

GeoJson Operations in Apache Spark with Seahorse SDK
A few days ago we released Seahorse 1.4, an enhanced version of our machine learning, Big Data manipulation and data visualization product.
This release also comes with an SDK – a Scala toolkit for creating new custom operations to be used in Seahorse.
As a showcase, we will create a custom Geospatial operation with GeoJson and make a simple Seahorse workflow using it. This use-case is inspired by Example 8 from book Advanced Analytics with Spark.
Geospatial data in GeoJson format
GeoJson can encode many geographic data types. For example:
- Location Point
- Line
- Region described by a polygon
GeoJson encodes Geospatial data using Json.
{
"type": "Point",
"coordinates": [125.6, 10.1]
}
New York City Taxi Trips
In our workflow we will use a New York Taxi Trip dataset with pickup and drop-off location points.
Let’s say that we want to know how many Taxi Trips started on Manhattan and ended up in Bronx. To achieve this, we could use an operation filtering dataset by location contained inside some geographic region. Let’s call this operation ‘Filter inside Polygon’.

Manhattan GeoJson Polygon visualization using geojson.io
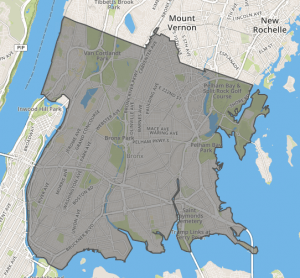
Bronx GeoJson Polygon visualization using geojson.io
You can download GeoJson data with New York boroughs from https://github.com/dwillis/nyc-maps.
Implementing custom operation using Seahorse SDK steps:
- Clone Seahorse SDK Example Git Repository.
- Implement custom Geospatial operation.
- Assembly jar with custom Geospatial operation.
- Add assembled jar to Seahorse instance.
- Use custom Geospatial operation in a Workflow.
Seahorse SDK Example Git Repository
The fastest way to start developing a custom Seahorse operations is by cloning our SDK Example Git Repository and write your code from there.
git clone --branch 1.4.0 https://github.com/deepsense-io/seahorse-sdk-example
The Seahorse SDK Example Repository has all Seahorse and Apache Spark dependencies already defined in an SBT build file definition.
Let’s add the geospatial data library to our dependencies in the build.sbt file:
libraryDependencies += "com.esri.geometry" % "esri-geometry-api" % "1.0"
Now we can implement the FilterInsidePolygon operation:
@Register // 1
final class FilterInsidePolygon
extends DOperation1To1[DataFrame, DataFrame] { // 2
override val id: Id = "48fa3638-bc8d-4430-909f-85d4ece824a3" // 3
override val name: String = "Filter Location Inside Polygon"
override val description: String = "Filter out rows " +
"for which location is contained within a specified GeoJson polygon"
lazy val geoJsonPointColumnSelector = SingleColumnSelectorParam(
name = "GeoJson Point - Column Name",
description = Some("Column name containing " +
"location written as Point object in GeoJson"),
portIndex = 0
)
lazy val geoJsonPolygon = StringParam( // 5
name = "GeoJson Polygon",
description = Some("Polygon written in GeoJson format used for filtering out the rows")
)
override def params = Array(geoJsonPointColumnSelector, geoJsonPolygon)
- We need to annotate the operation with @Register so that Seahorse knows that it should be registered in the operation catalogue.
- We extend DOperation1To1[DataFrame, DataFrame] because our operation takes one DataFrame as an input and returns one DataFrame as the output.
- UUID is used to uniquely identify this operation.
After making changes in operation (e.g. name is changed), idshould not be changed – it is used by Seahorse to recognize that it’s the same operation as before. - Parameter geoJsonPointColumnSelector will be used for selecting a column with Point Location data.
Parameter geoJsonPolygon represents a Polygon we will be checking location points against.
Now we can implement an execute method with actual GeoSpatial and Apache Spark dataframe code.
override protected def execute(input: DataFrame)(context: ExecutionContext): DataFrame = {
// 1 - Parse polygon
val polygon = GeometryEngine.geometryFromGeoJson(
$(geoJsonPolygon),
GeoJsonImportFlags.geoJsonImportDefaults,
Geometry.Type.Polygon
)
val columnName = DataFrameColumnsGetter.getColumnName(
input.schema.get,
$(geoJsonPointColumnSelector)
)
val filtered = input.sparkDataFrame.filter(row => {
try {
val pointGeoJson = row.getAs[String](columnName)
// 2 - Parse location point
val point = GeometryEngine.geometryFromGeoJson(
pointGeoJson,
GeoJsonImportFlags.geoJsonImportDefaults,
Geometry.Type.Point
)
// EPSG:4326 Spatial Reference
val standardCoordinateFrameForEarth = SpatialReference.create(4326)
// 3 - Test if polygon contains point
GeometryEngine.contains(
polygon.getGeometry,
point.getGeometry,
standardCoordinateFrameForEarth
)
} catch {
case _ => false // ignore invalid rows for now
}
})
DataFrame.fromSparkDataFrame(filtered)
}
- We parse our polygon data using GeometryEngine class from esri-geometry-api library.
- Inside the Apache Spark dataFrame filter we use GeometryEngine class again to parse location points in each row.
- We use GeometryEngine class to test whether the point is contained inside the specified polygon.
Now that the implementation is finished, you can build a JAR and add it to Seahorse:
- Run sbt assembly. This produces a JAR in the target/scala-2.11 directory.
- Put this JAR in $SEAHORSE/jars, where $SEAHORSE is the directory with docker-compose.yml or Vagrantfile (depending whether you run Docker or Vagrant).
- Restart Seahorse (By either `stop`ing and `start`ing `docker-compose` or `halt`ing and `up`ing `vagrant`).
- Operations are now visible and ready to use in Seahorse Workflow Editor.
And now that we have Filter Inside Polygon, we can start implementing our workflow:
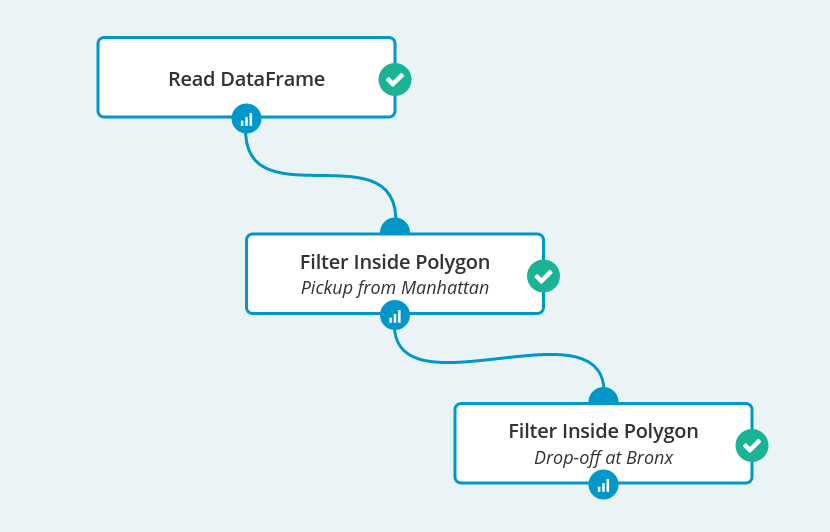
First we need to specify our datasource. You can download the whole 26GB dataset from http://www.andresmh.com/nyctaxitrips.
Since we are using a Local Apache Spark Master we sample 100k rows from the whole dataset.
Additionally we also transformed the latitude and longitude column into one GeoJson column for both pickup and drop-off locations.
You can download the final preprocessed dataset used for this experiment from here.
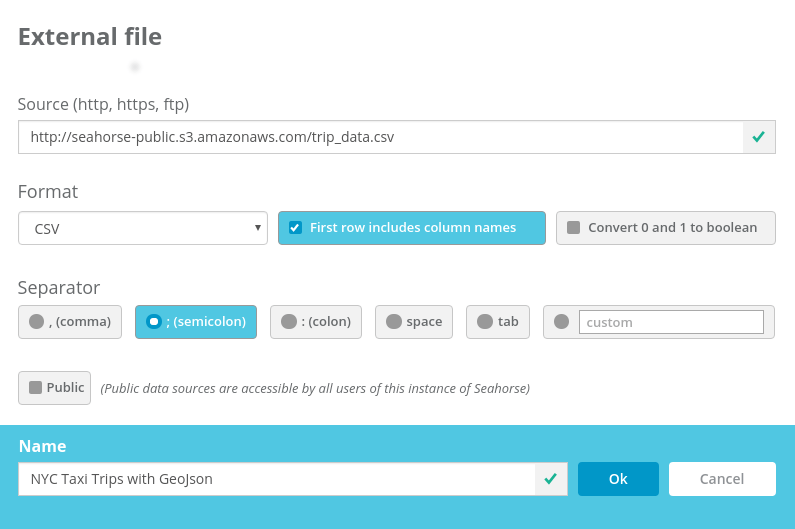
Building our Workflow
Let’s start by defining our Datasource in Seahorse:
Next, we use NYC borough GeoJson polygon values from https://github.com/dwillis/nyc-maps as attributes in our Filter Inside Polygon operations:
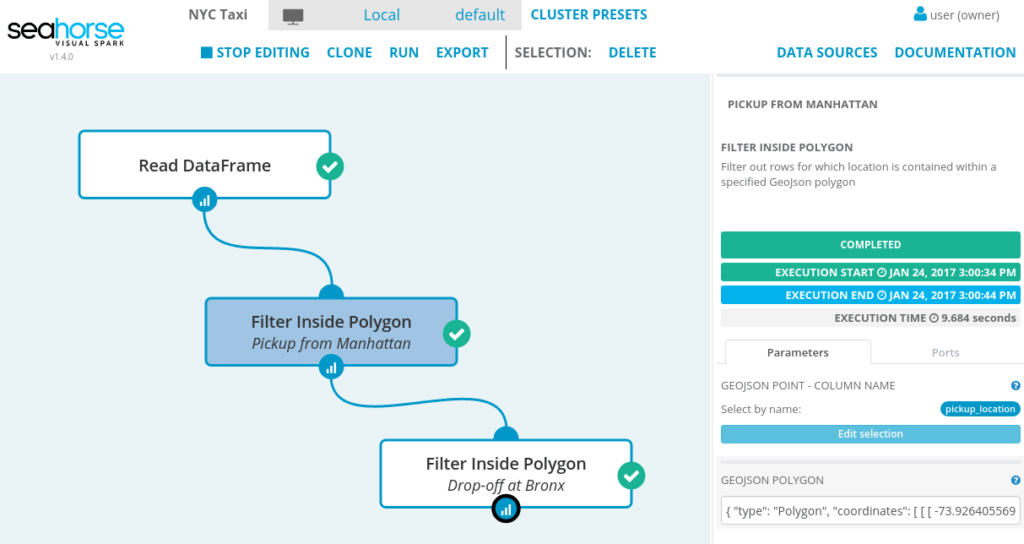
Finally, let’s run our workflow and see how many Taxi trips started on Manhattan and ended in Bronx:
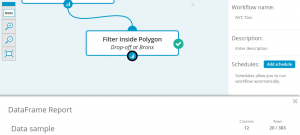
As we can see from our 100k data sample, only 383 trips started on Manhattan and ended in Bronx.
Summary
We cloned the Seahorse SDK Example repository and starting from it we implemented a custom Filter Inside Polygon operation using Scala. Then we built a JAR file with our operation and we added it to Seahorse. After that we built our Workflow and used custom Filter Inside Polygon operation working in Apache Spark dataframes with GeoJson data.
Links
- Check Filter Inside Polygon source code in our Seahorse SDK Example repository.
- Download Workflow which can be imported in Seahorse.
