

Does Your Model Hallucinate? Tips and Tricks on How to Measure and Reduce Hallucinations in LLMs
As the language models are improving, their adoption is growing in more complex tasks such as free-form question answering or summarization. On the other hand, the more demanding the task – the higher the risk of LLM hallucinations.
In this article, you’ll find:
- what the problem with hallucination is,
- which techniques we use to reduce them,
- how to measure hallucinations using methods such as LLM-as-a-judge
- tips and tricks from my experience as an experienced data scientist.
Let’s start with some examples that illustrate the problem the best.
Introduction to hallucinations in LLMs
We can observe the trend that new releases of the models are limiting hallucinated responses. If you remember ChatGPT eagerly describing the world record in crossing the English Channel on foot:

Source: https://x.com/goodside/status/1609972546954317824/photo/1 (Published: Jan 2, 2023)
Looking at the current response – it’s correct:

Source: ChatGPT, Oct 2024
Which is great! It’s fantastic to see the progress. Nevertheless, we shouldn’t consider the problem as solved. Especially in domains like healthcare, legal, and finance we should pay extra attention to monitoring and evaluating the systems taken into production.
Let’s take the legal domain as an example: a few lawyers cited non-existent cases because they used ChatGPT. Apparently, they didn’t verify the information…
In the medical field, probably everyone has heard of the dangerous conversation with a mental health chatbot that suggested taking a user’s life as an option.
To analyze the scale of such behavior, researchers asked an LLM to respond to frequently asked questions about medications. Their study revealed that 22% of the responses could cause death or serious harm.
Such responses can have severe consequences, so when the stakes are high, we should employ aggressive strategies against LLM hallucinations. You will learn about them from this blog post.
What is an LLM hallucination?
LLMs are, by design, generative models which are taught to follow user instructions. They are good at this but not perfect. If they were – we wouldn’t have a phenomenon called hallucination. So, what is the source of hallucination? There is a gap in the instruction-following ability of the LLM. LLM doesn’t know it is fabricating information, or giving nonsensical outputs. If it knew – it would answer correctly (sic!).
Hallucination happens when the model generates responses that are not grounded in knowledge about the world or in provided context.
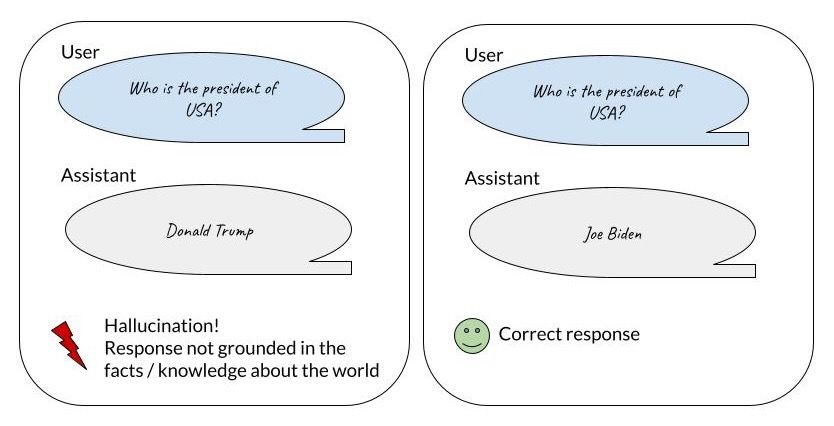
Example of a hallucinated answer (left) and a correct response (right). Source: own study.
The risk of hallucinations usually increases when we’re dealing with tasks that are difficult for the model, for example:
- applying LLMs for knowledge-intensive question-answering,
- applying LLMs on domain-specific data (probably not known by the model, maybe not understood well).
Hallucinations can be divided into two categories based on the source of knowledge:
- extrinsic hallucination is when the model does not comply with the knowledge gathered during pre-training
- in-context hallucination is when the model does not follow the knowledge passed in the context (prompt). [1]
Now that you know what hallucination is – let’s go through techniques that help to reduce the problem.
How to reduce hallucinations
Many techniques exist which help to limit the problem of hallucinated responses. We can divide the techniques into two categories:
- applied during training/fine-tuning,
- applied at inference,
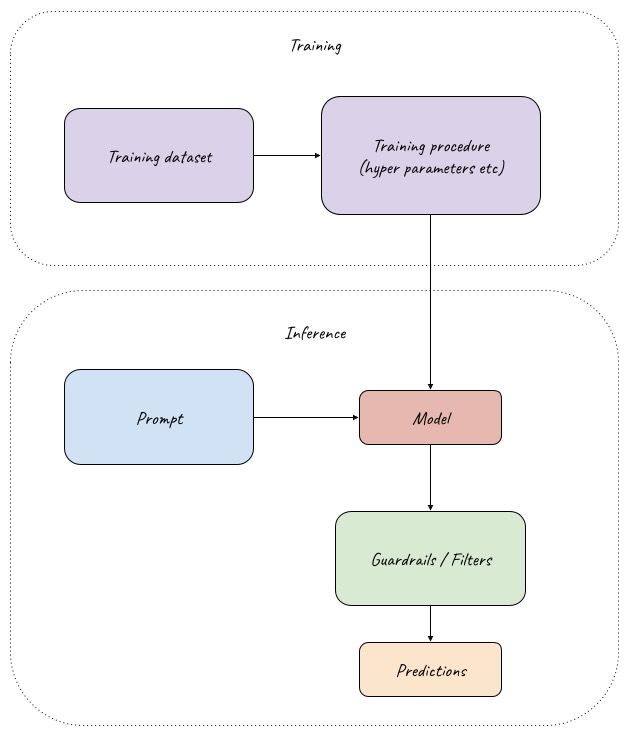
Model creation and prediction flow. Source: own study
How is LLM created? By training a model on a sufficiently large and representative dataset of good responses to given prompts.
During training/fine-tuning we can manage the training dataset and procedure. For example, if we want to apply an LLM on our domain-specific data, we can decide how large a dataset to prepare, and what kind of examples to include to ensure that our model doesn’t have knowledge gaps.During inference, we have limited influence on the model – we can no longer change what the model knows. But we can ensure it doesn’t respond with what it doesn’t know.At inference, we can prompt the model not to provide an answer if it’s not sure, apply RAG (retrieval augmented generation) to ground the responses in additional knowledge, or apply filtering techniques on the predictions before returning them to the user.
The focus of this post will be the techniques that can be applied at inference time. Those techniques are usually the most practical and easy to apply. Also, when using proprietary LLMs, we don’t have the possibility to change the training process.
Prompt engineering
Let’s start simple. As we all know from the Pareto rule, the simplest techniques will give us an 80% gain with 20% effort. Very often, the simplest solution is also sufficient. With this in mind, we strongly recommend starting with prompt engineering.
Tell me what you don’t know
When prompting LLMs to solve a chosen problem, we can add an instruction to return an “I don’t know” answer when the model is in doubt.

Pros and cons: In practice, we can observe that often models “don’t know what they don’t know”, and are very happy to respond anyway. So, this technique – although simple – is limited.
Think first
More advanced prompting include:
- Chain of thought: generate an explanation before providing the final response. Source
- ReAct Prompting: recursive prompting technique to include reasoning and capture the uncertainty of the responses. Source
- Chain-of-verification: first draft an initial response, design verification questions, answer them, and generate its final verified response. source
Including explanations, and more advanced prompting strategies increases the reliability of the responses and reduces hallucinations.
Pros and cons: In practice, it is worth considering that most advanced techniques are more expensive. Either due to the increased number of tokens produced (chain-of-thought), multiple LLM calls, or both factors, the response will be more expensive and take more time (latency).
RAG
Retrieval Augmented Generation – which can be seen as an extension of prompting by including external knowledge via prompt – can be applied at inference time. It is a vastly applied technique that not only helps to incorporate new knowledge into the system, but, as an effect, also reduces hallucinations.
If the model has a correct source provided in the context, it is much less likely to generate responses that are not grounded in the context. Additionally, if no correct context is found for the user query, we can automatically generate an “I don’t know answer,” which can also help reduce the risk of generating a hallucinated response.
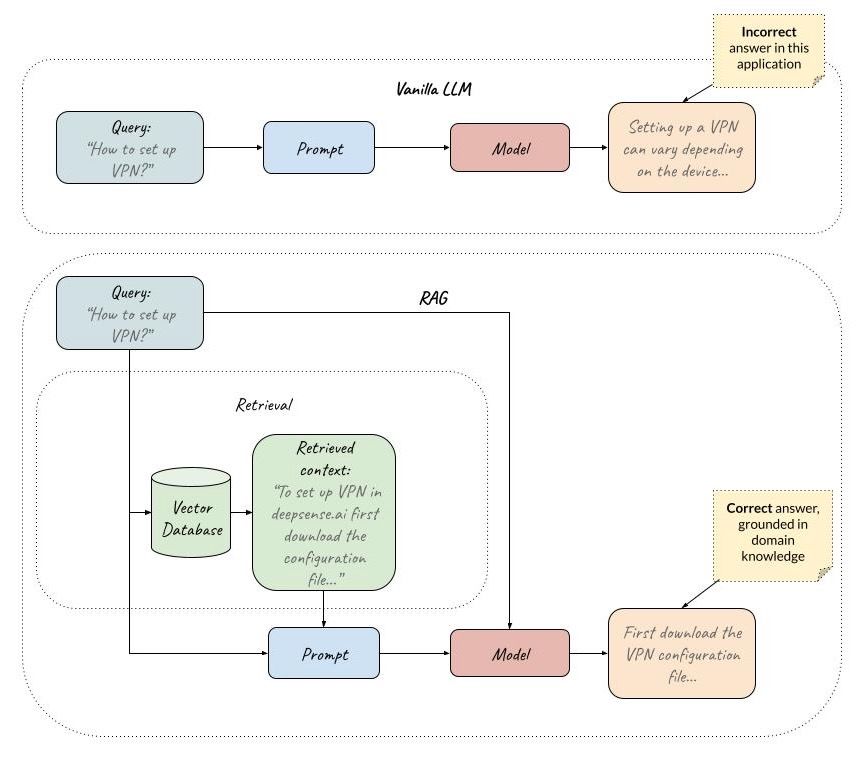
RAG pipeline – RAG grounds answers in domain knowledge. Here: the company documents. Source: own study
Pros and cons: This technique proves to be highly effective in practical applications, and even though its setup requires more engineering effort, RAG has become a GenAI application architecture standard.
If You want to know more about RAG, dig deeper into our blog posts about this topic:
From LLMs to RAG. Elevating Chatbot Performance
Implementing Small Language Models (SLMs) with RAG on Embedded Devices
Filters and guardrails
We described what we can do at the prompting stage; now it’s time to discuss the techniques that can be applied with a fixed prompt, after the models respond.
Given our LLM predicted responses, we can create filters that will decide if a hallucination was found or not:
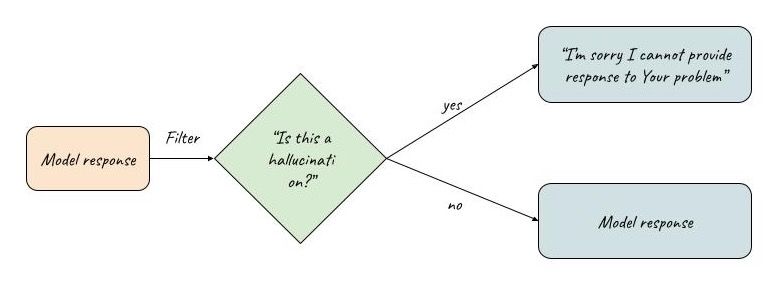
Hallucination filter. Source: own study
Hey LLM, is this a hallucination?
We can prompt (preferably different) LLM to decide if our model’s responses contain hallucinations. There are a few prompting strategies that can be used to filter them out:
- Simple prompting: “Is there a hallucination in this response?”
(Simple and effective – best as the starting point) - Chain-of-thought prompting: forces the model to generate the information from the document before giving the conclusion.
(Usually more powerful, but also slower and more costly) - Sentence-by-sentence prompting: break the response into multiple sentences and verify facts for each
(More detailed, can include multiple LLM calls, or a single call to return a response for each sentence.)
In practice, we found that prompting an LLM to be the hallucination detector works very well if it’s applied in an RAG pipeline:
- firstly, RAG reduces hallucinations by grounding responses in a context
- secondly, the context included in the hallucination detection prompt gives the model a reference.
Worth keeping in mind is the fact that strong LLMs are usually better at hallucination detection (GPT3.5 works reasonably well, GPT-4o is very good).
Pros and cons: this is an easy-to-apply approach, but it does require an additional LLM call, which increases both cost and latency.
Logprobs
Internal model characteristics may contain much more information than we expected. Researchers found that there is a correlation between model confidence and hallucinations. This technique uses information about the internal probabilities of the tokens generated in the response. [2]
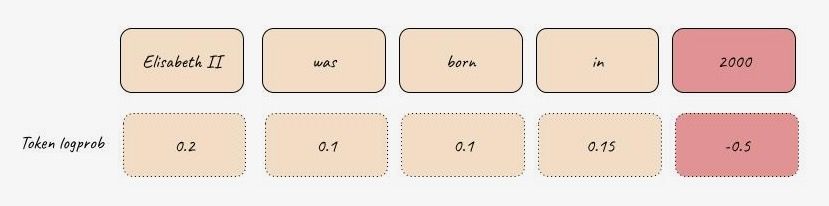
Token log probabilities. Source: own study
So, a practical approach would be based on thresholding token log probabilities of the response and filtering out responses that need to be more confident: we can create filters that will detect hallucination based on low log probabilities.
Note: This solution can be applied to self-hosted LLMs, but not to all of the LLMs hidden by APIs. Worth knowing – OpenAI does provide access to logprobs (see: OpenAI cookbook).
Pros and cons: This technique is particularly appealing if we have to cut costs due to the large number of requests to process – it is very cheap! Another plus is the fact that it doesn’t require additional LLM calls.
Measuring hallucinations
Free-form responses are difficult to evaluate automatically as multiple versions of the correct response often exist. Metrics applied in the “before LLM” era, such as ROUGE or BERT-score, have limited evaluation power and correlate poorly with human judgments. Then, what is now considered the SOTA evaluation method? LLMs! (LLMs-as-Judges in Automatic Evaluation of Free-Form Text, PROMETHEUS 2)
Using LLMs to evaluate LLM responses is called LLM-as-a-judge and is currently the go-to method for automating this process. They are flexible enough to be able to judge different aspects of responses, such as correctness, grammar, and… hallucinations :)
So, what would be the recipe to measure hallucinations automatically? See the example prompt below that can be easily applied to the RAG approach:
“You are a hallucination detector; given a question and provided context, assess if the response is grounded in the context. Please answer yes or no as the evaluation.
Question: {question}
Context: {context}
Response: {response}
Evaluation:”
Let’s try it with Wikipedia article and ChatGPT:
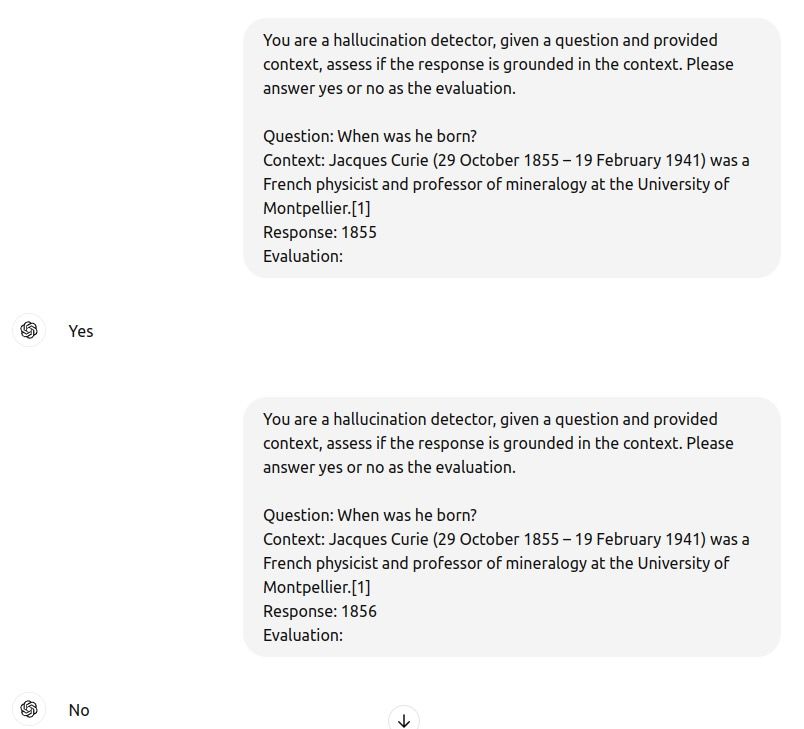
LLM-as-a-judge for hallucination detection with ChatGPT. Source: own study
Works nicely!
This is a simple prompt that can help you get started; other ideas can be found in RAGAS or ARES frameworks.
Although powerful, let’s remember that LLMs are imperfect, so we recommend testing how well they work on your data before relying on them.
Some of the best practices that can help you design an effective LLM judge prompt are:
- use strong LLMs,
- ask the LLM for just one metric / aspect in one prompt,
- be precise with wording, explain what you mean,
- provide example,
- use binary / yes or no values when possible,
- check for biases (self-preference, position bias in comparisons, etc.)
- combine multiple LLMs into a panel of judges to boost quality.
Summary
Although diminishing, hallucinations are still a problem with Generative AI. We have gone through techniques that can help to limit the problem significantly. Starting with prompt engineering and RAG, ending with applying filters on the model responses.
As a summary and a guideline that can help you decide which technique will be best for your use case, see this comparison table:
| Method | Complexity | Latency | Additional cost | Effectiveness |
| Prompt engineering – “Tell me what you don’t know” | easy | low | low | limited |
| Prompt engineering – “Think first” | easy – moderate | medium – high (additional explanations, LLM calls) |
low-medium | moderate |
| RAG | moderate | low – medium (additional context increases latency) |
low – medium | high |
| Filtering – “Hey LLM, is this a hallucination?” | easy | low – medium (additional LLM call) | low | moderate – high |
| Filtering – Logprobs | easy | low | zero | limited – moderate |
- If you want to start with hallucination reduction techniques, start with simple prompt engineering and filtering.
- If you’re dealing with a system that can have near zero tolerance of hallucinations – we advise going with RAG and filtering using strong LLMs.
- If your system is dealing with many requests and costs are the priority – start with logprobs filtering.
And remember – those approaches can be combined! So, to boost the effectiveness, consider using a few different techniques stacked together.
