Applied AI Experts Blog
Explore in-depth insights on LLMs, RAG, AI agents, MLOps, Computer Vision, Edge Solutions, Predictive Analytics, and beyond—delivering value-packed perspectives for both business leaders and developers.
-

deepsense.ai Named an OpenAI Advanced Partner: Scaling Enterprise AI from Strategy to Production

•
•
read
-
-

EDA Benchmark Leaderboard: July 14, 2026 Update

•
•
read
-
-

96.3% Physician-Accepted, Zero Hallucinations: Healthcare AI in Production

•
•
read
-
-
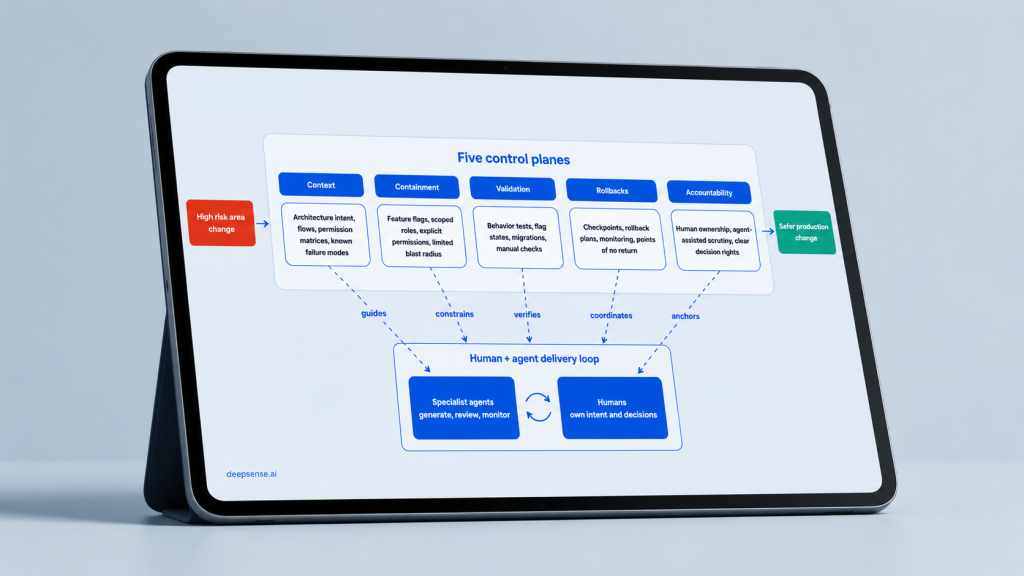
The 5 Control Planes of Agentic AI Infrastructure for Reliable Software Delivery

•
•
read
-
-

deepsense.ai Joins the Claude Partner Network Services Track
•
•
read
-
-
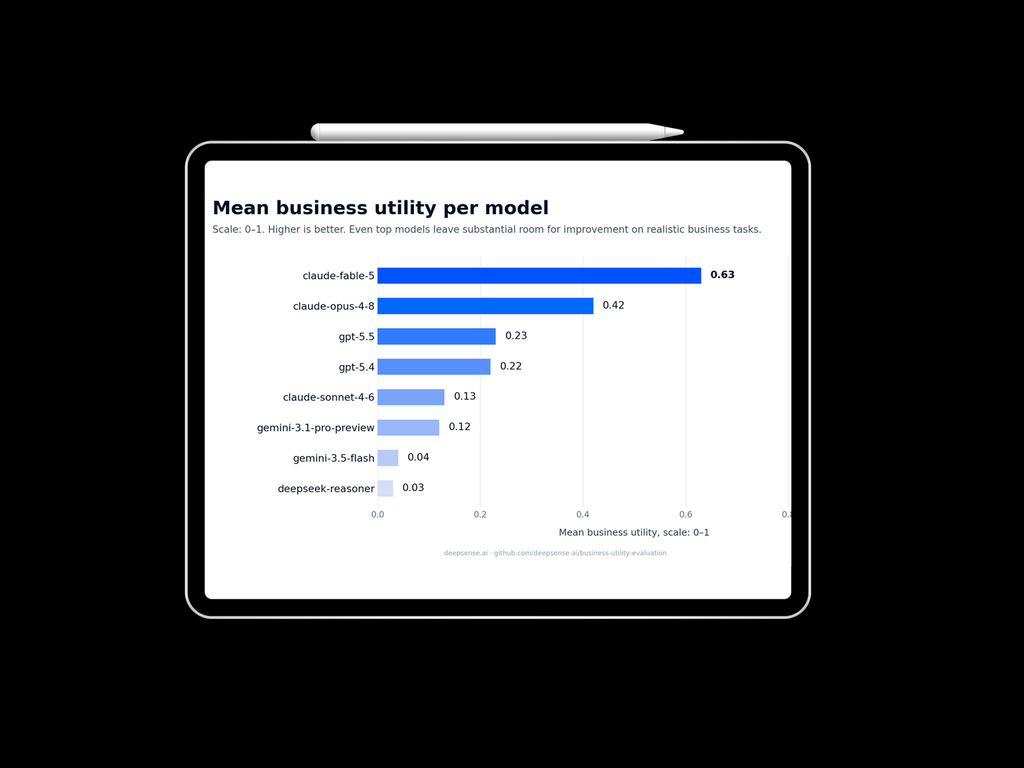
LLM Business Utility Leaderboard: June 11, 2026 Benchmark Update
•
•
read
-
-

Why “Average” AI Isn’t Enough: Introducing a “Business Utility” Metric for AI Model Evaluation
•
•
read
-
-
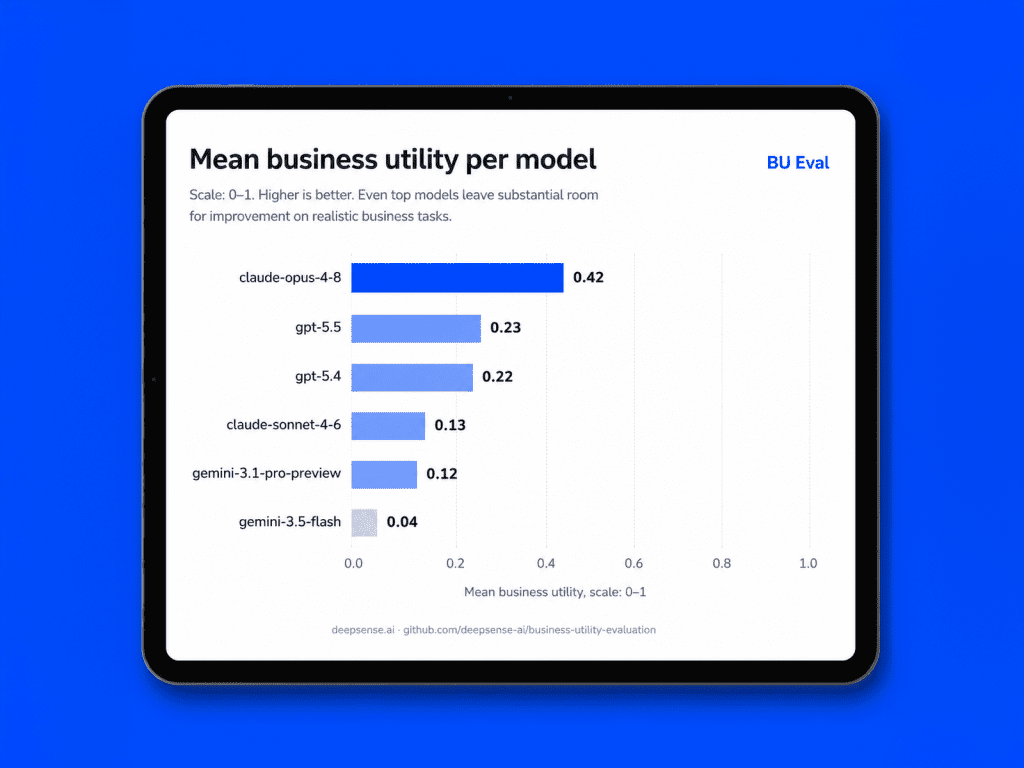
LLM Business Utility Leaderboard: June 3, 2026 Benchmark Update
•
•
read
-
-

deepsense.ai Launches Its Google Cloud Partnership with a Dedicated Gemini Enterprise Practice
•
•
read
-
-

When Code Gets Cheaper, Judgment Gets More Precious: Quality Bottlenecks in Enterprise AI Systems
•
•
read
-
-

GxP-Compliant AI Deployment. The New Competitive Edge in Life Sciences

•
•
read
-
-

Early Access to OpenAI’s Agent Execution Layer: What It Means for Enterprise AI Implementation
•
•
read
-
-
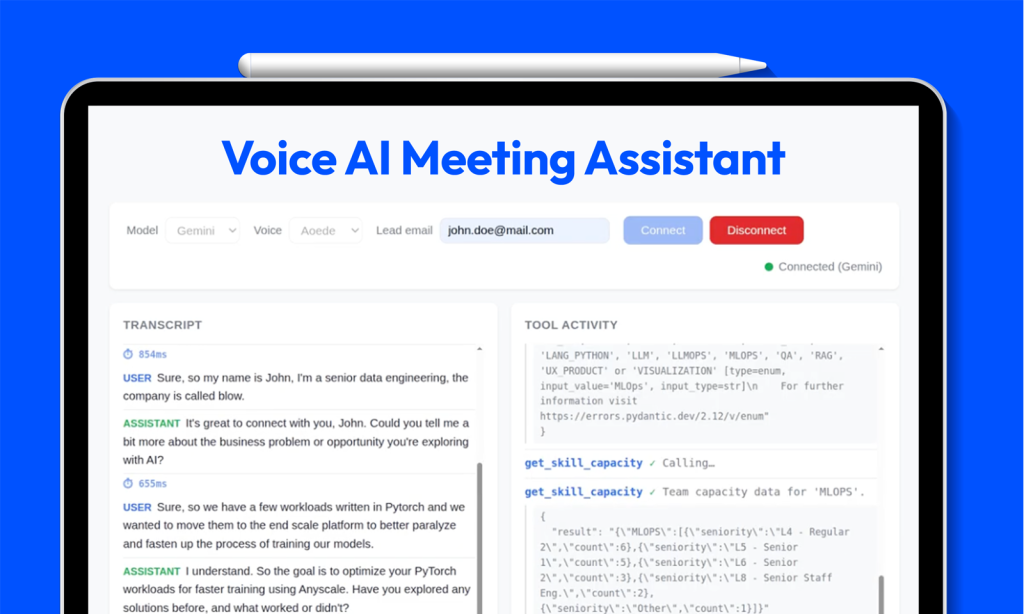
Realtime Voice AI in the Enterprise: Overcoming Latency with Native Audio Models
•
•
read
-
-
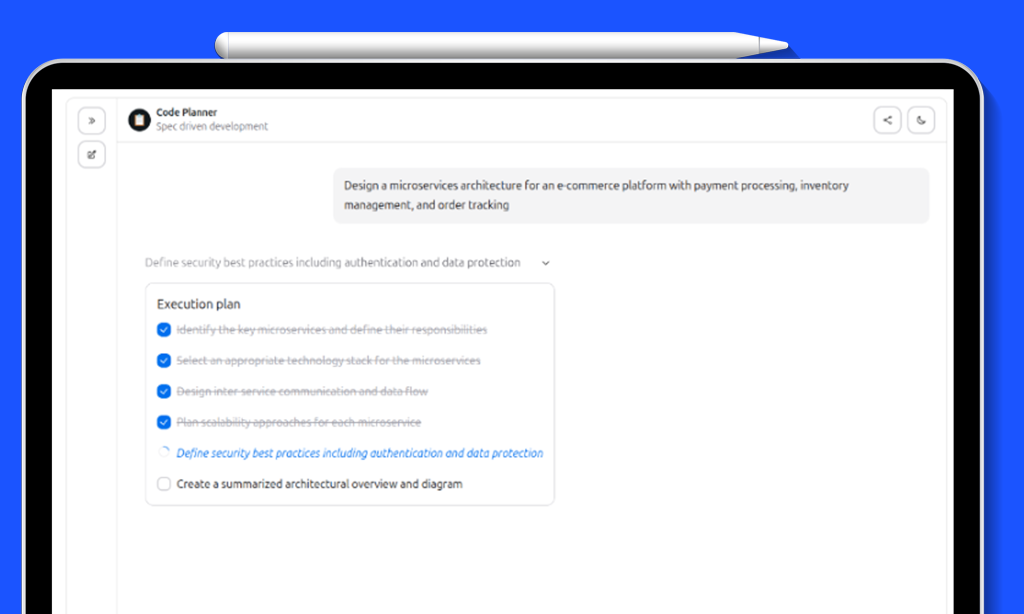
Task Planning, Execution Visibility, and Persistent Memory for AI Agents: ragbits 1.6 release

•
•
read
-
-

Building Production AI Agents: Hooks, Tool Confirmation, and Multi-Agent Orchestration in ragbits 1.5 release
•
•
read
-
-

Orchestration Before Optimization: How to Build Enterprise Agents That Survive UAT
•
•
read
-
-
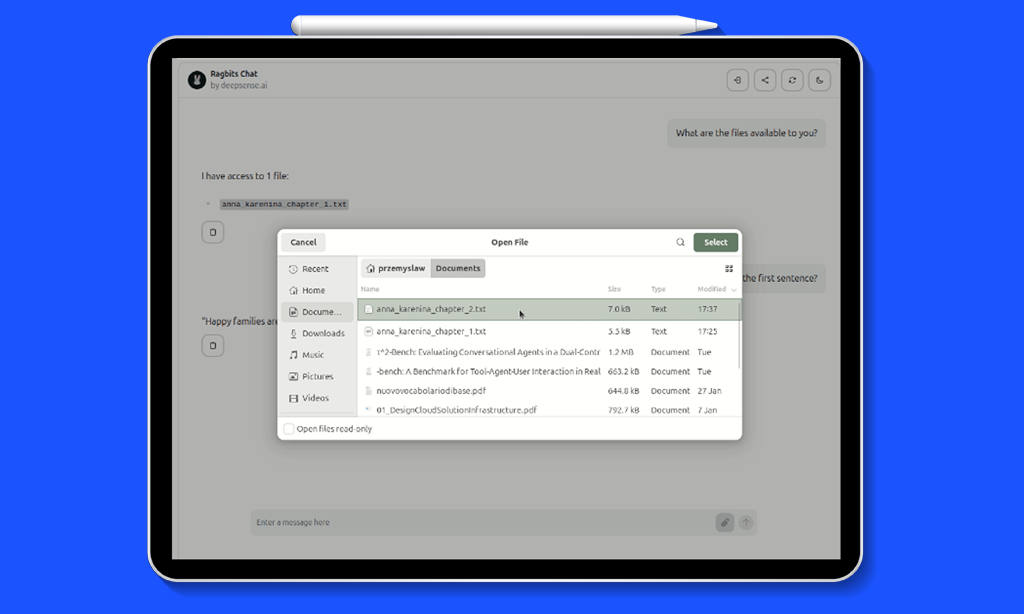
OAuth2, Extensible API Schema, and File Handling for Production-Grade GenAI: ragbits 1.4 release

•
•
read
-
-

From Token Prediction to World Models: The Architectural Evolution After LLMs

•
•
read
-
-

Building MCPs for Regulated Industries: Lessons from Production AI in Life Sciences

•
•
read
-
-

Coordinate or Collapse: Why Enterprise Agentic Systems Break at Scale
•
•
read
-
-

Latency Kills Voicebots Faster Than Bad Models

•
•
read
-