
Table of contents
We’ve all seen the incredible things LLMs can do, and they are increasingly being pushed into roles where they act as autonomous data analysis agents. But are they actually ready to take over your company’s exploratory data analysis?
In our latest research at deepsense.ai evaluating LLMs in realistic supply chain scenarios, we found the answer is “not quite.” To explain exactly why, our team has introduced a new, risk-adjusted evaluation metric called Business Utility.
The Problem with “Average” AI
When evaluating AI models, the industry typically looks at their mean score, which captures average analytical correctness. But average performance can hide the issue that matters most in business: consistency.
Below you can find some mode-variant performance profiles by experiment. Each panel labels all model variants directly, and colors are consistent across panels to support cross-experiment tracking.
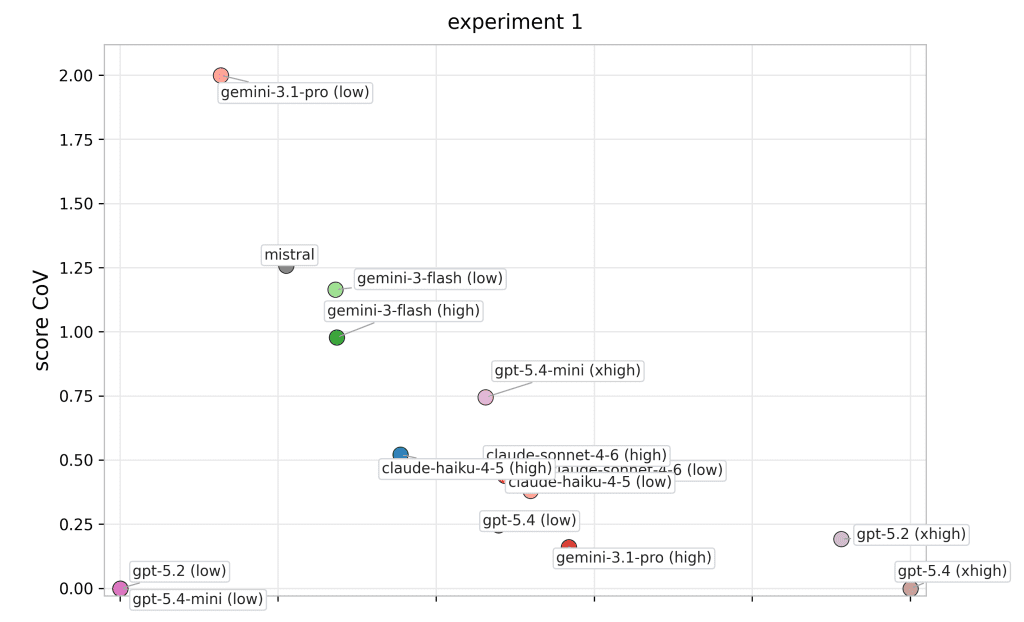
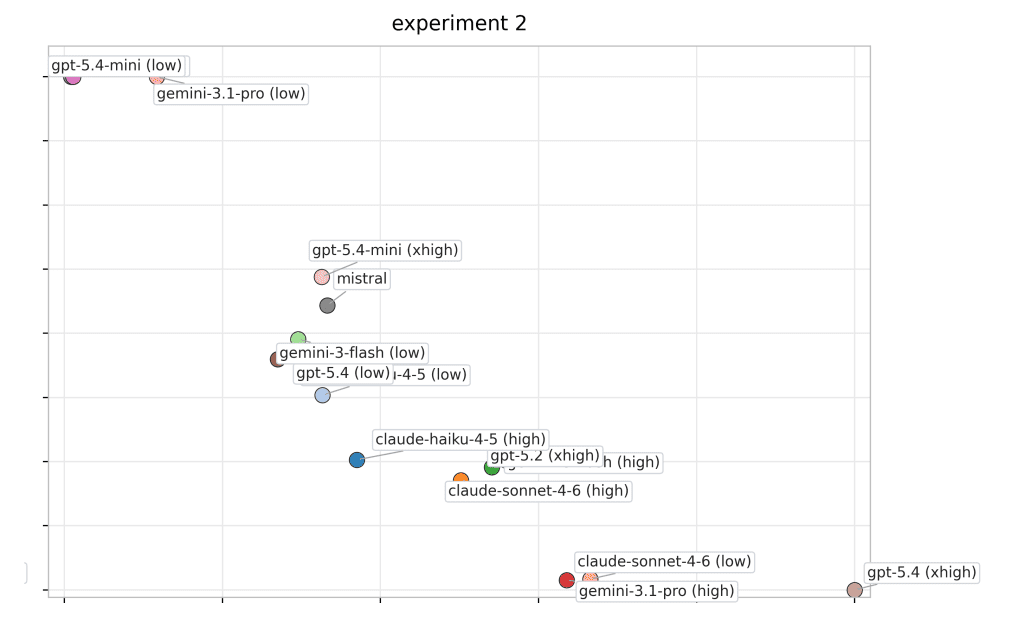
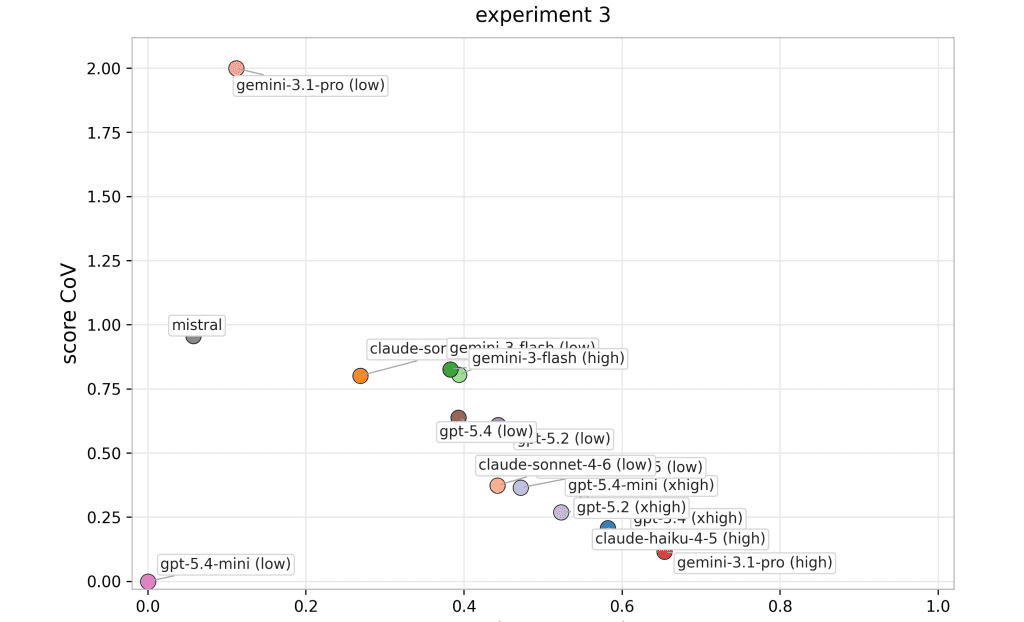
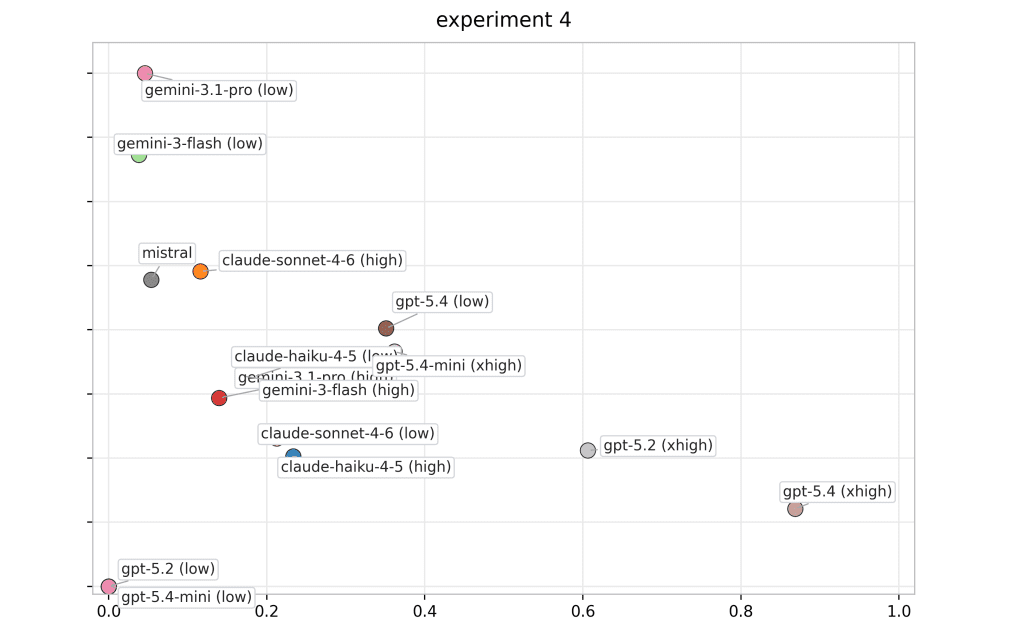
Imagine a sales manager who exceeds quarterly targets in one region through strong planning, accurate prioritization, and disciplined execution, but then struggles to create even a basic sales strategy for another region with similar market size, customer profile, and competitive dynamics. Their average performance might still look acceptable, especially if the first result was very strong. But for a business leader, that variability would be a warning sign. The question is not whether the manager can perform well once. The question is whether their judgment transfers reliably across comparable situations.
The same applies to a business analyst. An analyst might uncover a key profitability driver in one project, correctly connect several data points, and produce a recommendation that changes how the company allocates resources. But if the same analyst fails to identify the most important trends in a nearly identical analysis the following day, the organization cannot rely on them for critical decisions. Their occasional brilliance does not compensate for unstable performance, where every output must be checked from scratch.
Or consider an operations manager who successfully redesigns a complex supply chain process, reducing costs and improving efficiency, but later struggles to optimize a simpler workflow with fewer constraints. The issue is not that they lack capability altogether. The issue is that their competence appears inconsistently, making it difficult to predict when their recommendations can be trusted.
This is what we observe in current LLM agents. They can produce a strong answer in one run and a weak or misleading answer in another, even when the task structure is similar. In an organizational setting, a model is only useful if it combines acceptable average performance with low variability. High volatility increases verification costs, makes failures hard to anticipate, and can significantly overstate the mean performance of an AI system relative to its readiness for real-world deployment.


Business Utility
Most existing benchmarks for data and analytics agents focus primarily on average task performance. Depending on the benchmark, this may take the form of execution accuracy, task success rate, insight recall, or workflow completion metrics. While these measures capture whether a model can solve a task, they provide limited information about whether it can do so consistently across repeated runs. In practical business settings, however, repeatability is often as important as average quality because unstable outputs increase verification costs and reduce trust in the analytical process.
To address this gap, we introduce Business Utility, a synthetic risk-adjusted metric that combines analytical quality and repeatability into a single operational measure. Rather than evaluating only expected performance, the metric discounts the model’s analytical value when it exhibits unstable behavior across repeated executions.
The metric is constructed in three steps:
- Measuring instability. We quantify performance volatility using the Coefficient of Variation (CV), which captures variability in relative scores across repeated runs under the same experimental condition.
- Applying a risk discount. Instability is transformed into a loss term using a function inspired by prospect theory. This design reflects a simple operational assumption: decision-makers tend to value predictable analytical systems more highly than equally capable but less reliable alternatives.
- Multiplicative formulation. Business Utility combines average performance and stability multiplicatively. As a result, a model achieves a high score only when it delivers both strong analytical quality and sufficient repeatability. High variability directly reduces the utility assigned to otherwise strong average performance.
This design differs from conventional benchmark reporting, where performance and variability are often analyzed separately. By integrating both dimensions into a single measure, Business Utility provides a more deployment-oriented view of model usefulness, particularly for exploratory data analysis tasks where reproducibility of reasoning is essential. The chart below shows how instability affects the model’s score in Business Utility Evaluation.
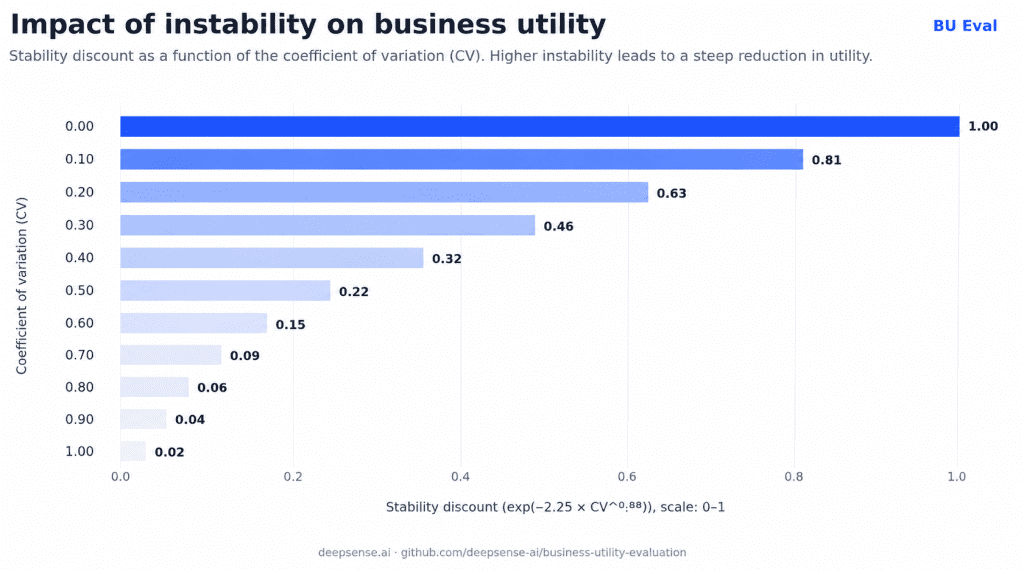
This design differs from conventional benchmark reporting, where performance and variability are often analyzed separately.
Why Managers Should Care
With this research, we aim to shift the conversation around AI deployment away from “can it get the right answer once?” to “can it get the right answer consistently enough to justify our trust?”
Our study reveals that while some models look highly competent on average, they remain fundamentally unreliable in repeated use, alternating unpredictably between productive reasoning and total dead ends. Managers don’t deploy analytical systems just because they have raw capability. They deploy systems when the expected gains are predictable enough to support accountability and keep oversight burdens low.
Ultimately, our Business Utility metric shows that trusting an AI data agent shouldn’t be just a vague feeling. It should be a measurable function of its demonstrated analytical quality and its steadfast repeatability.
Before handing over the keys to your data, it might be time to ask: is your AI actually dependable, or is it just having a lucky day?
Table of contents



