
Table of contents
ChatGPT is a cutting-edge natural language processing model released in November 2022 by OpenAI. It is a variant of the GPT-3 model, specifically designed for chatbot and conversational AI applications. On the rising tide of ChatGPT, there are plenty of amazing examples of the chatbot’s accomplishments, one of which is presented in Figure 1.
Table of contents
Introduction of GPT models
Let’s start with a short introduction of what GPT models are (what the GPT model family is). This acronym is used when referring to a series (GPT, GPT-2 and GPT-3, with the next generations expected soon). It has been trained to process and generate human-like language, and it has achieved impressive results in various language tasks such as translation, summarization, and question answering. GPT has been trained on a massive dataset of text, and it uses this training data to learn patterns and relationships in language. This allows it to understand and generate language in a way that is similar to how humans do. GPT is a powerful tool for developers looking to create articles, poetry, stories, news, reports and dialogue. It can be fine-tuned for specific tasks or domains, allowing it to become even more effective at handling specific types of language tasks.
What makes ChatGPT different from classic GPT models is its incorporation of human feedback during training using reinforcement learning. In this post we will dive into the details of RLHF (Reinforcement Learning from Human Feedback) and how we can use it to fine-tune language models. It is worth noting that the idea was previously used by the OpenAI team in InstructGPT – a sibling model which was trained to follow an instruction in a prompt and provide a detailed response.
What is reinforcement learning?
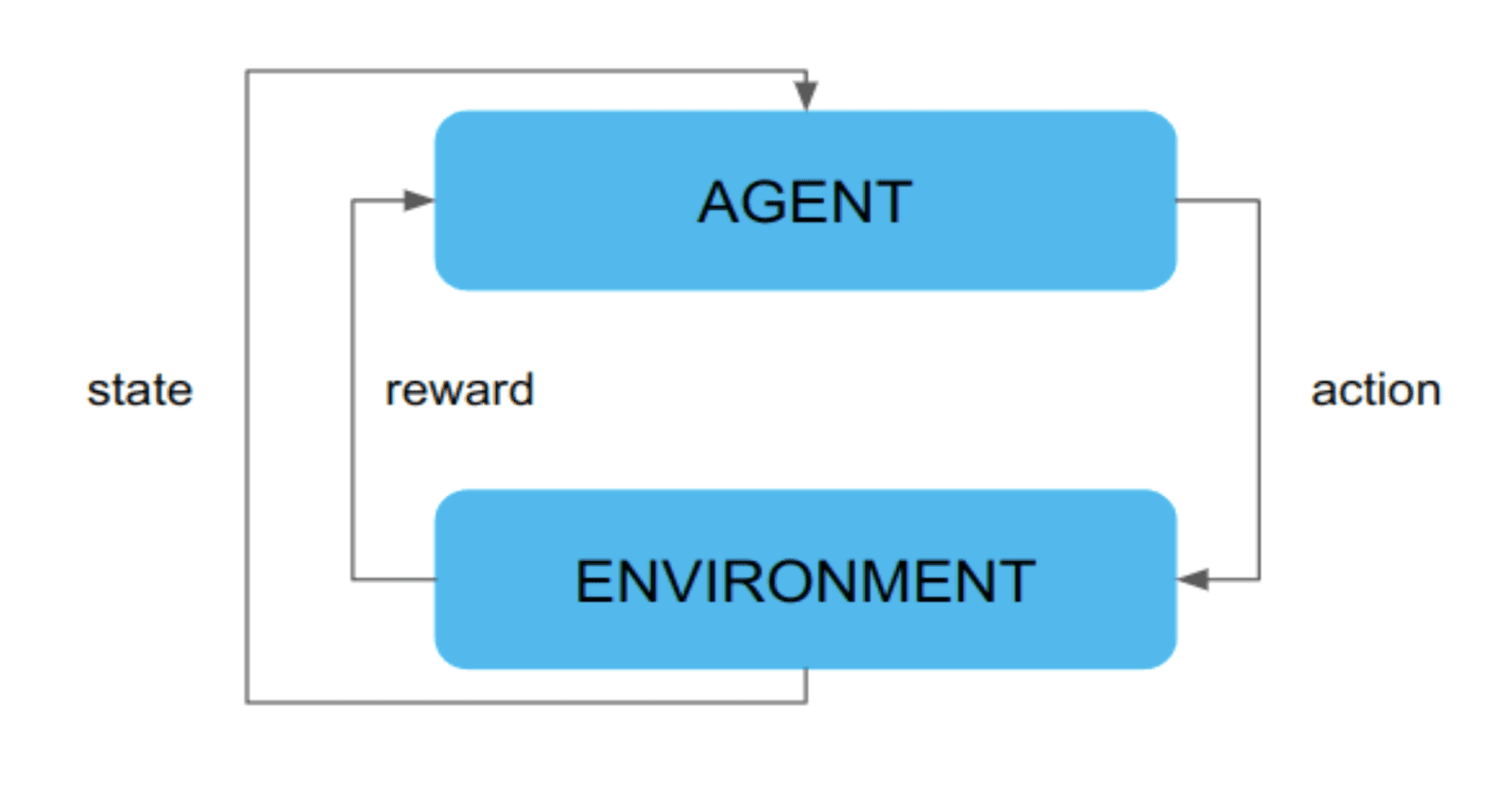
Reinforcement learning is a machine learning area which aims to train models to make a sequence of decisions. The agent learns by interacting with the (usually complex) environment. Each action is chained with a reward (or penalty). The aim of the model is to learn which actions will maximize the total reward.
The typical reinforcement learning setup consists of a tuple of five elements:
- States Space (
) – a set of possible states that an agent can visit.
- Action Space (
) – a set of possible actions that an agent may take.
- State Transition Probability (
) – describes the dynamics of the environment. It is also called the world model. For model-free reinforcement learning, it is not necessary to know the state transition probability.
- Reward Function (
) – a reward (penalty) that an agent receives for a selected action made in a specific state.
- Discount Factor (
) – defines the present value of future rewards.
A reinforcement learning agent learns policy (
RL has a wide range of applications, including control systems and robotics. It is particularly useful for tasks that involve sequential decision-making or learning from experience, such as playing Go or Atari games.
Reinforcement learning from human feedback (RLHF)
The history of incorporating human feedback into reinforcement learning is very long. There have been plenty of ideas on how we can integrate human-based samples into the agent training process, for example by adjusting the algorithm itself or with reward shaping. We would like to focus a little bit more on the approach presented in “Deep Reinforcement Learning from Human Preferences” published by DeepMind in 2017.
A typical reinforcement learning training loop involves an agent who interacts with the environment and changes states. Each interaction is connected to a reward. The whole process is presented in Figure 2. The reward function has a huge impact on agent performance. If poorly designed, it results in poor agent performance as well. In the paper, the authors propose to learn the reward function from human feedback, while the agent is still training the same way as in the classical reinforcement learning task.
The best way to train the agents is by going through the example provided by the authors in the video.

The task was to teach the agent how to do a backflip. Two trajectories delivered by current policy were shown to a human, who decided which one did the better backflip (or at least made a better attempt at doing a backflip). Based on preference, the reward estimator is updated to grant the favored agent behavior with a higher reward. Then the agent is trained in the classical manner of reinforcement learning. Our training loop was enriched with one additional step. The new loop is presented in Figure 4.
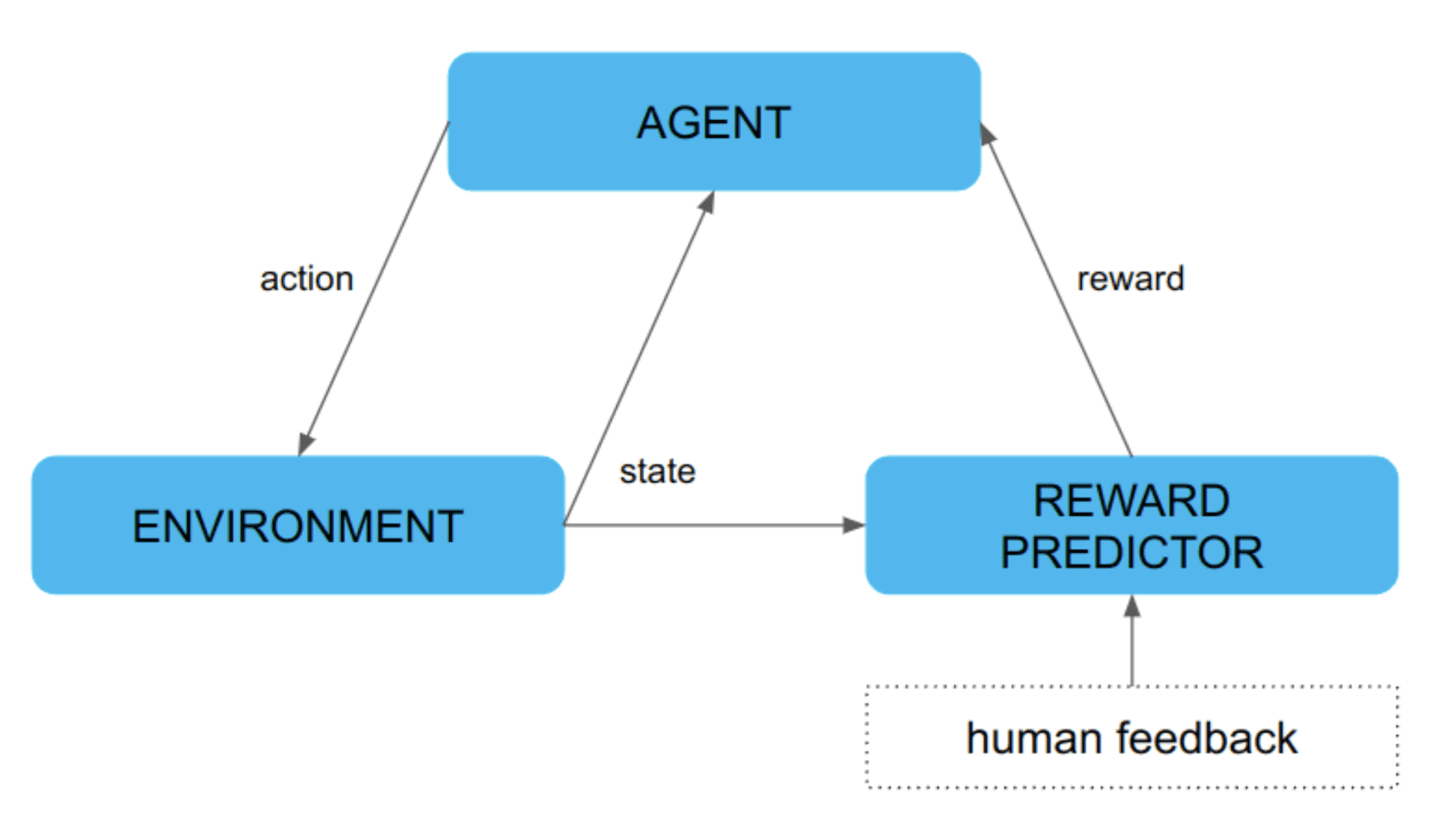
To sum up, the new process consists of three steps:
- Generating a set of trajectories
, with learned policy. The parameters of the policy are learned via traditional reinforcement learning to maximize total reward. Policy can be learned using any suitable reinforcement learning algorithm.
- Selecting two segments
from the generated trajectories and letting the human compare them and rank which one did better. Human judgments are stored as a tuple
, where
is the distribution of which segment was preferred.
- Train the reward predictor using supervised learning techniques. To estimate the reward predictor, we should find a way to express the preferred strategy, which can be achieved via the Bradley-Terry model. The simplest example of how this model works is a situation in which we would like to rank football teams in a competition. As the number of matches played might not be even for all teams, we can introduce a model that compares the “strength” of teams to achieve the probability of one team beating another. We can introduce the same thing for trajectories:
![{\widehat{P}[\sigma^{1}\succ\sigma^{2}]=\frac{\exp(\Sigma\widehat{r}(\sigma^{1}_{t},a^{1}_{t}))}{\exp(\Sigma\widehat{r}(\sigma^{1}_{t},a^{1}_{t}))+\exp(\Sigma\widehat{r}(\sigma^{2}_{t},a^{2}_{t}))}}](https://s0.wp.com/latex.php?latex=%7B%5Cwidehat%7BP%7D%5B%5Csigma%5E%7B1%7D%5Csucc%5Csigma%5E%7B2%7D%5D%3D%5Cfrac%7B%5Cexp%28%5CSigma%5Cwidehat%7Br%7D%28%5Csigma%5E%7B1%7D_%7Bt%7D%2Ca%5E%7B1%7D_%7Bt%7D%29%29%7D%7B%5Cexp%28%5CSigma%5Cwidehat%7Br%7D%28%5Csigma%5E%7B1%7D_%7Bt%7D%2Ca%5E%7B1%7D_%7Bt%7D%29%29%2B%5Cexp%28%5CSigma%5Cwidehat%7Br%7D%28%5Csigma%5E%7B2%7D_%7Bt%7D%2Ca%5E%7B2%7D_%7Bt%7D%29%29%7D%7D&bg=f7f7f7&fg=000&s=3&c=20201002)
Therefore we can write the loss function as:
![{loss(\widehat{r})=\Sigma_{(\sigma^{1},\sigma^{2},\mu)}\mu(1)\widehat{P}[\sigma^{1}\succ\sigma^2]+\mu(2)\widehat{P}[\sigma^{2}\succ\sigma^1]}](https://s0.wp.com/latex.php?latex=%7Bloss%28%5Cwidehat%7Br%7D%29%3D%5CSigma_%7B%28%5Csigma%5E%7B1%7D%2C%5Csigma%5E%7B2%7D%2C%5Cmu%29%7D%5Cmu%281%29%5Cwidehat%7BP%7D%5B%5Csigma%5E%7B1%7D%5Csucc%5Csigma%5E2%5D%2B%5Cmu%282%29%5Cwidehat%7BP%7D%5B%5Csigma%5E%7B2%7D%5Csucc%5Csigma%5E1%5D%7D&bg=f7f7f7&fg=000&s=3&c=20201002)
Now, as we are equipped with reinforcement learning from human feedback knowledge, we can take a deep dive into the ChatGPT example.
ChatGPT/Instruct GPT cases
ChatGPT and InstructGPT use reinforcement learning from human feedback in the model fine-tuning phase. We can split it into the three stages presented in Figure 5.
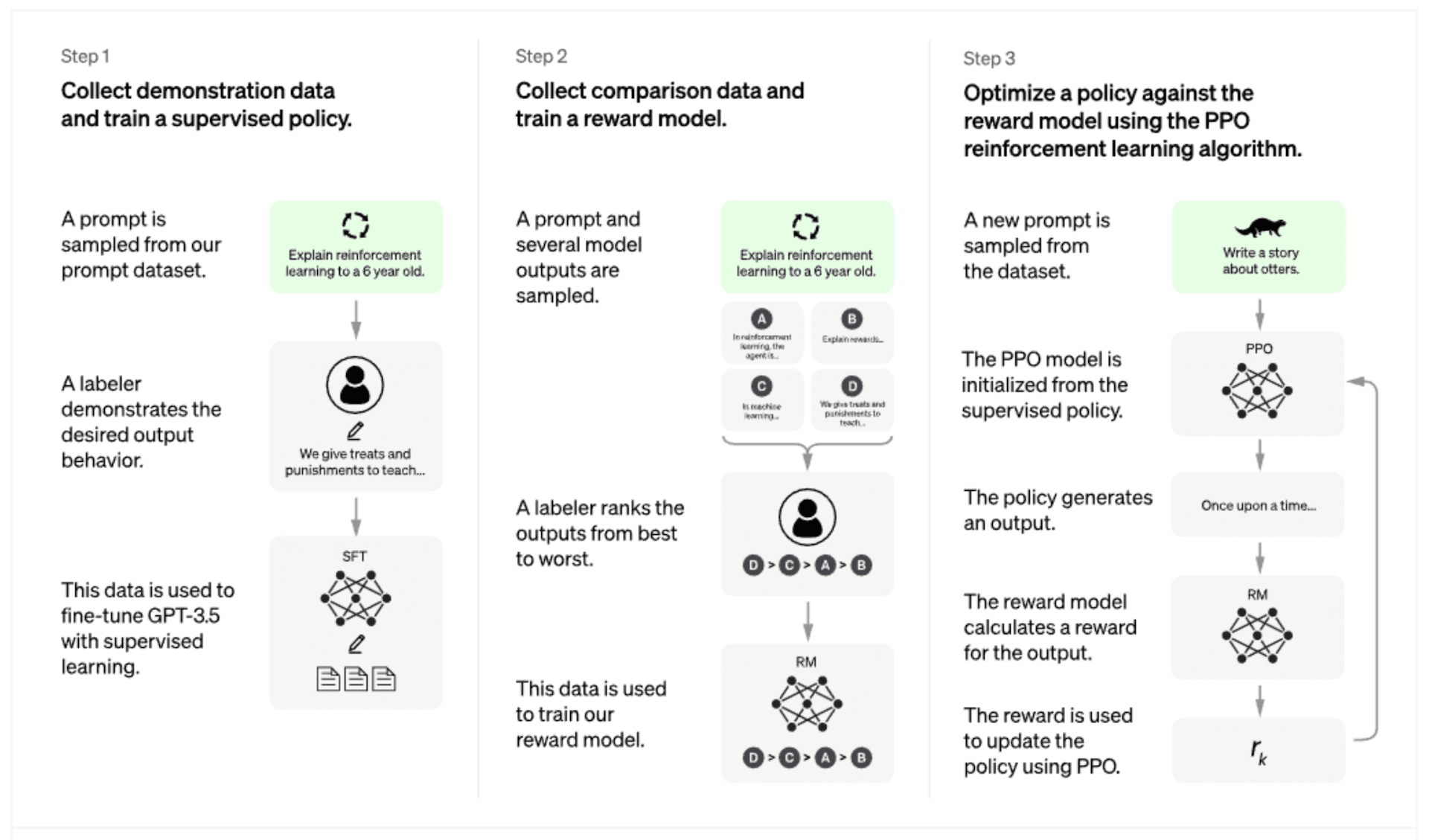
Step 1
The first step involves fine-tuning GPT-3.5 using data delivered by humans playing the role of assistant and user. The trainers had access to model-written suggestions to help with composing responses. These dialogues were mixed with the InstructGPT dataset, which contains prompts and instructions written by users of earlier versions of InstructGPT submitted through Playground. Regarding InstructGPT, the data collection step is limited to obtaining and using the InstructGPT dataset and fine-tuning the GPT-3 model. This step is summarized in Figure 6.
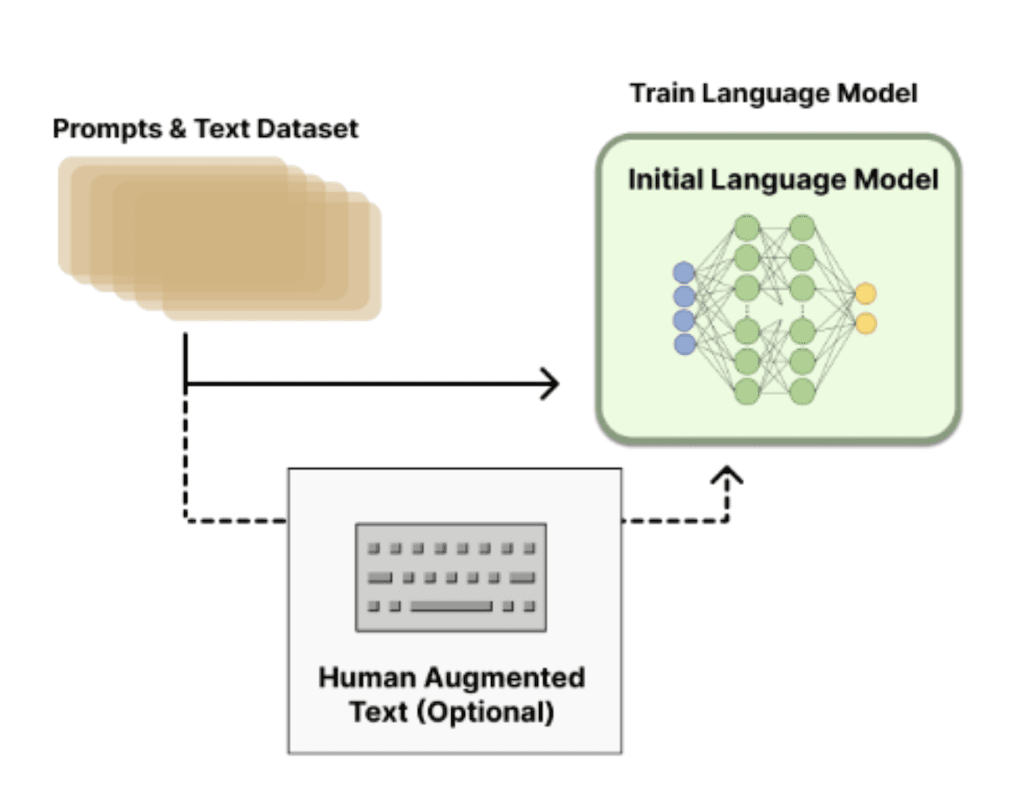
The next steps remain the same for both ChatGPT and InstructGPT.
Step 2
The second step is focused on the training reward model. The language model from the first step is used to prepare samples of responses that are compared and ranked by humans to express their preferences. According to the InstructGPT paper, a labeler receives between 4 and 9 responses to rank. It means, that there is 
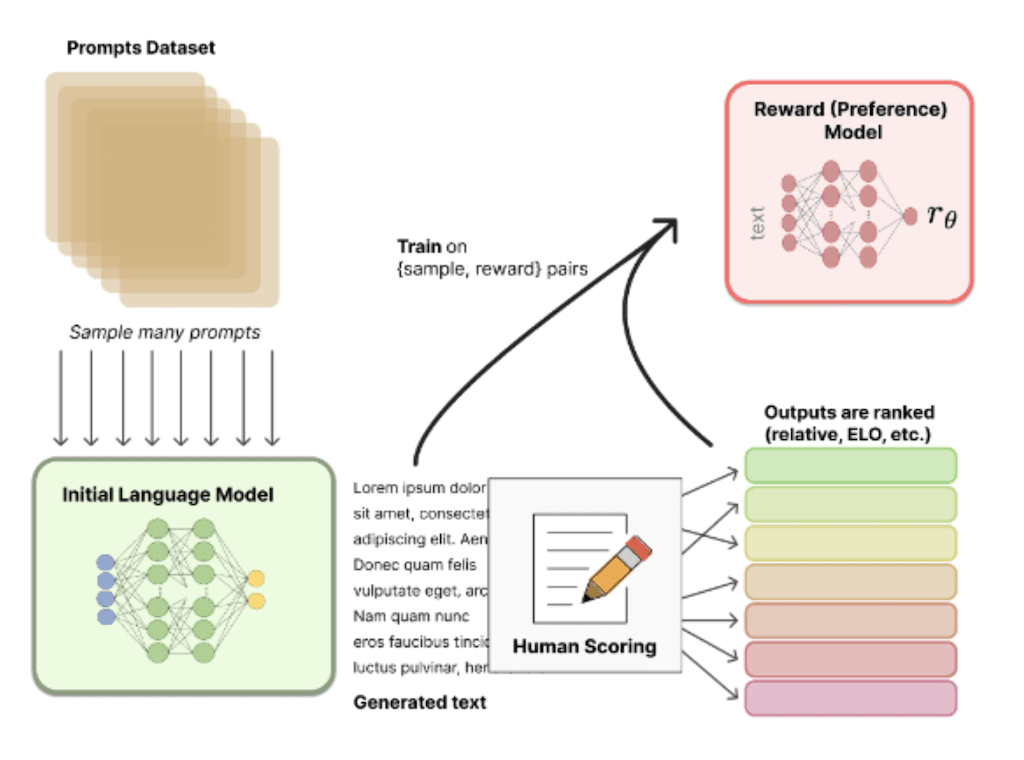
Step 3
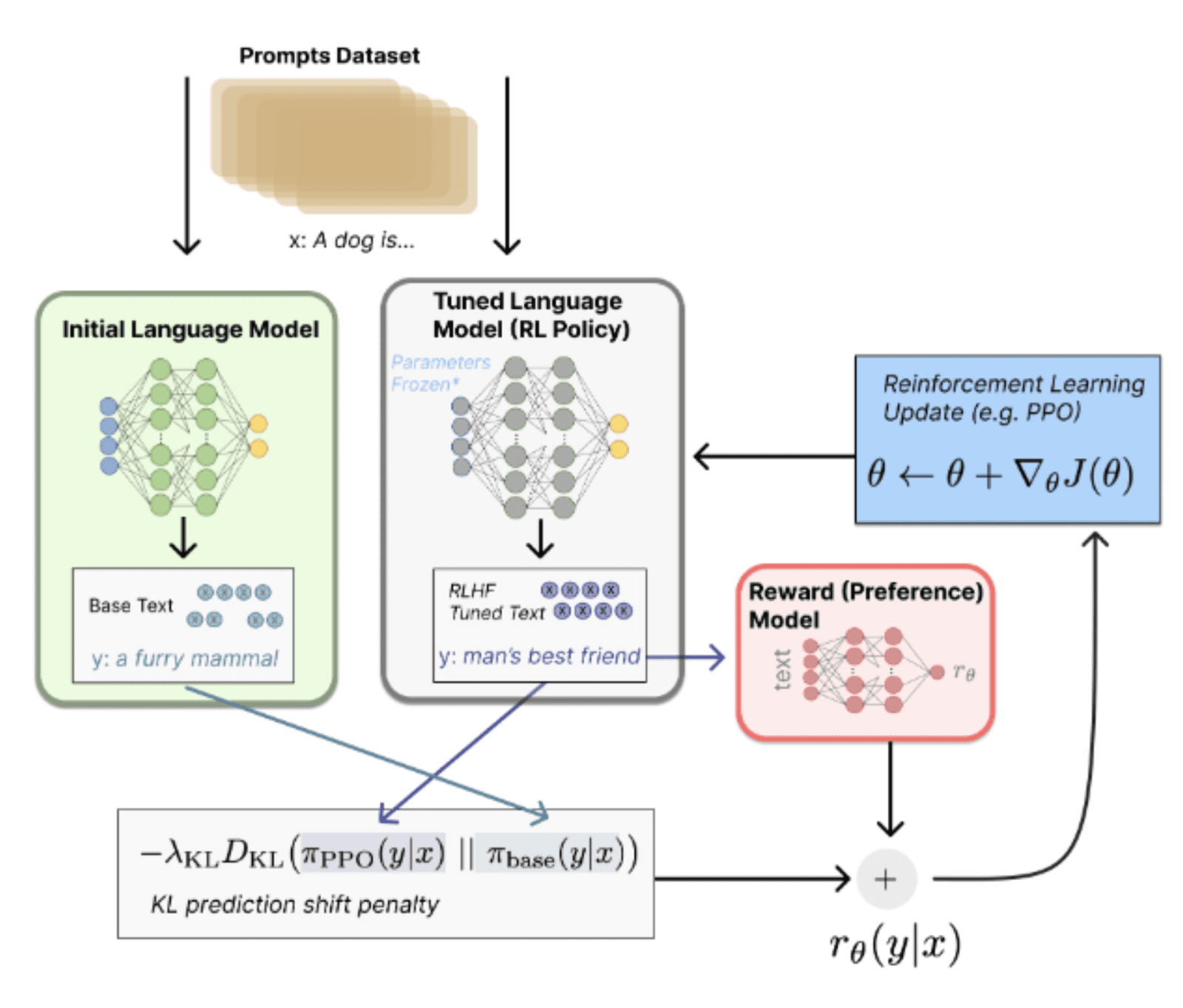
The last step utilizes the prepared elements in one reinforcement learning task to fine-tune the language model. Let’s formulate the task to fit reinforcement learning language:
- The agent is represented by a language model.
- State space is the possible input token sequences.
- The action space is all the tokens corresponding to the vocabulary of the language model.
- The reward from the environment is delivered by the reward predictor trained in step 2.
The algorithm used in ChatGPT is PPO, which is short for Proximal Policy Optimization – a state-of-the-art technique in the Reinforcement Learning area. Kullbach-Leibler divergence is added to PPO loss between the initial model and current policy distributions to prevent one from moving substantially away from the initial model.
Using RLHF with Large Language Models: final thoughts
Using human feedback as the reward signal has several advantages. It allows the model to learn from real-world human preferences and expectations, making it more likely to generate responses that are natural and human-like. It also allows the model to learn more quickly and efficiently, since it can use the feedback it receives to fine-tune its output and avoid making the same mistakes in the future.
However, there are also some limitations to this approach. The feedback may be subjective and prone to bias, which could affect the model’s learning process. Additionally, it can be time-consuming and resource-intensive to collect and process large amounts of human feedback, especially if the model is generating a large number of responses.
Ready to implement Generative AI into your digital solution? Choose our GPT and LLMs workshops and learn everything you need to prepare for the future-oriented revolution!
Bibliography
- “Deep reinforcement learning from human preferences” Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei, https://arxiv.org/abs/1706.03741
- https://openai.com/blog/chatgpt/
- https://openai.com/blog/instruction-following/
- https://huggingface.co/blog/rlhf
- https://openai.com/research/learning-from-human-preferences
- https://wandb.ai/ayush-thakur/RLHF/reports/Understanding-Reinforcement-Learning-from-Human-Feedback-RLHF-Part-1–VmlldzoyODk5MTIx





