

Implementing Small Language Models (SLMs) with RAG on Embedded Devices Leading to Cost Reduction, Data Privacy, and Offline Use
In today’s rapidly evolving generative AI world, keeping pace requires more than embracing cutting-edge technology. At deepsense.ai, we don’t merely follow trends; we aspire to establish new solutions. Our latest achievement combines Advanced Retrieval-Augmented Generation (RAG) with Small Language Models (SLMs), aiming to enhance the capabilities of embedded devices beyond traditional cloud solutions. Yet, it’s not solely about the technology – it’s about the business opportunities it presents: cost reduction, improved data privacy, and seamless offline functionality.
What are Small Language Models?
Inherently, Small Language Models (SLMs) are smaller counterparts of Large Language Models. They have fewer parameters and are more lightweight and faster in inference time. We can consider models with more than 7 billion parameters as LLMs (the largest could have even more than 1 trillion parameters), demanding resource-heavy training and inference. The definition of a Small Language Model may vary among authors, but we consider models lightweight enough to run on edge devices, typically with 3 billion parameters or less. Please note that this division is conventional and does not provide full depth.
SLMs are compact versions of Language Models, and they excel in two main areas:
- SLMs are suitable for Edge Devices, offering businesses benefits such as cost reduction, offline usage, or enhanced data privacy.
- For research groups, SLMs facilitate speeding up R&D progress, swiftly testing new ideas, benchmarking at scale, and iterating relatively fast. Even retraining SLMs (even from scratch) is feasible for small groups with access to home-grade GPUs.
This article focuses on the first area: applying SLMs to Edge Devices for practical purposes.
Benefits of SLMs on Edge Devices
In this section, we present three compelling reasons why companies may find Small Language Model (SLM) applications preferable to their cloud-heavy Large Language Model (LLM) counterparts:
Cost Reduction
The expense of cloud inference for Large Language Models can be prohibitive. Transitioning LLM-based solutions directly to edge devices eliminates the need for cloud inference, resulting in significant cost savings at scale. This cost reduction may be a primary incentive for companies already employing cloud-based LLM inference on mobile phones or edge devices. Additionally, for specific applications, the quality offered by smaller models may already meet requirements. Moreover, companies seeking to cut LLM costs can benefit from shifting inference to local PC hardware.
We encourage readers interested in cost reduction topics to read our article on Reducing the cost of LLMs with quantization and efficient fine-tuning.
Offline Functionality
Deploying SLMs directly on edge devices eliminates the requirement for internet access, making SLM-based solutions suitable for scenarios where internet connectivity is limited. For instance, consider a drone application leveraging a Small Vision Language Model; it must operate seamlessly even in environments lacking internet connectivity. Another example can be a smartphone application as an RAG pipeline, utilizing the company’s documents and providing a question-answer mechanism. This application utilizes SLM and can reduce the costs of hosting larger LLM in a cloud.
Data Privacy
Sometimes, apprehensions arise regarding cloud services due to data protection regulations. All processing occurs locally by running on the Edge, offering the opportunity to adopt Language Model-based solutions while adhering to stringent data protection protocols.
Developing a Complete RAG Pipeline with SLMs on a Mobile Phone
To gain hands-on experience with Small Language Models, we decided to investigate an internal project where we explore SMLs and their usage.
The main goal of this internal project was to develop a complete Retrieval-Augmented Generation (RAG) pipeline, encompassing the embedding model, retrieval of relevant document chunks, and the question-answering model, ready for deployment on resource-constrained Android devices. The primary objective was to explore the capabilities of Small Language Models (SLMs) in terms of overall response quality and generation speed on mobile hardware.
Also, we publish code related to this project; check it at: https://github.com/deepsense-ai/edge-slm
What did we do?
- We constructed a prototype pipeline for RAG using the llama.cpp framework and successfully deployed it on Android devices.
- We experimented with SLMs, including Phi-2, Gemma, and TinyLlama, with parameter counts ranging from 1B to 3B.
- Using the Ragas library, we evaluated their question-answering quality by combining human assessment with automated LLM-based metrics.
- We gauged the impact of different quantization levels and prompt engineering on response quality.
- We assessed the pipeline’s latency and memory consumption, gaining insights into the current possibilities for deploying language models on the edge.
- In addition, we conducted experiments on the pipeline’s retrieval component, which involved embedding model selection and hyperparameter optimization.
- Parallel to developing the main pipeline, we explored other frameworks such as ExecuTorch and MLC and alternatives to Transformer, like selective state space models (Mamba).

Demo of the RAG pipeline Phi-2 Q8 model with thenlper/gte-large embeddings model running on Samsung S24 Ultra.
What does the RAG pipeline look like?
It is a technique for injecting specific knowledge (consider your company documents and text data) into a system where users ask questions, and the Language Model answers those questions, incorporating knowledge from the mentioned documents. In other words, it is a zero-shot prompt technique for the Language Model, requiring no fine-tuning or training of the model. The main flow of the designed RAG pipeline is depicted in the diagram below, and this is precisely what we have fully implemented on the smartphone as our demo project.

For the offline component, documents are chunked, and embeddings are calculated. For the company’s records, this process was once an offline operation. When a mobile application is initiated, embeddings (indexed pointers to document chunks) are stored on the device in RAM, and documents are stored on the smartphone’s hard drive. Subsequently, when a user poses a question (user query), context is retrieved from this vector index. With appropriate prompt engineering, the Small Language Model takes user questions, retrieves contexts, and generates responses.
Offline processing:
The production-ready system can also include an offline component. The “Knowledge base” needs to be distributed to the edge devices, implying that the distribution may involve precalculated embeddings.
- The document chunking step is conducted offline using Python scripts. This approach allows for the utilization of existing libraries and tools, such as LangChain.
- Embedding vectors are computed offline to reduce loading time. This is achieved by developing simple applications using the developed library, ensuring consistent runtime implementation for the embeddings.
Online on edge part:
- Knowledge base loading must occur during application startup, and indexed chunks must be loaded at runtime. The current solution stores all document chunks directly in memory. If the desired knowledge base was too large to fit within a reasonable amount of RAM, enhancing the solution by implementing mechanisms to store the actual documents outside the application would be necessary.
- The context retrieval component takes the user query and the knowledge base. It extracts the K nearest elements retrieved from the knowledge base based on the cosine similarity score between the user query and document chunks.
- The response generation step is the final stage in the pipeline. For this project’s scope, we did not implement the chatting functionality. It may be added in subsequent steps. This component generates the SLM model response based on the specific model prompt template, retrieved contexts, and the user query. The output from the LLM interface is capable of token streaming.
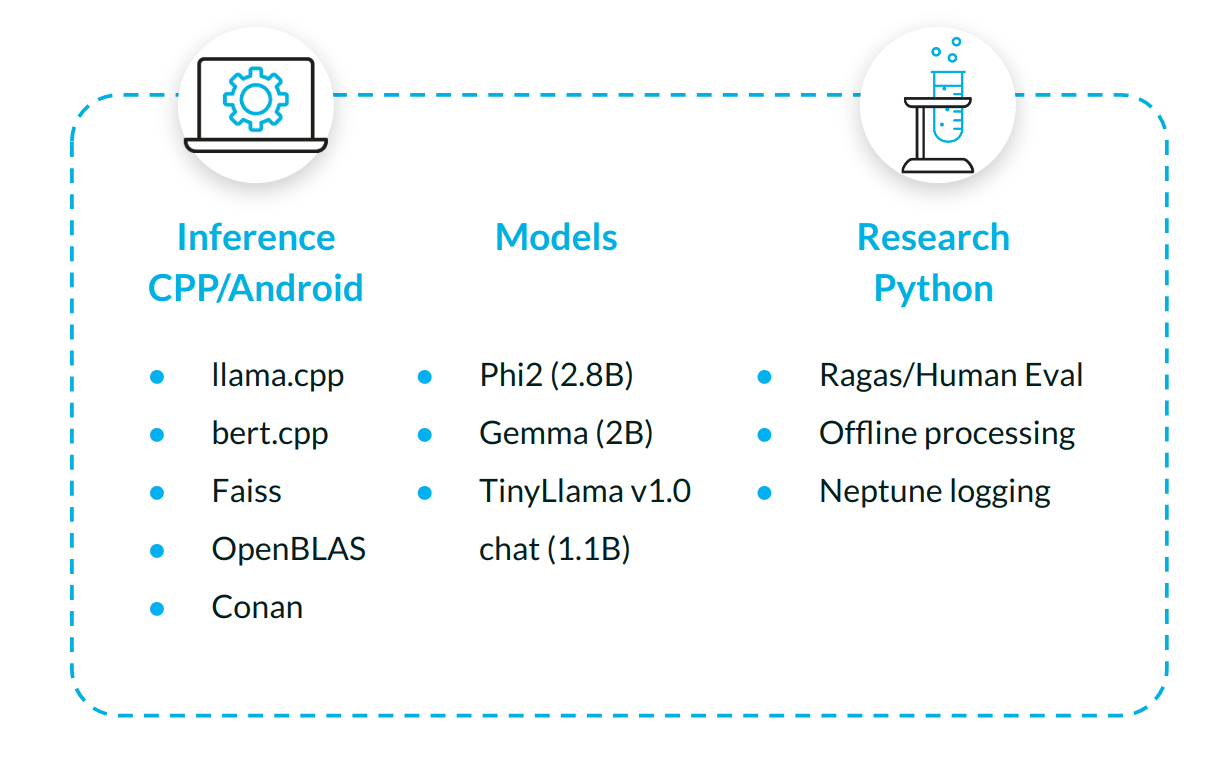
Tech Stack
Tech Stack
Below, we provide a quick overview of the project, divided into research and inference sites. For the tech stack used in inference, we chose llama.cpp as an inference engine for SLMs, bert.cpp as a framework for embedding a model (now fully integrated into llama.cpp), Faiss as a library for realizing k-nn search for embeddings from user queries and embeddings from document chunks, OpenBLAS as Faiss requires a BLAS implementation, and Conan to manage C++ dependencies in the Android environment. On the research side, we evaluated models using both human and automated metrics (Ragas) and benchmarked the application.
Methods and Tools
Let’s start with the inference engine for the Small Language Model. We have tested and evaluated four LLM frameworks:
- llama.cpp – This framework emerged as the best choice for runtime in mobile environments. It boasts a large community and is actively developed. It is compatible with mobile devices. In addition to supporting numerous Transformer models, there is a pending PR for incorporating Mamba models, which we also tested. While the community is rapidly growing, the PRs and codebase can be disorganized. Mobile optimizations are not the highest priority.
- MLC LLM—Built on Apache TVM, our tests revealed this project’s limited applicability. It exhibited slower performance with GPU computations compared to llama.cpp. Additionally, it offers a narrower range of supported models.
- Mamba.c – A runtime for Mamba written in C. It only supports CPU instructions on Android. A basic CUDA implementation is available, but it functions solely on PCs.A runtime for Mamba written in C. It only supports CPU instructions on Android. A basic CUDA implementation is available, but it functions solely on PCs.
- ExecuTorch – This is a new framework designed for mobile and edge devices. While still in the development phase, it shows promise. However, support for Llama models is currently limited and buggy (we have opened an issue that needs to be solved). It may become a rising star due to its better organization, but it has yet to be production-ready.
Additionally, we researched and briefly examined language models support in Gemma and NCNN.
- Google recently released its gemma.cpp, another development worth noting. While we haven’t tested it as an inference engine, it could interest those looking to utilize Gemma models. This framework appears to exclusively support Gemma models.
- NCNN, on the other hand, is a popular ML framework for Android devices. However, it has limited support for small language models, with only the 7B llama model reported to run, and needs quantizations lower than int8.

Embedding model runtimes:
- Bert.cpp – This repository utilizes the GGML runtime to execute the embedding models.
RAG:
- FAISS – We developed the library for Android devices. FAISS is responsible for indexing the embedding vectors and enabling efficient search based on cosine similarity.
C++ libraries built:
- OpenBLAS—FAISS requires a library that implements the BLAS and LAPACK interfaces. We incorporated OpenBLAS into a Conan recipe (the official recipe lacks Android support). However, an issue arises as OpenBLAS requires a Fortran compiler that is no longer supported with the Android NDK.
C++ Package management:
- Conan – Responsible for managing all project dependencies. It integrates third-party repositories into our solution and enhances the manageability of Android and x86 builds.
Challenges with Implementing SLM with RAG on a Mobile Device
The key challenges faced during this project were:
1. Memory Limitations
The models’ size is crucial in their applicability on mobile hardware, which typically has 4-12GB of RAM. As a Small Language Model, we consider models ranging from 1B-7B parameters. To match the mobile’s memory constraint, we need to utilize quantization techniques like int8 (Q8) or lower (e.g., 4-bit or 5-bit representations). It is also important to mention that we can’t use all the memory; depending on the OS, we need to reserve 2-3.5GB for Android and other application components. Operations such as sparse kernel multiplication for pruned models have yet to be widespread in mobile frameworks like llama.cpp. Still, this field is progressing rapidly and will soon allow for the execution of larger models and/or faster inference.
2. Platform Independence
The Android platform has its own set of requirements for building applications. All the necessary components of the developed solution were designed so that the codebase should only be rebuilt or require minor tweaks specific to the target platform. Consequently, we implemented a library with a terminal application that can be deployed on Android devices and a regular x86 computer. Keeping the core functionality as a native-built shared object will allow the library to be used in regular Android apps (written in Kotlin) and Flutter (with Dart). Both require only wrappers on the public interface for the core RAG library.
3. Not Mature Enough Inference Engines
SLM inference Engines are evolving rapidly and still need to mature. Currently, llama.cpp is the best choice and supports more models than any other framework, but as a rapidly growing repository, it is somewhat disorganized. Additionally, it does not target Android and mobile performance optimization as the primary goal. Android GPU support via CLBLast is not producing correct results and is slower than the CPU. There is currently no support for pruning and sparse kernel operations. On the other hand, ExecuTorch seems to be well-organized and offers Qualcomm’s kernels for massive inference speed-up, but it is not yet mature enough to run Language Models. We expect the situation to change dramatically in the upcoming months.
4. Missing Features in Runtime Technologies and LLM Libraries for C++
The products are designed to deploy language model-based applications and systems, mainly targeting cloud-native deployments and the Python environment. In some cases, features ready to use in Python (i.e., more advanced retrieval techniques like hierarchical search) must be implemented from scratch in C++.
5. Android Constraints – a Single Process
Android deployment imposes constraints, as the entire application must be contained within a single process. This results in a much narrower choice of technologies like vector databases, not to mention that there is no clean way to build and include Fortran dependencies.

Performed evaluations
Here, we would like to discuss key findings from performance benchmarking.
Retrieval
The retrieval part was evaluated on a sample dataset containing a few PDF documents on the public Internet. The metric measured was mAP (mean average precision), which assesses how much relevant information was retrieved correctly.
RAG – evaluation datasets:
- Source documents found in public resources containing the standard operating procedures for areas:
- Construction workplace safety
- Warehouse procedures
- Grocery store worker instructions
- COVID-19 guidelines
- Queries and expected vital points to be retrieved were created manually.
As the best performing models, we chose the gte-base family. Depending on the memory available on the device, our recommendation is as follows:
-
- gte-base/fp32
- mAP 0.65 at 3 chunks and 600 tokens
- ~0.5GB
- gte-base/fp32
-
- gte-large/fp32
- mAP 0.65 at 2 chunks and 200 tokens
- ~1.5GB
- gte-large/fp32
The bigger model is better because it is sufficient to return the top-2 chunks to achieve an mAP of 0.65 on our dataset, with an average of 200 tokens for the SLM to parse in the next step. However, we need to allocate 1.5GB of RAM for this bigger model. The smaller model is 3x more lightweight at only 0.5GB, but it requires the top 3 chunks to achieve an mAP of 0.65, resulting in 600 tokens for the SML to process in the next step. This means that the SML will have more work to do (as it needs to process 600 tokens compared to 200 tokens) and potentially more challenging work (summarizing/reasoning with more non-relevant contexts). In other words, using a better embedding model can reduce the SLM input size. The smaller input prompt for the SLM model will be reflected in a shorter time without any output from the LLM (the prompt decoding step in llama.cpp).
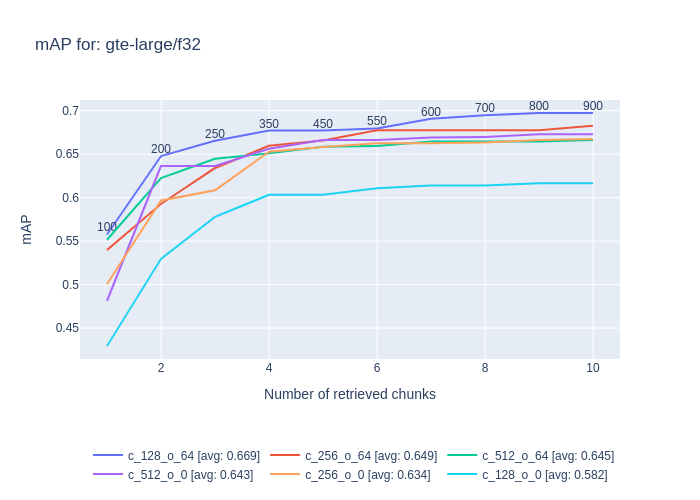

The plots show top-k (Number of retrieved chunks) on the X-axis and mAP of the retrieval on the Y-axis. The number in the plot, close to the line, is how many tokens the entire retrieved-context is built from. Each plot shows a different model under a few configurations, where c_xxx means context size and o_XX means overlap between contexts when calculating embedding. For each query, a certain number of ground truth contexts are expected to be retrieved. For each query, the precision is calculated by correctly_retrieved_chunks_num / all_gt_chunks.
Embedder speed
The retrieval is fast, as user queries are often short.
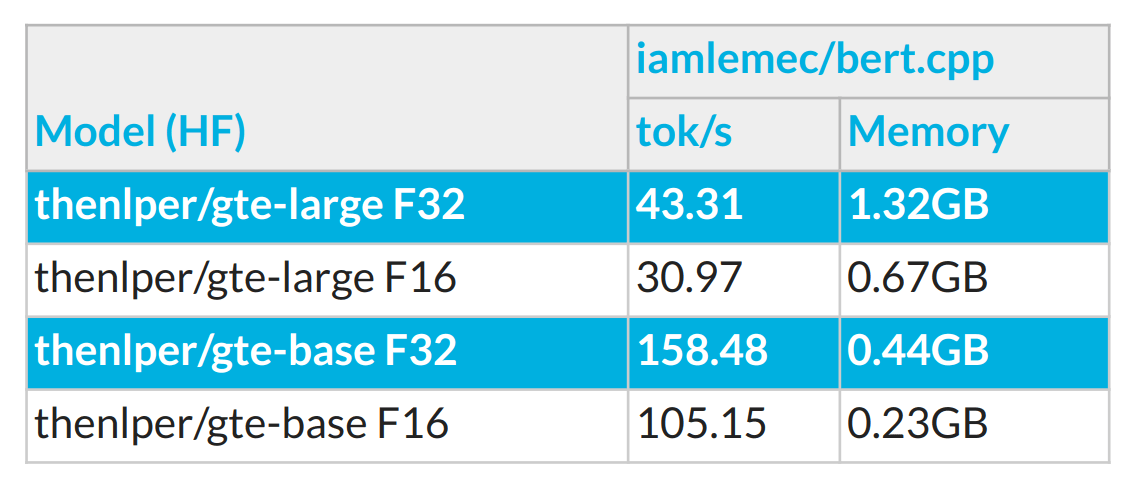
The base model is 3x faster and occupies 3x less memory. But if memory is not a constraint, we suggest going with the larger model as it achieves better mAP and needs fewer chunks and tokens to achieve comparable mAP, making the next step, SML inference, way faster and easier as a task
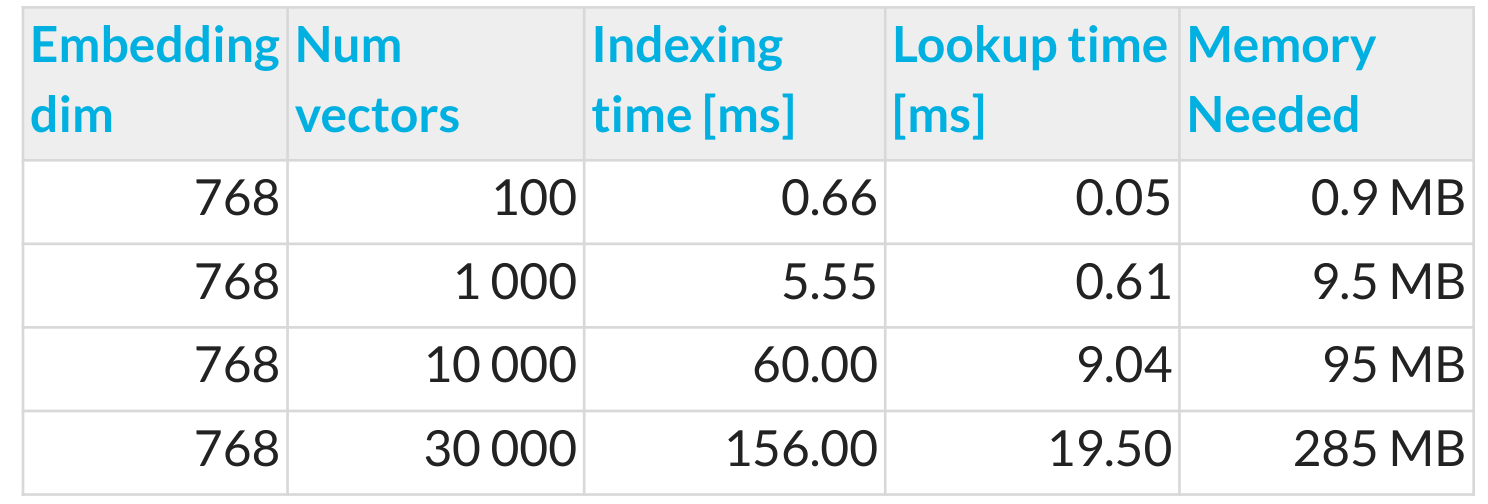
Retrieval Indexing performance.
For retrieval, we used the Faiss library. Even though indexing is needed only offline in our case, we also show here on a benchmark that it is fast enough to consider it on a device. Searching time is blazingly fast for CPU index search. Also, a benchmark of the RAM needed for embedding shows that you can push thousands of pages without worrying about device memory. Num vectors in several embeddings, each corresponding to one text chunk; in our case, one page was like 6-10 chunks.
SLMs Benchmark
Here, we were evaluating models in the 1-3B range. It is possible to push 7B models with lower quantization levels, but they are slower and require memory that is available only on high-end smartphones.
Speaking about the memory, here are the RAM results needed per model and quantization level.
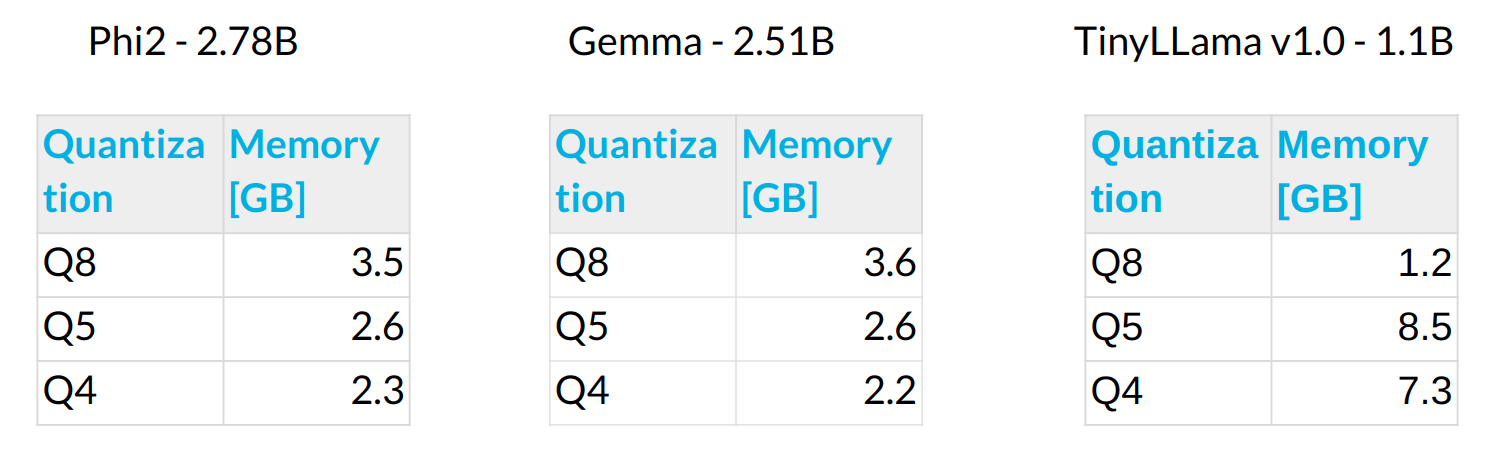
The lower quantization means some weight is stored with less precision. It is a severe reduction with needed RAM.
Plots show the generation speed for SLM on two mobile devices:
- Galaxy S24 Ultra: 12 GB Mem, Snapdragon 8 Gen 3
- S20FE: 6 GB Mem, Snapdragon 865
and 3 quantization levels (the lower-end device has 6GB memory and could not run some Q8 models).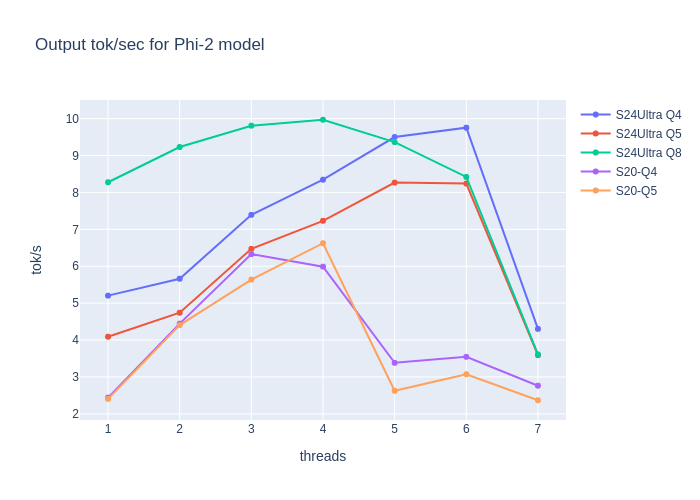
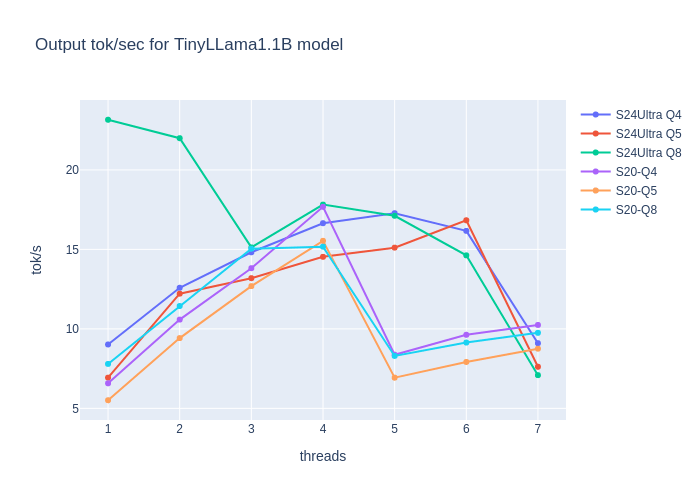
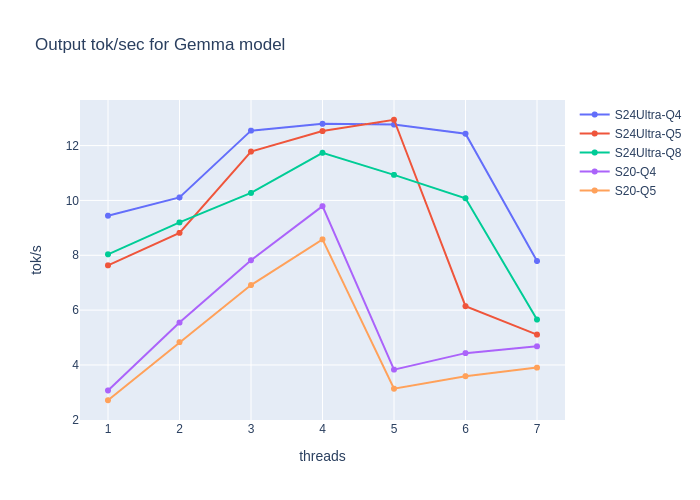
The generation speed of 5-10 tokens per second might be considered fast enough for a good user experience. More important here is eval prompt time (how fast models read contexts and user queries), as contexts might be really long. Even though eval time is usually similar or 2x faster than generation time for tok/sec, time to first token (input lag user needs to wait for the first token to be generated) influences experience negatively.

Here, we can see that in the worst-case scenario of 1000 tokens (query + contexts), users must wait even 50 seconds after prompting the system.
SLM model response quality evaluation
But how well did the SLM fabricate the answer assuming retrieved contexts (not always correct) and user query as input? Two approaches were used: Ragas (an automated tool for RAG evaluation with an LLM-as-a-judge approach based on OpenAI models) and human-based manual evaluation. For Ragas, three metrics were calculated:
- Answer Correctness – the accuracy of the generated answer when compared to the ground truth,
- Faithfulness – consistency of the answer given the context,
- Answer Relevance—how pertinent the generated answer is to the given prompt. A lower score is assigned to incomplete or redundant answers.
For Human manual evaluation, two metrics were calculated:
- Averaged Score – scores in float range 0-1 mixing how correct the answer is and how good context is utilized, eventually punishing models for excessive off-topic content,
- Averaged Hard_EQ_1 Score—as above, but thresholded to accept answers as correct only for those who scored a full 1.0. If not, a 0.0 score is assigned.
Three models in the range 1B-3B were evaluated:
- phi2 – 2.78B Microsoft SLM released under MIT,
- gemma – instruction tuned 2.51B Google SLM with gemma-terms-of-use license,
- tinyLLama_v1.0 – 1.1B LLama model under apache-2.0.
Dataset:
- Firefighters dataset—a tiny, handcrafted dataset using online-available PDFs to measure SLM quality given the pre-defined contexts. It consists of 24 human-crafted questions and answers and context grabbed from firefighters’ documents.
- Phi-2/TinyLlama/Gemma evaluated for Ragas and Humans Score.
In the first stage, we decided to look for a quickly handcrafted prompt with a proper template. Using an adequate template proved crucial—without it, models tend not to halt quickly, talk about unrelated things, and overall response quality is worse.
phi2
example prompt:
Instruct: Generate answer to the Question, using provided context.\nContext: {space_separated_content}\nQuestion: {user_question}\\nOutput:
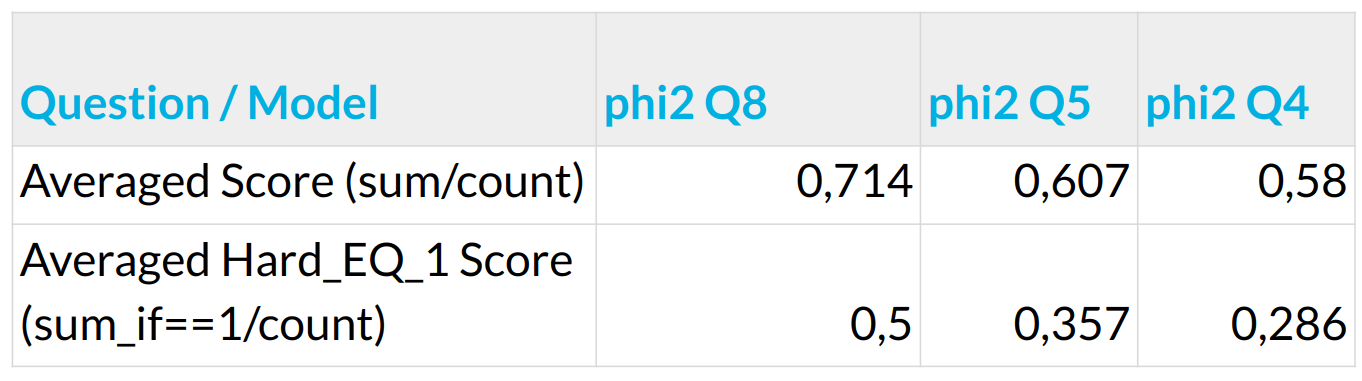
At this stage, the impression was positive and, as expected, showed the supremacy of less aggressive quantization. The model did overall good for the positive notes, showing a sign of correct reasoning for not the most straightforward question. Sometimes, despite missing contexts, the model was able to answer correctly. It might be attributed to the generalized skill of improvising and the model relying on its embedded knowledge from the pre-training. On the negative side, the model produced overwhelmingly long answers at this stage. Sometimes they were correct and relevant, but short, concise responses would be preferred.
The big issue with phi2 at this stage (for this templated prompt) was, even after correctly responding, producing additional questions and answers (starting with another Question: token) or changing the topic and continuing the monolog. Here, we observed that some of these (change topic) behaviors start from repetitive patterns (like {correct_answer} Output: unrelated content). One idea would be to apply post-processing and cut off these patterns; however, some ways the model goes to the next topic are creative and impossible to catch by a simple pattern matching. Also, a brute-force post-processing like that could harm some correct responses. The other idea would be to work with prompt engineering to better instruct the model for shorter answers and improve quality, which we have tried in the following steps.
Eval with Ragas
As a next step, we have constructed a small dataset for our needs (firefighters dataset) to check Humans vs automated Ragas eval.
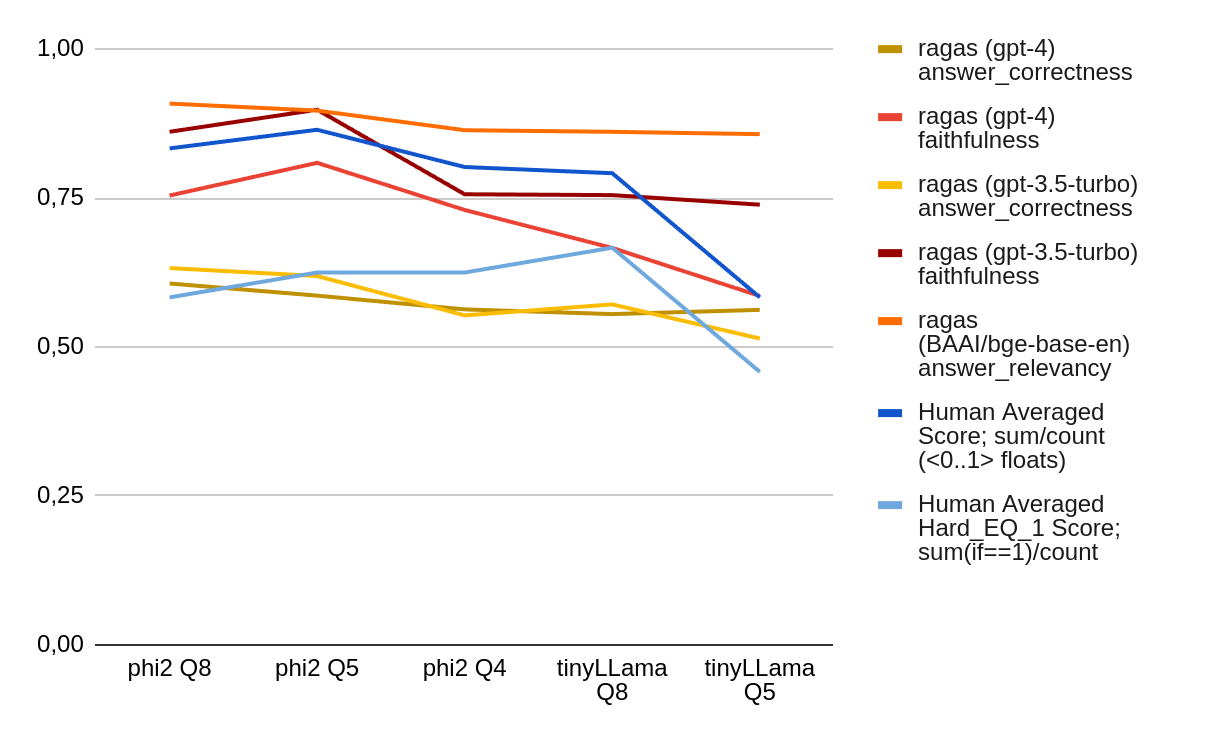
One question was whether we can rely on Ragas’ Evaluation and how it relates to our human scores. This tiny test cannot be treated as a conclusive answer, but using Ragas might help automate evaluation tests. It would be too much to say that Ragas correlates well with human answers (in general), but at least for this small dataset, that looks good. Nevertheless, human checking on top of that (for smaller datasets) should be standard practice. It is worth noting that by keeping the same seed (seed_id for generating the answer with LLM), we can see an increase in the results for less aggressive quantizations on Ragas metrics.
Here are the impressions:
- human evaluation scores and Ragas correlate (with few exceptions) on this small dataset,
- a good practice would be to run Ragas on large datasets and then validate with human evaluation,
- scrolling through answers when human evaluation reveals model weaknesses; some of them can be addressed with prompt engineering,
- it’s also worth noting that Ragas can now help with synthetic RAG dataset generation; we didn’t test this functionality, but readers might find it interesting.
Better Prompt Engineering
In the next step, we checked the influence of prompt engineering on the answer.
As a general note, we achieved better results by:
- Instructing models what are contexts; instead of space-separated contexts, listing contexts separately and providing the id, like that
context_id: {context}\n. - directing the model to produce short but concise answers, relying on the contexts,
- and prompt engineering to counter the model’s flaws independently per each model.
We learned that each model has its problems and needs separate prompt engineering. Here, we show some issues with the Gemma model and how we can address them by modifying the original prompt.

Prompt engineering (without prompt template) after applying the above:
Generate a concise answer to the User Question using the provided Contexts. Read carefully, as the answer is always in one or more contexts. Be aware that not all contexts must be relevant. Contexts:\n{join_contexts}\nUser Question: {prompt}
where join_contexts are newline contexts with hardcoded context_id:
context_0: some text here
context_1: some other text here
…
context_n:…
This makes it easier for models to cite directly by context number.
Injecting these into the prompt helped (and in some cases wholly removed) the issues when manually scrolling through the answers. With the above examples and some techniques like ‘use step-by-step reasoning / read carefully,’ we were able to improve from naive prompts.

Conclusions
The most important takeaways from implementing SLMs with RAG on mobile devices:
- While it is indeed possible to run SLM on edge devices and have satisfactory results for applications such as RAG, both in terms of speed and quality, some important caveats need to be mentioned:
- Heavy memory constraints. Recent phones with 12-16GB+ RAM can run models in the range 1-3B and even those in the range 7B (here, quantizations Q5, Q4, or lower). For devices with 6GB RAM, we could run Q5-quantized Gemma and smaller models. 4GB is challenging, but models like 1.1B TinyLLAMA can still be run there.
- Speed Constraints. Newer smartphones are admirably faster. Runtime becomes slow for the longest contexts; for the models with 20 eval-prompt-token/sec, it means that if the context has 1000 tokens, it will take 50 seconds before models start responding (worst case scenario). Check more details in the report.
- Early insights are that for models like Gemma or Phi2, quality can be satisfactory for RAG purposes.
- The rapid growth of supported models and better inference/memory-efficient models are expected shortly.
- The llama.cpp is growing in popularity. It might also be used for cloud model serving. It had a rapid adoption of the Gemma model (2 days).
- Executorch is an uprising star. Qualcomm kernels have very impressive runtimes for exemplary ML models like image segmentation. However, as of today, LLM support is poor, and the model is not yet production-ready.
- The vector database search could be better (compared to Python/cloud services). There is no hybrid search feature and no sparse search, and there is no easy, out-of-the-box way to bring those to the inference/cpp site.
- The latency for the SLM to start generating a response may be quite long. This delay time is related to the input model prompt length. It’s essential to get as much output from the retrieval part as possible. However, it’s getting faster with recent, more powerful phones and sophisticated Android-targeted inference engine speed-ups.
- Evaluating SLMs requires more work with bigger datasets than our tiny handcrafted firefighter dataset. Automating the generation like that would be helpful, and it seems the Ragas library has introduced such a feature, which might be an interesting approach for continuing the project.
- Given the limited lifespan of these projects, not all findings, including better prompt engineering techniques from the eval site, were migrated to the inference site.
With engineering effort put into inference engines, a growing community for SLMs, and tons of research put into it, we expect that in the coming months (sometimes even weeks), the situation will change drastically. Not only will models become more powerful for this 1-3B Range, but the inference site will improve in terms of speed and potential memory consumption.
Ongoing Research
Let’s briefly mention ongoing research efforts that aim to break the current limits of SLMs (or LLMs in general).
- Better hardware utilization by dedicated kernel ops (e.g., Executorch + Qualcomm) [7]
Here, it’s purely an engineering effort, but it is worth mentioning, as proper GPU kernels with hardware-aware optimizations can significantly boost Android runtimes. - `1-bit` LLMs [1]
The idea is to go beyond classic quantization and train a model from scratch that keeps weights on merely 1.5 bit, optimizing some multiplications onto addition. The authors showed they could pair with fp16 models, and if this holds for other SLMs we have tested, someone would need to retrain models and add support, e.g., in llama.cpp, but memory and inference speed benefits can be huge. This technique would allow us to bring bigger models to the mobile, which is inaccessible for now due to RAM constraints. - A mixture of Expert (MoE) like in Mixtral of Experts [2] (coarse grain sparsity)
The idea of coarse grain sparsity is where, during inference, only some path(s) are active, and not every weight/layer needs to be calculated. This family of techniques does not lower needed memory but speed inference (as only a sub-part of the model needs to be active during inference). There is also a positive inductive bias to make model parts sparse (like paths of layers) with separate modules (a bunch of layers) specialized, resulting in more powerful models that train faster. In the future, this technique could be combined with sharding – loading some parts of the models from HDD to RAM – but this time minimizing the delays. - Mamba[3], MoE Mamba[4]
Here, there is a trend to mitigate quadratic attention mechanisms (the more significant the context window, the more computationally heavy it becomes) in favor of ‘linear’ attention with RNN/LSTM. Authors claim that Mamba models became significantly stronger for a given capacity than their transformer counterparts. llama.cpp has a PR that brings Mamba support—it’s not yet finished.
MoE Mamba is a combination of both techniques, a mixture of experts and Mamba. Here, the authors also show that both techniques are complementary, increasing model quality. - Sparse kernels+pruning (fine grain sparsity) [5][6]
It is about sparsity at the micro-level, where the model is pruned, and some weight gets locally removed. llama.cpp currently lacks support for sparse kernel operation and sparse weight storage. With minimal quality loss, there is an opportunity here to save more RAM and maybe even speed up inference. This technique, when mature, can also bring bigger models to mobile environments. - Draft + Verify [8]
Last but not least, a technique for speeding the inference by having a lightweight (weak) drafter and (strong) verifier NN on top of the drafter. Drafter proposes many tokens at once, and verifiers can verify them in parallel – then, as many tokens are accepted, the first rejected token from the verifier appears in chronological order. Language model training is parallelized (tokens+masking trained in parallel), but the inference is calculated token-by-token. The big deal is that verifiers can work in parallel, verifying many tokens in contrast to sequential, step-by-step token fabrication like in the current models we have tested. This technique might be brought to mobile someday, again increasing inference speed. - Symbolic Knowledge Distillation [14]
Rather than training SLMs from scratch, distilling skills and abilities like reasoning from the influential teacher (big LLM) via proxy NN critic can result in more powerful models. This is another paradigm shift for removing unrelated knowledge from small models by distilling essential skills and abilities and relying on a RAG-like pipeline for knowledge retrieval, which can result in lighter (and more powerful) models.
We have mentioned just a few techniques, but the research area in this domain is much larger, including dynamic neural network structures, a distillation of reasoning capabilities, and memory-augmented neural networks.
I was a lead engineer on the project and the author of this article. However, the entire team contributed to its success, so I would like to give a big shoutout to Marcin Ochman (Senior Engineer), Paweł Kaczmarczyk (Senior Engineer), and Artur Zygadło (Project Manager) for making it possible.
Tech Stack:
[7]https://pytorch.org/executorch/stable/build-run-qualcomm-ai-engine-direct-backend.html
[9] https://github.com/ggerganov/llama.cpp
[10] https://github.com/skeskinen/bert.cpp
[11] https://github.com/facebookresearch/faiss
[12] https://conan.io/
[13] https://docs.ragas.io/en/stable/
Active Research:
[1] https://arxiv.org/pdf/2402.17764.pdf
[2] https://arxiv.org/abs/2401.04088
[3] https://arxiv.org/abs/2312.00752
[4] https://arxiv.org/pdf/2401.04081.pdf
[5] https://www.youtube.com/watch?v=0PAiQ1jTN5k
[6] https://huggingface.co/neuralmagic
[8] https://arxiv.org/html/2401.07851v2
[14] https://www.youtube.com/watch?v=H_IfCbpS6G0
[15] https://arxiv.org/abs/2404.01744
