learning happens when a programmer can provide a label for every training input into the machine learning system.
- Example – by analyzing the historical data taken from coal mines, deepsense.ai prepared an automated system for predicting dangerous seismic events up to 8 hours before they occur. The records of seismic events were taken from 24 coal mines that had collected data for several months. The model was able to recognize the likelihood of an explosion by analyzing the readings from the previous 24 hours.
From the AI point of view, a single model was performing a single task on a clarified and normalized dataset. To get more details on the story, read our article about machine learning models predicting dangerous seismic events. Unsupervised learning takes place when the model is provided only with the input data, but no explicit labels. It has to dig through the data and find the hidden structure or relationships within. The designer might not know what the structure is or what the machine learning model is going to find.
- An example we employed was for churn prediction. We analyzed customer data and designed an algorithm to group similar customers. However, we didn’t choose the groups ourselves. Later on, we could identify high-risk groups (those with a high churn rate) and our client knew which customers they should approach first.
- Another example of unsupervised learning is anomaly detection, where the algorithm has to spot the element that doesn’t fit in with the group. It may be a flawed product, potentially fraudulent transaction or any other event associated with breaking the norm.
What is deep learning?
Deep learning consists of several layers of neural networks, designed to perform more sophisticated tasks. The construction of deep learning models was inspired by the design of the human brain, but simplified. Deep learning models consist of a few neural network layers which are in principle responsible for gradually learning more abstract features about particular data. Although deep learning solutions are able to provide marvelous results, in terms of scale they are no match for the human brain. Each layer uses the outcome of a previous one as an input and the whole network is trained as a single whole. The core concept of creating an artificial neural network is not new, but only recently has modern hardware provided enough computational power to effectively train such networks by exposing a sufficient number of examples. Extended adoption has brought about frameworks like TensorFlow, Keras and PyTorch, all of which have made building machine learning models much more convenient.
- Example: deepsense.ai designed a deep learning-based model for the National Oceanic and Atmospheric Administration (NOAA). It was designed to recognize Right whales from aerial photos taken by researchers. For further information about this endangered species and deepsense.ai’s work with the NOAA, read our blog post. From a technical point of view, recognizing a particular specimen of whales from aerial photos is pure deep learning. The solution consists of a few machine learning models performing separate tasks. The first one was in charge of finding the head of the whale in the photograph while the second normalized the photo by cutting and turning it, which ultimately provided a unified view (a passport photo) of a single whale.

The third model was responsible for recognizing particular whales from photos that had been prepared and processed earlier. A network composed of 5 million neurons located the blowhead bonnet-tip. Over 941,000 neurons looked for the head and more than 3 million neurons were used to classify the particular whale. That’s over 9 million neurons performing the task, which may seem like a lot, but pales in comparison to the more than 100 billion neurons at work in the human brain. We later used a similar deep learning-based solution to diagnose diabetic retinopathy using images of patients’ retinas.
Reinforcement learning in detail
Reinforcement learning, as stated above employs a system of rewards and penalties to compel the computer to solve a problem by itself. Human involvement is limited to changing the environment and tweaking the system of rewards and penalties. As the computer maximizes the reward, it is prone to seeking unexpected ways of doing it. Human involvement is focused on preventing it from exploiting the system and motivating the machine to perform the task in the way expected. Reinforcement learning is useful when there is no “proper way” to perform a task, yet there are rules the model has to follow to perform its duties correctly. Take the road code, for example.
- Example: By tweaking and seeking the optimal policy for deep reinforcement learning, we built an agent that in just 20 minutes reached a superhuman level in playing Atari games. Similar algorithms in principal can be used to build AI for an autonomous car or a prosthetic leg. In fact, one of the best ways to evaluate the reinforcement learning approach is to give the model an Atari video game to play, such as Arkanoid or Space Invaders. According to Google Brain’s Marc G. Bellemare, who introduced Atari video games as a reinforcement learning benchmark, “although challenging, these environments remain simple enough that we can hope to achieve measurable progress as we attempt to solve them”.
| Breakout | ||
| Initial performance | After 15 minutes of training | After 30 minutes of training |
 | 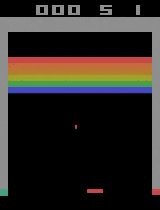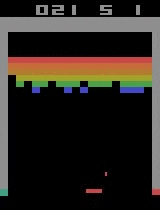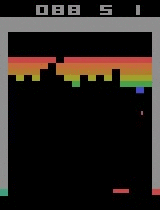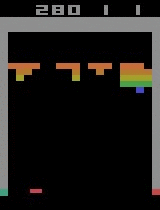 |  |
| Assault | ||
| Initial performance | After 15 minutes of training | After 30 minutes of training |
 |  |  |
In particular, if artificial intelligence is going to drive a car, learning to play some Atari classics can be considered a meaningful intermediate milestone. A potential application of reinforcement learning in autonomous vehicles is the following interesting case. A developer is unable to predict all future road situations, so letting the model train itself with a system of penalties and rewards in a varied environment is possibly the most effective way for the AI to broaden the experience it both has and collects.
Reinforcement learning vs deep learning ve machine learning: conclusion
The key distinguishing factor of reinforcement learning is how the agent is trained. Instead of inspecting the data provided, the model interacts with the environment, seeking ways to maximize the reward. In the case of deep reinforcement learning, a neural network is in charge of storing the experiences and thus improves the way the task is performed.
Is reinforcement learning the future of machine learning?
Although reinforcement learning, deep learning, and machine learning are interconnected no one of them in particular is going to replace the others. Yann LeCun, the renowned French scientist and head of research at Facebook, jokes that reinforcement learning is the cherry on a great AI cake with machine learning the cake itself and deep learning the icing. Without the previous iterations, the cherry would top nothing.
In many use cases, using classical machine learning methods will suffice. Purely algorithmic methods not involving machine learning tend to be useful in business data processing or managing databases.
Sometimes machine learning is only supporting a process being performed in another way, for example by seeking a way to optimize speed or efficiency. When a machine has to deal with unstructured and unsorted data, or with various types of data, neural networks can be very useful.
Summary
Reinforcement learning is no doubt a cutting-edge technology that has the potential to transform our world. However, it need not be used in every case. Nevertheless, reinforcement learning seems to be the most likely way to make a machine creative – as seeking new, innovative ways to perform its tasks is in fact creativity. This is already happening: DeepMind’s now famous AlphaGo played moves that were first considered glitches by human experts, but in fact secured victory against one of the strongest human players, Lee Sedol.
Thus, reinforcement learning has the potential to be a groundbreaking technology and the next step in AI development.





