
Table of contents
Underground mining poses a number of threats including fires, methane outbreaks or seismic tremors and bumps. An automatic system for predicting and alerting against such dangerous events is of utmost importance – and also a great challenge for data scientists and their machine learning models. This was the inspiration for the organizers of AAIA’16 Data Mining Challenge: Predicting Dangerous Seismic Events in Active Coal Mines.
Table of contents
Our solutions topped the final leaderboard by taking the first two places. In this post, we present the competition and describe our winning approach. For a more detailed description please see our publication.
The Challenge
The datasets provided by organizers comprised of seismic activity records from Polish coal mines (24 working sites) collected throughout a period of several months. The goal was to develop a prediction model that, based on recordings from a 24-hour period, would predict whether an energy warning level (50k Joules) was going to be exceeded in the following 8 hours. The participants were presented with two datasets: one for training and the other for testing purposes. The training set consisted of 133,151 observations accompanied by labels – binary values indicating warning level excess. The test set was of a moderate size of 3,860 observations. The prediction model should automatically assess the danger for each event, i.e. evaluate the likelihood of exceeding the energy warning level for each observation.
The model’s quality was to be judged by the accuracy of the likelihoods measured with respect to the Area Under ROC curve (AUC) metric. This is a common metric for evaluating binary predictions, particularly when the classes are imbalanced (only about 2% of events in the training dataset were labeled as dangerous). The AUC measure can be interpreted as the probability that a randomly drawn observation from the danger class will have a higher likelihood assigned to it than a randomly drawn observation from the safe class. Knowing the interpretation it is easy to assess the quality of the results: a score of 1.0 means perfect prediction and 0.5 is the equivalent of random guessing. (Bonus question for the readers: what would a score of 0 mean?).
Overview of the data
What constitutes an observation in this dataset? An observation is not a single number but a list of 541 values. There are 13 general features describing the entire 24 hour-long period, such as:
- ID of the working site;
- Overall energies of bumps, tremors, destressing blasts and total seismic energy;
- Latest experts’ hazard assessments.
The remaining features are 24 hour-long time series of the number of seismic events and their energies. Apart from the above data, the participants were provided with metadata about each working site. This was mostly information specific to a given working site, e.g. its name.
Our insights
The very first and one of the major tasks facing a data scientist is getting familiar with the dataset. One should assess its coherence, check for missing values and, in many cases, modify it to obtain a more meaningful representation of underlying phenomena. In other words, one would perform feature engineering. Below we present insights which we found interesting from a machine learning perspective.
Sparse information
The majority of the values in the training set were just zeros – around 66 percent! A sensible approach is to aggregate related sparse features to produce denser representations. An example could be to sum hourly counts of seismic events. By summing values in all 24 hours, the last 5 hours and in the very last hour, we would end up with 3 features instead of 24 – eight times less. We would not only reduce the size of the dataset – we would also have a greater chance that our models would see some interesting patterns more easily. At the same time, we would prevent the models from getting fooled by temporary artifacts – their impact will fade down after aggregation.
Multiple locations
An interesting difficulty – or rather a challenge – are the observations’ origins. The seismic records were collected at different coal mines with varying seismic activity. In some of them dangerous events were much more frequent than in others, ranging from 0 to 17% of observations. Ideally, we would produce a single specialized model for each working site. However, there is a high probability that these models would be useless when confronted with a new location. They would also be useless in this data mining challenge – the table below presents coal mines along with the number of available observations – notice that not all of them appear in both training and test sets and that the number of observations vary considerably between the sites. Thus, there was a need to build a location-agnostic model that would learn from general seismic activity phenomena.
| Working site ID | Training observations | Test observations | Warnings frequency |
| 373 | 31236 | – | 1.1% |
| 264 | 20533 | – | 0.4% |
| 725 | 14777 | 330 | 9.4% |
| 777 | 13437 | 330 | 0.0% |
| 437 | 11682 | – | 0.4% |
| 541 | 6429 | 5 | 0.9% |
| 146 | 5591 | 98 | 0.1% |
| 575 | 4891 | 253 | 0.5% |
| 765 | 4578 | 329 | 0.0% |
| 149 | 4248 | 98 | 7.3% |
| 155 | 3839 | 98 | 17.2% |
| 583 | 3552 | 215 | 0.2% |
| 479 | 2488 | 35 | 0.0% |
| 793 | 2346 | 330 | 0.0% |
| 607 | 2328 | 209 | 0.0% |
| 599 | 1196 | 363 | 1.9% |
| 799 | – | 317 | – |
| 470 | – | 258 | – |
| 490 | – | 160 | – |
| 703 | – | 145 | – |
| 641 | – | 97 | – |
| 689 | – | 83 | – |
| 508 | – | 58 | – |
| 171 | – | 49 | – |
Working site proxies
As mentioned above, our goal was to build a model which generalizes well and is able to infer predictions from a broad variety of clues (the features we extracted) without getting biased toward particular locations. Therefore, a necessary step is to exclude the mine IDs from the features set. We have to be careful though, as the information identifying a particular site can leak through other features, turning them into working site proxies. We have already mentioned them – these were the coal mines’ metadata and the majority of them were excluded straight away (various names specific only to particular locations). We only kept the main working height, as this information was valuable. However, as you can see in the figure below, some of the mines can be exactly identified by their main working height values. To obstruct the identification, we added some Gaussian noise:
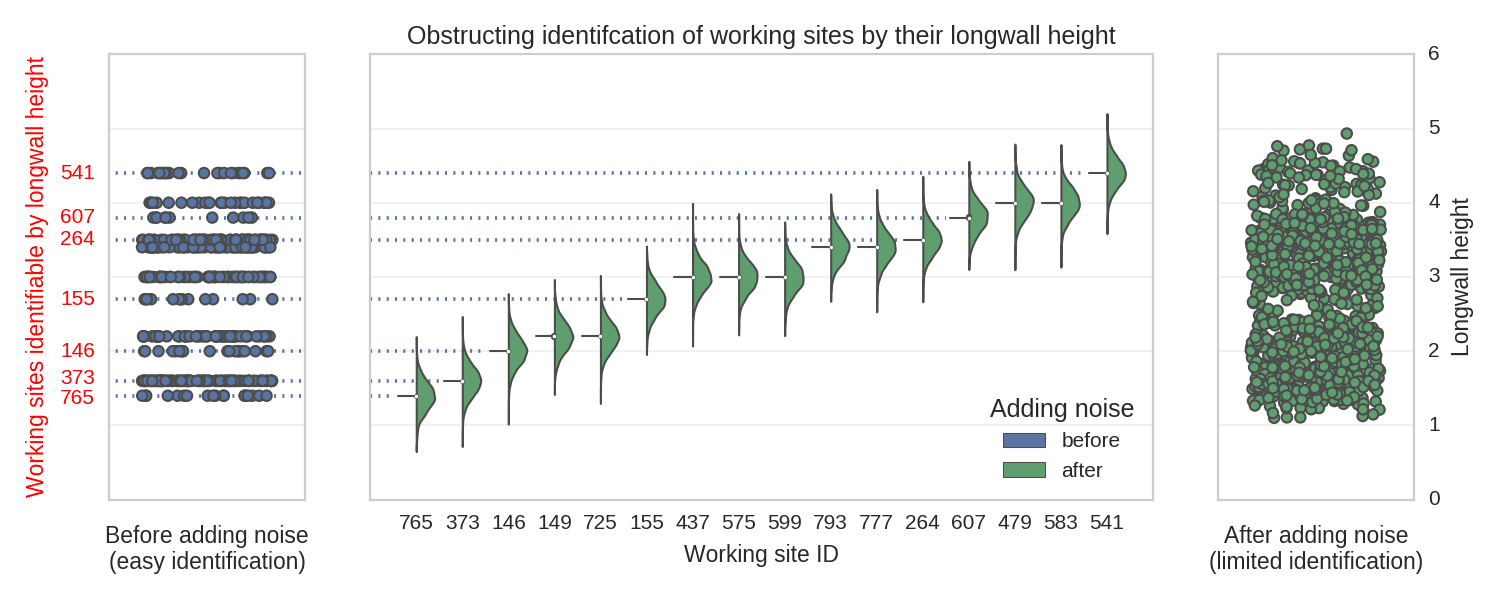
After injecting some randomness, it is no longer possible to exactly identify location based on a longwall’s height. However, the essential information is still conveyed.
Features
The above insights allowed us to significantly reduce the number of features. We ended up with 133 features – 4 times less than the original set.
This was not the end of feature extraction. Often some valuable information is not stored directly in the features, but rather in the interactions between them (e.g. pairwise multiplications). We selected around 1,000 of the most promising interactions and treated them as additional features.
Validation
The condition – that the model has to generalize well – sets particular requirements on the validation procedure. It has to favor the models that make accurate predictions for the known working sites, as well as for previously unseen sites. One possible validation procedure which satisfies these conditions is to, for every train-test split, divide the working sites into three groups: first group will be used solely for training, second only for testing, in the third the observations will be split. For the sake of the results’ stability, we would generate many of these configurations (25 worked well in our case) and average the outcomes.
Model selection
Having settled on the features set and the validation procedure we focused on model selection. The process was quite complex, so let’s go through it step-by-step:
- We decided to use tree-based classifiers as they work particularly well with unbalanced classes and possibly correlated features. Namely, we used ExtraTreesClassifier (ETC) from scikit-learn and XGBoost (XGB) classifier from xgboost;
- We ran a preliminary grid search to find well-performing meta-parameters;
- The models were used to select promising features subsets. We ran hundreds of evaluations, where in each run we made use of a random selection of features (between 20 and 40) and interactions (up to 10).
Model ensembling

The above procedure was meant to reveal relatively small feature subspaces. All of them were reasonably accurate. Moreover, they were also (to some extent) independent. The models based on them could see only a small part of the entire features space, therefore they were inferring their predictions based on diverse clues. And what can one do with a number of varied models? Let them vote! The final submission to the contest was a blend of predictions generated by multiple models (2 major ones which saw all features and 40 minor ones, which saw only subspaces).
Final results
The final submission reached 0.94 AUC and turned out to be the best in the competition, outperforming 200 other machine learning teams. This meant that deepsense.ai retained its top position in the AAIA Data Mining Challenges (you can read about our success last year here). I would like to thank all the competition participants for a challenging environment, as well as the organizers from the University of Warsaw and the Institute of Innovative Technologies EMAG for preparing such an interesting and meaningful dataset. I would also like to thank my colleagues from the deepsense.ai Machine Learning Team: Robert Bogucki, Jan Kanty Milczek and Jan Lasek for the great time we had tackling the problem.





