

Evaluation Derangement Syndrome (EDS) in the GPU-poor’s GenAI. Part 1: the case for Evaluation-Driven Development
GenAI, understood as a class of models capable of generating human-like, high dimensional outputs like text, image or sound, is experiencing great success and explosive growth [1, 2, 3]. However, this has also quietly given rise to a critical problem that permeates applied GenAI in its entirety – what we call Evaluation Derangement Syndrome (EDS). In short, EDS is the problem of the widespread lack of a rational approach to and methodology for the objective, automated and quantitative evaluation of performance in terms of generative model finetuning and prompt engineering for specific downstream GenAI tasks related to practical business applications.
In this post, we analyze EDS from a practical, applied, business perspective, drawing from our rich experience in GenAI development for business, both in image generation (with diffusion models and GANs) and LLMs in code generation, retrieval systems, voice assistants, etc. We’ll explore the underlying causes (both technical and business), and examine the consequences it may have for the GenAI community and beyond.We analyze its intricate relationship with GPU inequality [4] and address how the ‘GPU-rich’ (a handful of firms with thousands of the strongest GPUs, as well as resources like data, engineers, and labelers) approach the problem of GenAI evaluation, in contrast to the harsh realities of the ‘GPU-poor’ (everyone else, really). We also discuss the fundamental insufficiency of the ‘pseudo-evaluation’ approaches used by the GPU-poor and sketch a potentially more rational path forward for them: Evaluation-Driven Development (EDD). The subsequent post will take a deep dive into the nitty-gritty practicalities of this approach, drawing from our extensive experiences with Diffusion Models and LLMs in the ‘GPU-poor’ landscape. Enjoy!
GenAI evaluation in the realm of the GPU-poor
For fundamental technical reasons, GenAI does not naturally lend itself to any obvious and reliable analogues of quality monitoring tools (like F1 score, accuracy, precision, etc.) that all data scientists live and breathe when practicing traditional ML. Then there are business pressures to deliver at an extreme tempo, typical of the heated ‘hype economy’ driven by the fear of taking over the target niche in the AI revolution, contributing to the ‘produce fast, test later (i.e., never)’ approach.
Additionally, almost all GenAI contain several evaluation dimensions lying on a spectrum from soft (subjective) to hard (objective). To give specific examples from our own GenAI projects and practice, the evaluation of:
- a chat/assistant includes subdimensions like helpfulness, friendliness, or even political correctness (subjective), vs factual correctness that can be measured in a ‘hard’ quantitative manner for some of the questions/answers (objective);
- a retrieval system may include retrieval coverage correctness (‘hard’ in many cases) and conversation/summary style (soft), similar to the assistant;
- code generation can be broken down into (hard) code correctness/test passing and (soft) code clarity;
- diffusion-based face generation may consist of (soft) image attractiveness, similarity to the desired target, but also (hard) domain adherence, i.e., % of generated images actually containing a face.
This mix of soft and hard evaluation criteria poses technical difficulties (analyzed in this section), and the resulting simple truth is this: almost all GPU-poor researchers working on GenAI applications today work without any rational, objective, quantitative, repetitive framework to evaluate their work or to inform choices – their own or that of the business decision-maker – that depend on them. When dealing with our day-to-day dilemmas we all depend on subjective, arbitrary gut feelings built in short, selective inspections of the systems we train. These are (at best) accompanied by weak numeric pseudo-evaluation (‘broken evaluation methods that put more emphasis on style rather than accuracy or usefulness’ [5]), that do almost nothing to evaluate our specific business capacities (I’m looking at you, leaderboard rankings [6], BertScores [7], BLEUs [8], etc.). The former are used more as a rationalization than an actual trustworthy indicator of performance and a primary driver of our research.
This is truly astonishing when considering the rigorous objective evaluation practices ingrained in traditional ML (Image 1). More shockingly, everybody in the field seems to accept this and move along: if we move fast (as in the production of more and more GenAI), we are fine with not checking the direction (as in objective QA, and in comparison with competition or alternative approaches).
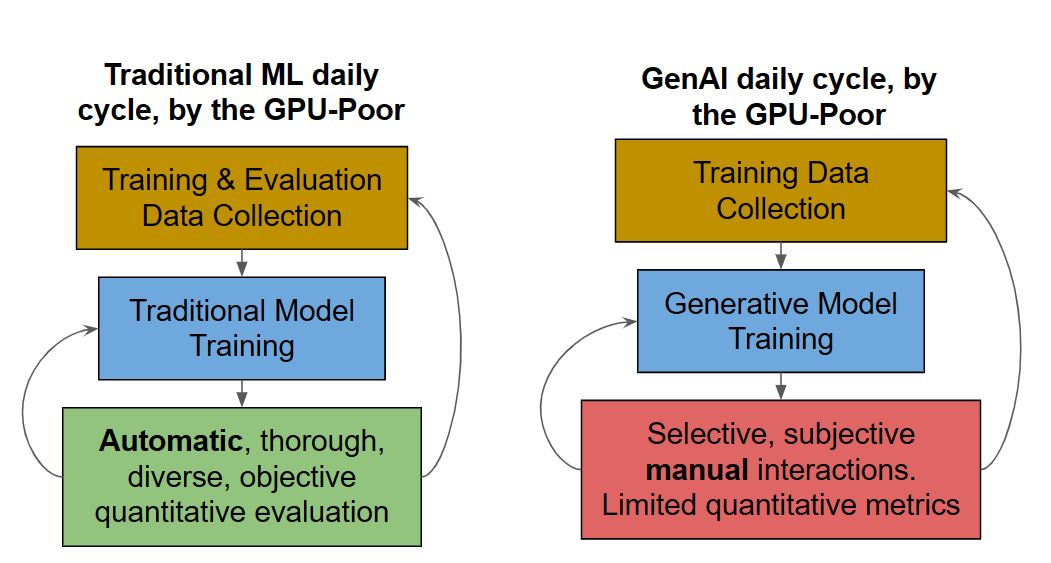
Image 1. Daily cycles as practiced by the GPU-poor. The differences in the evaluation standards are stark and consequential.
This is not an academic or theoretical issue, but a weighty real-life problem with business, technical, and human consequences. Again, deepsense.ai’s wide experience allows us to share a specific story that many GenAI researchers can relate to. One of our valued customers asked us to develop a code-generating solution for a somewhat niche language (think GitHub Copilot’s [9] competition for this language). Even though the team we established consisted of elite LLM experts, the task proved very challenging. Due to the limited time allocated for creating the evaluation pipeline, it relied solely on the BLEU-based evaluations. The main effort went directly into generative model creation itself. This, combined with the release of the new, possibly superior base models over the duration of the project, led to serious internal evaluation issues.
To cut a long story short – our team was highly competent and worked very hard, but had no reliable way of determining if any improvement had taken place. Considering our BLEU-based evaluations, we thought this may not be the case! Luckily, the client’s own internal evaluation at the end of the project was very positive. Apparently, according to the client, our model was visibly superior to both the foundational models and GitHub Copilot. Good enough for us, and another job well done! But, to be fair, we have no idea how objective and extensive this ‘client-based evaluation’ was, or whether this will work next time. Being professionals, we prefer to make our own luck instead of being part of EDS. Today’s GenAI development is full of similar stories, rarely with a happy ending like ours.
In summary, EDS is a serious, practical issue affecting all areas of GenAI, most notably LLMs [10, 11], and image generation (GANs [12], Diffusion Models [13]). Its reach will only grow in the future, together with GenAI use cases. Generative AI can create jokes [14], stories [15], poems [16] and beautiful images [17] for a continuously growing number of applications, but our ability to evaluate GenAI is constantly falling even further behind. Given the scale of the pandemic and the technological, economic, and political impacts of GenAI, EDS truly is a critical issue. Let’s now investigate the underlying causes of this situation.
EDS – business causes
EDS emerges in the GPU-poor domain due to a complex interplay of factors—some technical and others soft, encompassing the economic, psychological, business-strategic, and organizational dimensions. Before delving into the technical reasons behind this situation, let’s take a look at the broader realities of the GenAI business-economic ecosystem contributing to EDS amongst the GPU-poor.
The first EDS-inducing condition is that, since at least 2022, the GenAI business ecosystem has operated permanently in ‘hyped-economy’ mode [18, 19]. In the GPU-poor realm, this means the red-hot fervor of startups [20] competing in a race to quickly find their niche in the GenAI revolution. Or at least respond to the marketing pressure to be a part of GenAI… A pervasive sense of ‘it’s now or never’ exerts enormous pressure on businesses. CEOs of even modest startups aspire to innovate within GenAI, sometimes despite limited technical understanding and unreliable intuitions concerning the likely future GenAI developments and their risks to early adopters [21]. The unrelenting drive to produce GenAI en masse is fueled by sky-high VC investments [22, 23] partly streaming from a ‘pay-to-participate’ strategy to keep a horse in the big GenAI race. A strategy that is at times questionable, considering that the chance to join the GPU-rich is likely far-fetched at this point [24].
The second EDS-relevant characteristic of the GenAI ecosystem is the astonishing tempo of the general-purpose model/innovation of releases by the GPU-rich (proprietary or open-source). This creates significant potential to undermine or eliminate early GenAI adopters – their business strategies are potentially threatened each time we are exposed to a release that redefines the GenAI landscape and boundaries of what is possible. This disruptive tendency manifests every few months and shows no sign of slowing down, with the recent releases of Llama 2 [25] and Mistral [26] (the great hopes of open source NLP [27, 28]) and two proprietary game-changers seemingly just around the corner: Gemini [29] and GPT-5 [30]. As a result, the GPU-poor research and do business on ‘moving sands’. As a side-effect of any release by the GPU-rich, their research projects may likely be outdated before completion. Indeed, rapid and unpredictable innovations of the GPU-rich will repetitively wipe out niches targeted by countless GPU-poor early adapters, before any real chance of a return on investment.
It is not merely that “it’s totally hopeless to compete with us on training foundation models you shouldn’t try, and it’s your job to, like, try anyway” [31], as Sam Altman accurately summed up the situation of the GPU-poor vs GPU-rich. It’s also safe to assume that once the battle for supremacy for the ‘foundation models’ is more advanced, the same fate will befall utilities and applications of these models, where many of the GPU-poor hope to find a place for themselves. Think retrieval systems, agents, specialized finetunes, and other services built on and around the foundational models. Whenever serious consequences (in USD) are involved, the GPU-rich will (in time) provide these ‘auxiliary’ services out of the box.
Hence, the GPU-poor’s fear of this ‘side effect’ of business eradication is contributing to EDS by creating additional pressure to ship fast and skip evaluation, which is not perceived as a critical business goal.
Image 2. The astonishing tempo of changes in the business landscape contributes to Evaluation Derangement Syndrome in the GPU-poor. [source: The Missing Link in Generative AI | Fiddler AI Blog ].
Technical causes: Why does EDS plague GenAI?
Technically speaking, why exactly would EDS haunt GenAI applications? We figured out the Traditional ML evaluation quite well. Why would this know-how not translate easily to GenAI? In this section, we’ll delve into the ‘hard’/technical factors behind EDS in Generative AI.
Let’s start by refreshing the (very straightforward) conventional approach to ML development and evaluation. Let’s break it down into three steps:
- gather human-generated ground truths (GTs),
- gather model-generated outputs,
- compare them directly to produce meaningful metrics like accuracy, F1 score, and mean squared error.
There are several reasons why this approach breaks down for GenAI, regardless if it is related to the generation of text, images, or other content.
1. Inadequacy of the ‘ground truth’ concept in GenAI
Firstly, almost by definition, generative tasks often include a practically infinite variety of ‘optimal’ solutions, making any metrics which rely on direct comparisons with GT questionable. Within Natural Language Processing (NLP), ‘pseudo-evaluation’ approaches that we call ‘Superficial Utility Comparison Kriterion’ (SUCK) methods, like BLEU [32], METEOR [33], ROUGE [34], or BLEURT [35], attempt to salvage the situation. SUCK methods usually compare model outputs to GTs in specific embedding spaces, de facto under the assumption that output quality correlates with similarity to some GT within that space.
While this assumption might hold to some extent in quasi-generative tasks like summarization [link], it is fundamentally flawed. SUCK’s weaknesses are well recognized in the literature [link]. In our opinion, a fundamentally different approach is needed – we simply need to embrace the fact that ‘ground-truth’ is simply not a viable concept for most truly generative tasks. When the task is love poem generation, what is THE right answer that all others should imitate?
2. The innate subjectivity in GenAI evaluation
Secondly, assessing human-level creativity requires subjective and elusive criteria. Such evaluation is best expressed by poorly-defined concepts like aesthetics, novelty, style, creativity, helpfulness. Formal quality formulas have limited promise in this context. Furthermore, intersubjectivity is an inherent feature of evaluation, not a flaw to eliminate [36]. In many cases, generative models should optimize multiple objective quality indicators (e.g., the correctness of the generated code or retrieval ratio correctness etc.) and the subjective ones (e.g., code cleanliness, or proper conversational tone). All of them may non-trivially determine the final output quality, and more often than not conflict in practice [37, 38], and how to use them all in the practical evaluation is not necessarily obvious. Data collection, training, and evaluation procedures need to explicitly account for, quantify, and control subjectivity in the subdimensions of GenAI evaluation and their relation to the final quality of the output.
3. Extreme use-case specificity of the GenAI evaluation criteria
Thirdly, the interpretation of values relevant to the problem is highly application-specific and changes dramatically between use cases, and even users. Despite using identical terms, domains or use-cases dramatically redefine their interpretation. Context and goals determine standards of output beauty/aesthetics, proper tone, relevance, social acceptability or most other subjective metrics one can imagine. This makes capturing them with large, cross-domain, ‘once and for all’ datasets a challenge.
4. Diversity / mode collapse monitoring problems
The fourth reason is the susceptibility to mode collapse, where models produce outputs with limited diversity. While this can impact the utility of the model, it is also difficult to quantify and measure as part of model evaluation. Attempts to approximate the human sense of diversity, like FiD or the CLIP score, have serious limitations [39, 40]. On one hand, the definition of sample proximity may be non-trivial and domain-specific. On the other hand, diversity may be hard for humans to evaluate, as it is a feature of a large dataset – evaluation of multiple objects is a natural human weakness.
5. Potential evaluation dataset leaks in behind-closed-doors training
The fifth and final challenge in GenAI evaluation is the potential data leakage of any existing evaluation datasets one intends to utilize. Almost any model trained by the GPU-poor is a refinement of a general model (like Llama or Stable Diffusion) generously thrown open by the GPU-rich. These models have been trained on just about any data available, including all open datasets you wish to use to evaluate them or their fine-tuned iterations. The closed-door nature of many of these training procedures and their often undisclosed training datasets complicate the issue further. When we consider this in conjunction with the third challenge, which relates to the high degree of application specificity in given metrics, it becomes evident that depending on vast, openly accessible, one-size-fits-all datasets may no longer be a viable approach. It seems that the GPU-poor may have to rely on methodology allowing for easy evaluation with internally created, very small datasets capturing the case-specificity of their application.
Okay, so there are technical reasons why GenAI evaluation is hard, and why traditional ML approaches fail. But why would those technical obstacles hit the GPU-poor more? Why and how are the GPU-rich capable of dealing with them? Why can’t the GPU-poor copy what they do on a small scale? These are all great questions that we will address next.
How do the rich kids do it? The shiny new RLHF you (probably) can’t afford
Time for full disclosure: the problem above is only partially new. A lot of thought went into the proper approach to somewhat similar challenges long before the GenAI revolution. The field of Reinforcement Learning (RL) has much to say about the ‘healthy’ approach to a situation where the evaluation metric (‘reward’ in the RL lingo) is hard to formalize, complex, etc.
Successful RL conceptual frameworks like actor-critic [41] or world-model [42] have been used in physical or virtual environments to attack problems with ill-defined notions of ‘correct action’. The moment one sees GenAI as an agent, its outputs as actions, and human evaluation as a reward function, it all falls very nicely into the RL framework – hence Reinforcement Learning from Human Feedback (RLHF). One RL-borrowed component that allowed the GPU-rich to ‘put the harness’ on the GenAI they produced was the notion of a critic, preference, or reward model. Understanding this concept is vital to our conversation. The preference model is trained on human evaluations, to approximate human, well… preferences (Image 3, left). Once successfully trained, it can provide automated, pseudo-human feedback to train the generator (Image 3, right) concerning the human-level metrics (friendliness, political correctness, etc.). It is relevant to note that the reward model is a traditional (i.e., non-generative) model – it is not GenAI, so we know how to evaluate it directly. OpenAI used this approach to make ChatGPT by ensuring that GPT3/4 will not set off on racist rants, etc., by finetuning it to score highly on a reward model trained for OpenAI-preferred ideological biases. However, the same principle works for any GenAI (for example, reward models trained on human aesthetics [43] enable the creation of image generators like Midjourney [44]).
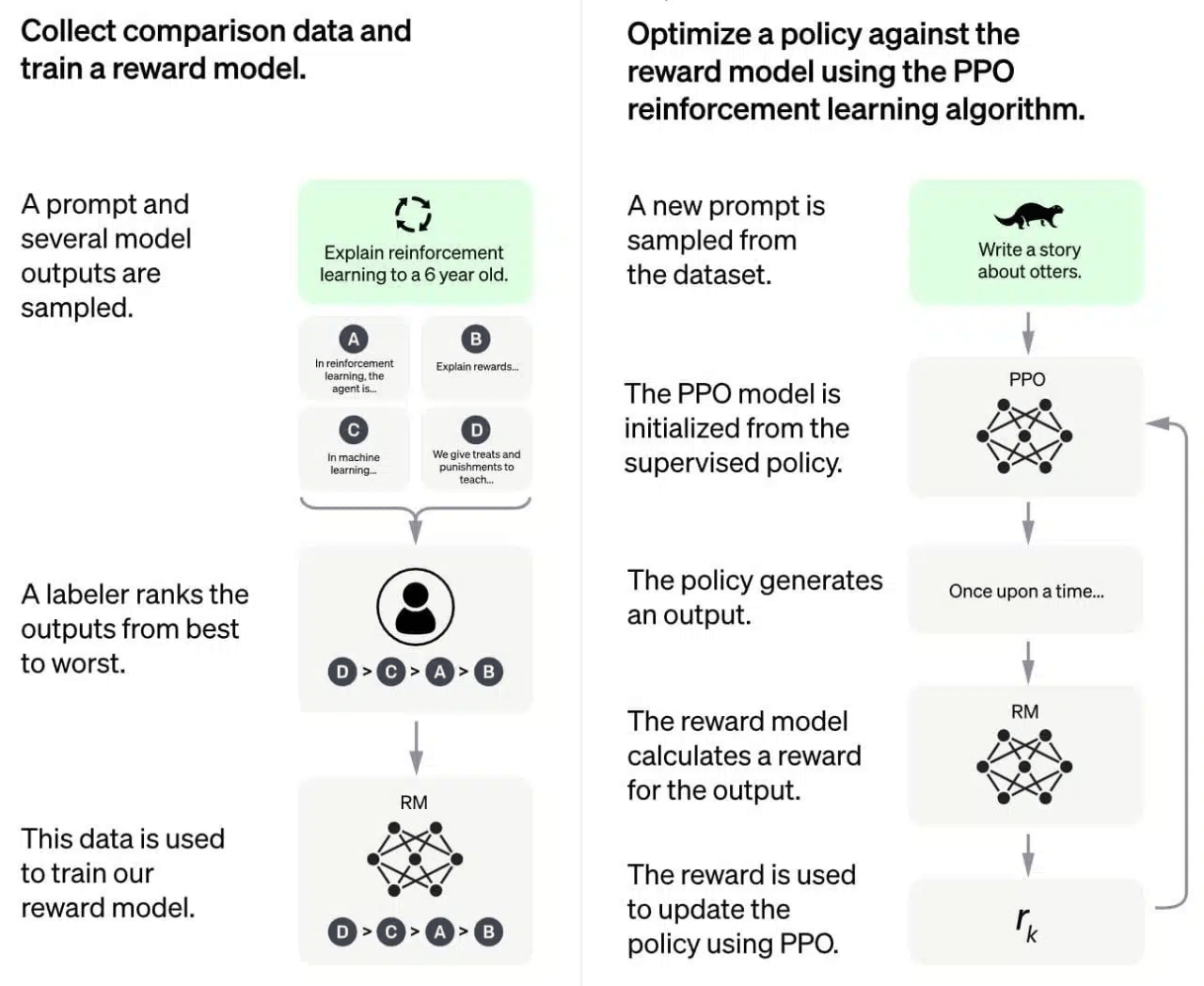
Image 3. OpenAI’s famous diagram. The reward model is trained on feedback to capture the human-level labeler’s preferences (left). The reward model is then used to automatically provide the training signal (providing human-like preferences) in millions of training steps of the actual generative model (right). [source: https://openai.com/blog/chatgpt]
At this point, many highly technical GPU-poor experts, who intuitively feel much of what we have described, just shrug and say, ‘that’s why we cannot afford proper GenAI evaluation’. One reason for this may be a misleading intuition about what is hard in (HF)RL. The thing is, the difficulty considered here is not just training any evaluation model, but rather a reward model strong enough to be used in full RLHF, i.e., the provider of a training signal directly from the generative model (right column). In this setup, the reward model becomes vulnerable, as the generative model may ‘beat’ it, exposing any weakness (hidden misalignments with human preferences) it may have. Dealing with this has much in common with adversarial training stability challenges in GANs [45] or general issues with ML adversarial safety [46]. It is hard. In essence, the reward model and the entire training methodology must be very strong to stop the generator from ‘hacking’ the preferences, or it will find a way to get a high reward in undesired ways (by generating weird or noise-like images/sentences that should not get high rewards, but do). This takes a vast amount of data, GPUs, and expert engineering.
Here comes the trivial observation behind the Evaluation Driven Development (EDD) that the GPU-poor can adapt. Evaluation models may be easier by orders of magnitude to obtain than reward models. Our experiments indicate that evaluation models may be very cheap and easy to create for the GPU-poor’s own use cases, when taken out of the RLHF context. Unlike the GPU-rich shaping their base models, you do not need your reward model to provide a training signal for the model you fine-tune (or prompt engineer). If you do it right, and the generator cannot fool the evaluator through the training signal, as few as 100-200 samples may be enough to create human-like evaluator models. And that is all you need to get out of the EDS!
Okay. So we have the general idea behind the EDD. But that’s not really a framework yet, is it? And what does ‘if you do it right’ mean exactly? That’s an entirely different story – one we will tell in the second blog post of this series.
References
- A survey of Generative AI Applications, Gozalo-Brizuela R., Garrido-Merchán E.C., 2023
- From ChatGPT to ThreatGPT: Impact of generative AI in cybersecurity and privacy, Gupta M., Akiri C., Aryal K. et al., 2023
- Art and the science of generative AI: A deeper dive, Epstein Z., Hertzmann A., Herman L. et al., 2023
- https://www.businessinsider.com/gpu-rich-vs-gpu-poor-tech-companies-in-each-group-2023-8?IR=T
- https://www.semianalysis.com/p/google-gemini-eats-the-world-gemini
- https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- BERTScore: Evaluating text generation with BERT, Zhang T., Kishore V., Wu F. et al., 2019.
- BLEU: A method for automatic evaluation of machine translation, Papineni K., Roukos S., Ward T. et al., 2002.
- https://github.com/features/copilot
- USR: An unsupervised and reference free evaluation metric for dialog generation, Mehri S., Eskanazi M., 2020
- Better automatic evaluation of open-domain dialogue systems with contextualized embeddings, Ghazarian S., Wei J. T.-Z., Galstyan A. et al., 2019
- An empirical study on evaluation metrics of generative adversarial networks, Xu Q., Huang G., Yuan Y. et al., 2018
- Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models, Stein G., Cresswell J.C., Hosseinzadeh R. et al., 2023
- Witscript 3: A hybrid AI system for improvising jokes in a conversation, Toplyn J., 2023
- MaxProb: Controllable story generation from storyline, Vychegzhanin S., Kotelnikova A., Sergeev A., Kotelnikov E., 2023
- Modern French poetry generation with RoBERTa and GPT-2, Hämäläinen M., Alnajjar K., Poibeau T., 2022
- SDXL: Improving latent diffusion models for high-resolution image synthesis, Podell D., English Z., Lacey K., 2023.
- https://www.gartner.com/en/articles/what-s-new-in-artificial-intelligence-from-the-2022-gartner-hype-cycle
- https://pitchbook.com/news/articles/generative-ai-hype-stability-jasper
- https://www.wsj.com/articles/no-business-plan-no-problem-chatgpt-spawns-an-investor-gold-rush-in-ai-6bdbed3c
- https://www.cfodive.com/news/many-ai-early-adopters-struggle-success/652138/
- https://mergers.whitecase.com/highlights/generative-ai-boom-sparks-investment-spree#!
- https://techcrunch.com/2023/03/28/generative-ai-venture-capital/
- https://sifted.eu/articles/keelvar-ai-go-to-market
- https://ai.meta.com/llama/
- https://mistral.ai/news/announcing-mistral-7b/
- https://zapier.com/blog/llama-meta/
- https://www.digitaltrends.com/computing/why-meta-llama-2-is-such-a-big-deal/
- https://www.techopedia.com/definition/google-gemini
- https://medium.com/@trendingAI/gpt-5-revealed-release-date-what-we-know-so-far-ff7ec532d40e
- https://www.zenger.news/2023/06/10/sam-altman-says-its-hopeless-to-compete-with-openai/
- BLEU: A method for automatic evaluation of machine translation, Papineni K., Roukos S., Ward T. et al., 2002
- METEOR: An automatic metric for MT evaluation with improved correlation with human judgments, Banerjee S., Lavie A., 2005
- ROUGE: A package for automatic evaluation of summaries, Lin C.-Y., 2004
- BLEURT: Learning robust metrics for text generation, Sellam T., Das D., Parikh A.P., 2020
- Understanding interobserver agreement: The kappa statistic, Viera A.J., Garrett J.M., 2005
- Improved precision and recall metric for assessing generative models, Kynkäänniemi T., Karras T., Laine S., 2019
- Evaluating creative language generation: The case of rap lyric ghostwriting, Potash P., Romanov A., Rumshisky A., 2018
- Toward verifiable and reproducible human evaluation for text-to-image generation, Otani M., Togashi R., Sawai Y. et al., 2023
- Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models, Stein G., Cresswell J.C., Hosseinzadeh R. et al., 2023
- https://medium.com/intro-to-artificial-intelligence/the-actor-critic-reinforcement-learning-algorithm-c8095a655c14
- Deep learning, reinforcement learning, and world models, Matsuo Y., LeCun Y., Sahani M., 2022
- https://laion.ai/blog/laion-aesthetics/
- https://www.midjourney.com/showcase/recent/
- https://jonathan-hui.medium.com/gan-why-it-is-so-hard-to-train-generative-advisory-networks-819a86b3750b
- Key concepts in AI safety: Robustness and adversarial examples, Rudner T.G.J., Toner H., 2021
