Custom Datasets for LLM/VLM Evaluation and Training
Evaluate and improve LLM/VLM readiness for real-world deployment with custom, unleaked datasets and bespoke evaluation frameworks that reveal true model capabilities, failure modes, and paths to measurable improvement.
Our Benchmark & Dataset Portfolio
We currently focus on LLM/VLM capabilities in data-driven reasoning. We cover two important areas of expertise in which ML models must excel to be considered reliable assistants in real-world business cases.
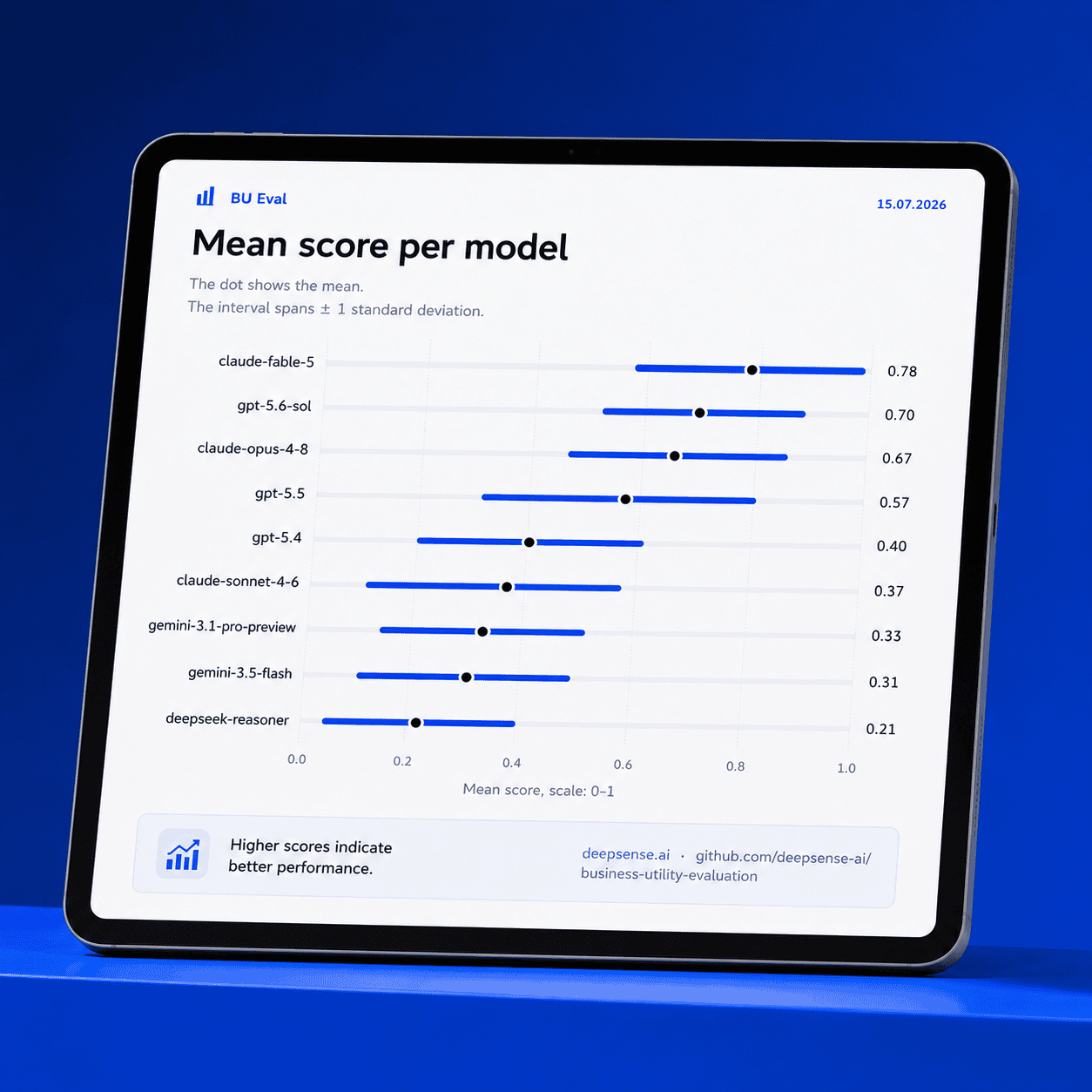
Business Utility Evaluation
(BU Eval)
A business case agent-based simulation benchmark for testing whether LLMs are ready for deployment in real analytical workflows.
BU Eval goes beyond isolated EDA tasks. It consists of agent-based business simulations in which an LLM/VLM must operate in a realistic, analytical setting and demonstrate its ability to deliver business-relevant value.
More about the benchmark
Instead of measuring only task completion or answer correctness, BU Eval introduces a dedicated Business Utility metric. This evaluates whether the model’s output is not just technically plausible, but actually useful from a business perspective.
Learn more about it here.
Availability: Custom datasets are available for fast, high-quality delivery.
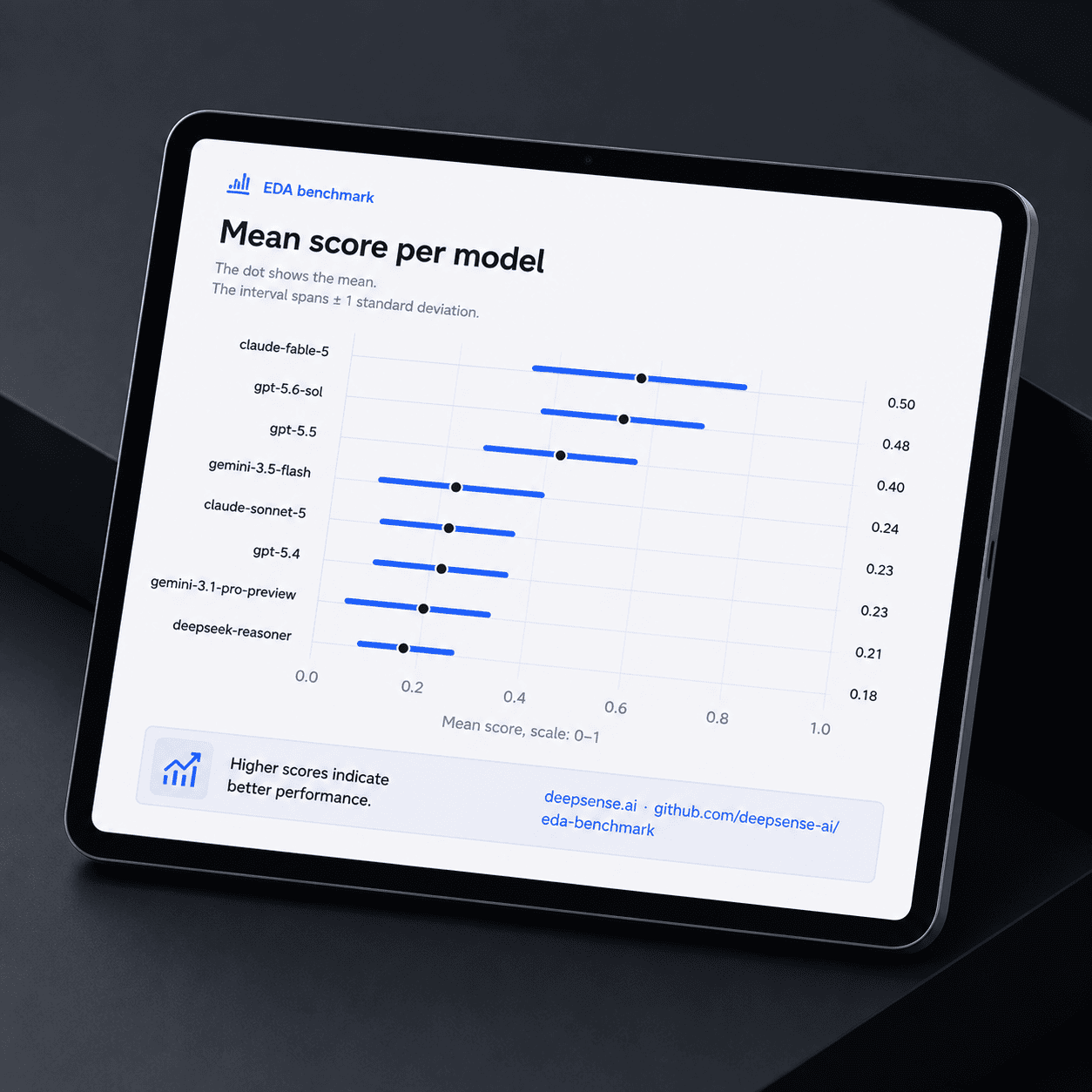
Exploratory Data Analysis Benchmark (EDA Bench)
A broad benchmark for evaluating LLM performance in Exploratory Data Analysis.
EDA Bench is a benchmark built around diverse EDA problems across multiple domains, data formats, and analytical skill categories. It evaluates whether LLMs can inspect data, identify relevant patterns, formulate hypotheses, and produce useful analytical conclusions.
Availability: Custom datasets are available for fast, high-quality delivery.

Evaluation Results & Model Insights
We publish selected results, model comparisons, and evaluation notes. We use our public datasets to evaluate current SOTA LLM/VLMs` deployment readiness.



How we work
We constantly improve our evaluation frameworks and datasets to match the requirements of SOTA ML models. All datasets we deliver are fully synthetic, unleaked, and in most cases, augmented with bespoke evaluation frameworks. While simulation-based benchmarks require a dedicated harness for ML models, we have experience ensuring frictionless integration across the client organization’s various environments.
Built Close to the Frontier of AI
We build on 12 years of experience in applied AI development. As official partners of leading AI platforms, including OpenAI and Anthropic, we work close to the frontier of model development and deployment. This gives us practical insight into where advanced models are improving, where they still fail, and what kinds of evaluation data are needed to make them more reliable, useful, and production-ready.


Evaluate and Improve Your Model Capabilities
Our public benchmark tasks show the methodology. The real value comes from building larger, private datasets tailored to your model family, target capabilities, and goals. We create two types of custom datasets:
- harder task sets for reliable model evaluation
- larger task sets for model training.
Evaluation datasets help expose failure modes, measure progress, and create a competitive advantage. Training datasets provide high-volume, structured examples that help improve analytical reasoning and domain-specific problem-solving.