

How we developed a GPT‑based solution for extracting knowledge from documents
Practical business use cases for GPT
Recent breakthroughs in AI have showcased the vast potential of convenient natural language interfaces and taken the web by storm. Many companies across various verticals have started looking for specific business use cases to implement this technology. As our motto is “There is no better way to show our capabilities than to build solutions”, we have developed various technical showcase implementations to inspire and present potential solutions. In this blogpost we will discuss our latest GPT-based solution addressing the challenge of extracting knowledge from a set of PDF documents.
Meet Niffler

We have given our project the codename ”Niffler”. The name was inspired by a magical beast from the Harry Potter universe which is attracted to shiny things. We used AI to create its mascot image (see the result above!). Niffler’s task is to digest user-provided PDF (or text) documents and provide a chat interface along with highlights of the relevant document. Development of the application enabled us to put our experience into practice.
Time is money – who has time to search each document?
At any point in time, each company generates a huge number of documents – from legal, finance and administrative documentation to knowledge databases pertaining to internal processes. Employees join or leave the company, projects finish up, others start, and the pile of documents continues to grow. At some point, keeping track of what was done and where to find the information is impossible, and many hours are wasted. If the company’s core business is not about document organization, it represents a cost sink which is hard to even measure.
In some cases, even if the right document is found, it is often not enough – the document can be too long to read properly, or the need to supplement it with other ones to gain relevant insight arises. Hiring a dedicated staff member to search for information can be a possible solution, but wouldn’t it be great if an application could read all the documents, find and match relevant information and then provide a concise answer with all the required references? If we combine this idea with another AI model for speech-to-text, any team at a company could access technology similar to that owned by the superhero Tony Stark and efficiently work with the company or external data, which will of course provide a competitive advantage.
Overall solution overview
The business challenge for Niffler was described in bullet point form:
- we have a collection of documents – docs, PDFs, txt
- we look for an answer to a question which can be answered by any of the documents
- we want to get the answer as fast as possible
- we want to use a natural language interface
- ensuring the privacy and security of internal know-how is a priority for us
Our core technology is independent of the source of the GPT model, as we don’t want to be vendor locked, but rather flexible for every potential need. We decided to use OpenAI as an external component as it suited our needs best.
In order for Niffler to start working and supporting us in our daily work related to document analysis in accordance with the above-mentioned assumptions, we had to consider various crucial aspects, which we discuss below.
Operation costs for a GPT-based application
As with all projects, the costs depend on the choice of the model and where it is used. For example, in the case of OpenAI API payment depends on the number of tokens required by an input and output (neural networks require input paragraphs and sentences split into small processable units called tokens), but on the other hand Azure charges by the inference time, counting how many minutes your requests take.
A great way to see what a token is would be to visit the OpenAI tokenizer page which graphically displays it for your text.
One important detail is that the number of tokens includes not only direct user input but also hints we need to pass to the network – such hints provide additional guides, context or examples which are necessary for better results. Such techniques are called zero-shot and few-shot learning and provide a way to better align outcomes with expected results for concrete tasks without the associated costs of training a specialized model. There is also a hard limit on the maximum number of tokens acceptable to the network; the bigger the network, the more it can take as an input.
You may wonder about a specific example of why there is a need to have additional context provided to the network, as of course it increases operational costs. Please note that the model does not have a memory of a conversation (it cannot remember anything that either a user or the model itself wrote a second ago!) and to help it remember, it is necessary to inject the chat history or just a summary of it. The presence of additional, specially formatted prompts can enforce consistency and quality – it is a technique to prevent answering outside the desired bounds and to ensure it acts appropriately, even for a malicious user.
Moderation of AI
It is an unfortunate fact that large language models can generate outputs that are untruthful, toxic or simply unhelpful, and special care is required to address that issue. Providers of services like OpenAI and Azure provide some black-box moderation – but that’s not enough. To address such concerns, we came up with and implemented several techniques – one of which is to add an additional AI layer to moderate output. More details about our design are described in the reliability and security section later in the article.
Development prototype
We started with a proof of concept prototype – its main goal was to get feedback and iterate fast on the idea. We used Streamlit, a library for quickly building graphical interfaces for data science projects – it does not allow a high level of customization, but it allows you to quickly present visual results which greatly simplifies communication, especially with less technically-oriented people. Additionally, a major plus point is that it is easy for a data scientist to use without the need to involve frontend and backend developers.
The video below shows a set of prototype features of our AI system:
- answer a question about a set of documents and find the relevant one
- ask more in-depth questions about the content of the document found
- extend with recent and online knowledge – crawl the web with the Bing search engine.
The prototype has more features than our polished demo application and it is a teaser of what we can do.
Video 1. Prototype flow: We started by searching a set of documents and then asking for more details focused on those found. We also integrated a Bing search allowing the model to dynamically fetch data from the internet as requested.
The prototype allowed us to experiment with many different ideas before settling on a set of features to focus on. It also improved communication with project stakeholders, but even more importantly each team member showcased their work post daily with other team members which greatly improved internal collaboration and made it more fun.
Unstructured data and search
At the time of writing, out-of-the-box GPT-like models are unable to process big chunks of data or work with standard documents like PDF or Word documents.

Figure 1. Example of a PDF legal document we used for our tests from this Kaggle dataset Indian supreme court judgment.
To solve this challenge, we created a dedicated preprocessing step which digests native PDF formats – parsing PDF in general is not an easy task and OCR might not always work so well, but for the purposes of our prototype it is sufficient.
The resulting canonical form is then passed to an intelligence processing block – AI reads chunks of text, creating a summary and tags to make efficient searches possible – which calculates so-called embedding vectors. They encode semantic information in a very efficient manner. Such vectors are then stored in the vector database along with additional metadata.
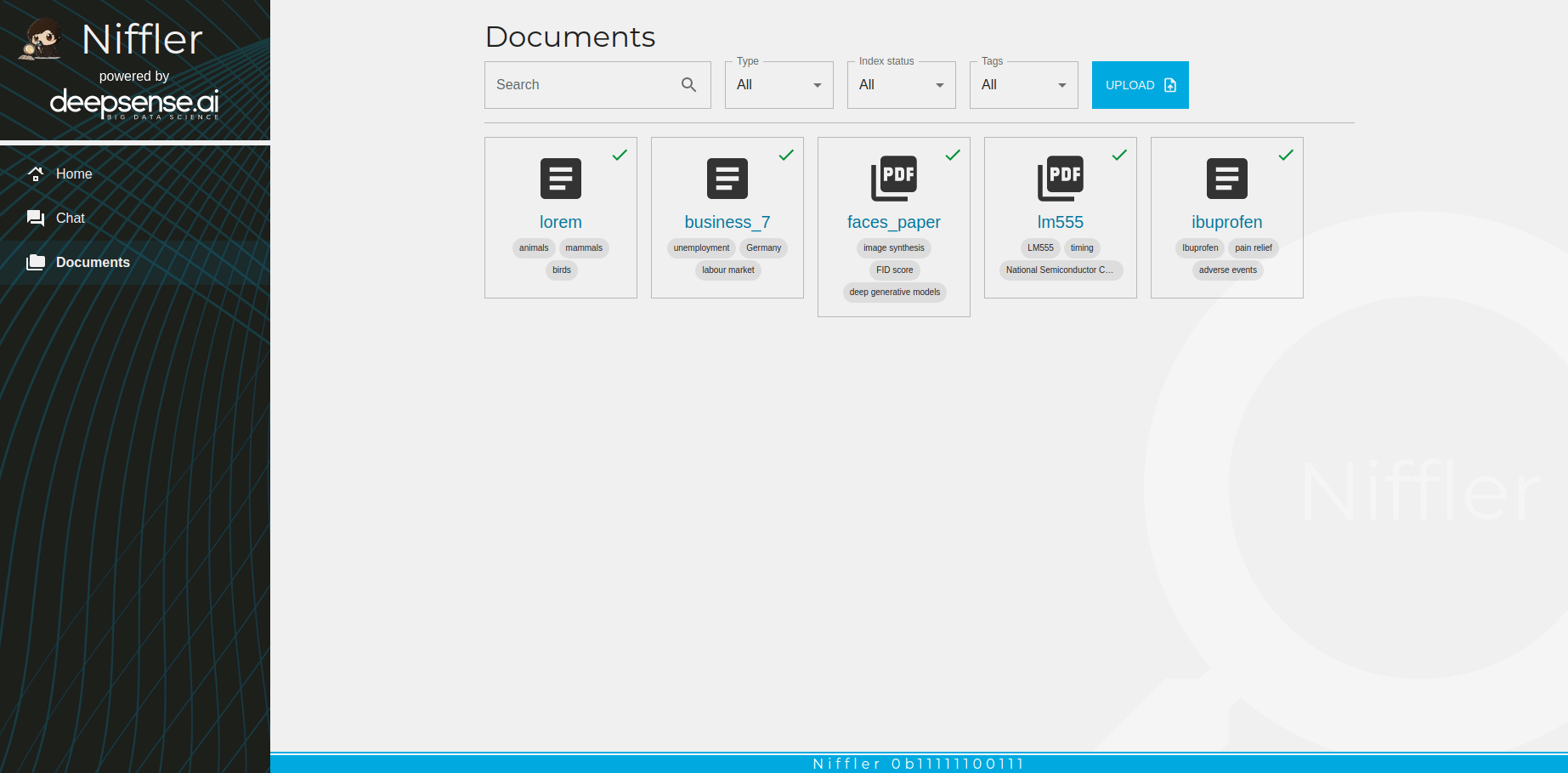
Figure 2. Each uploaded document has 3 tags useful for searching, clustering and prompt tuning.
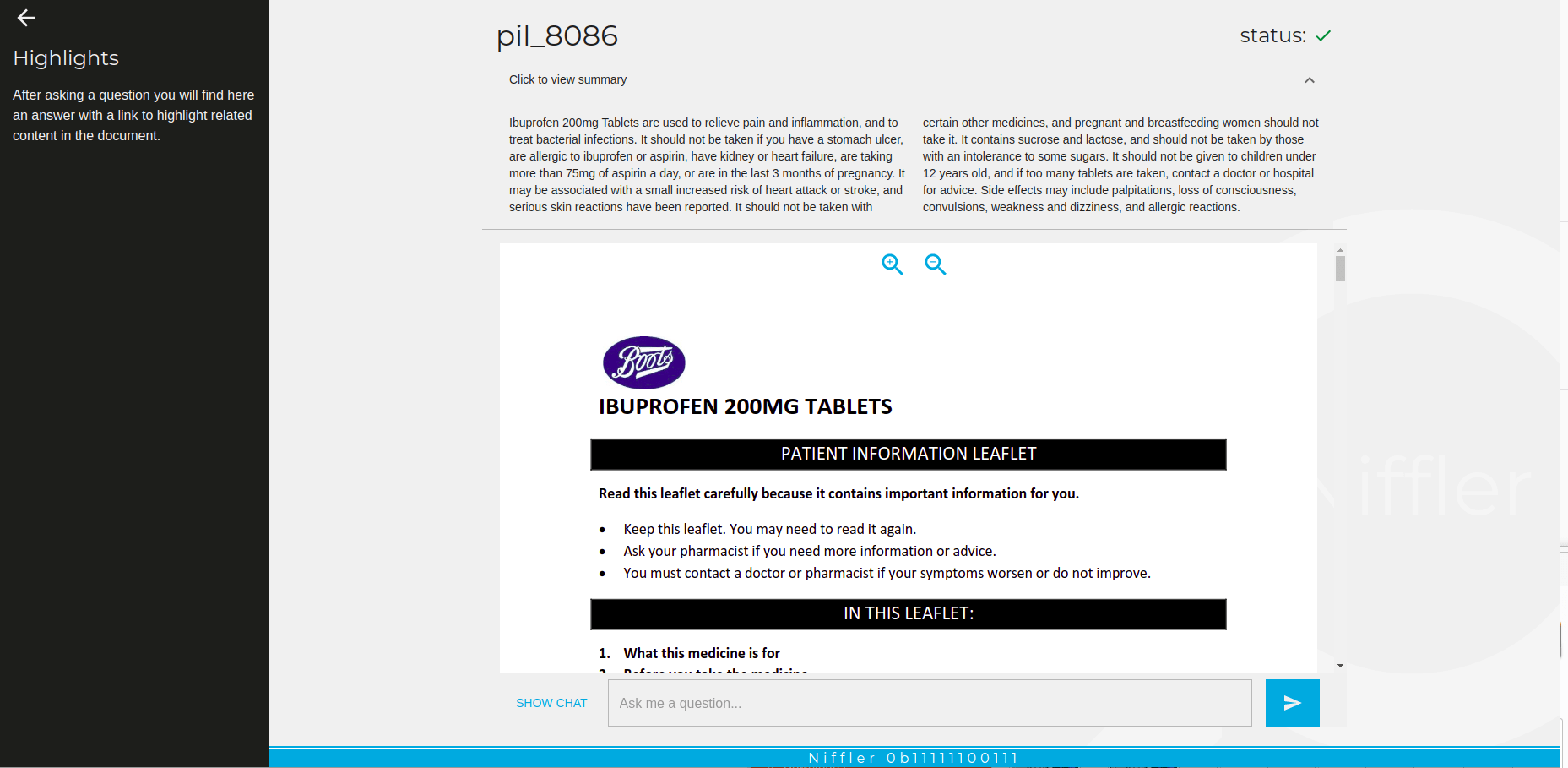
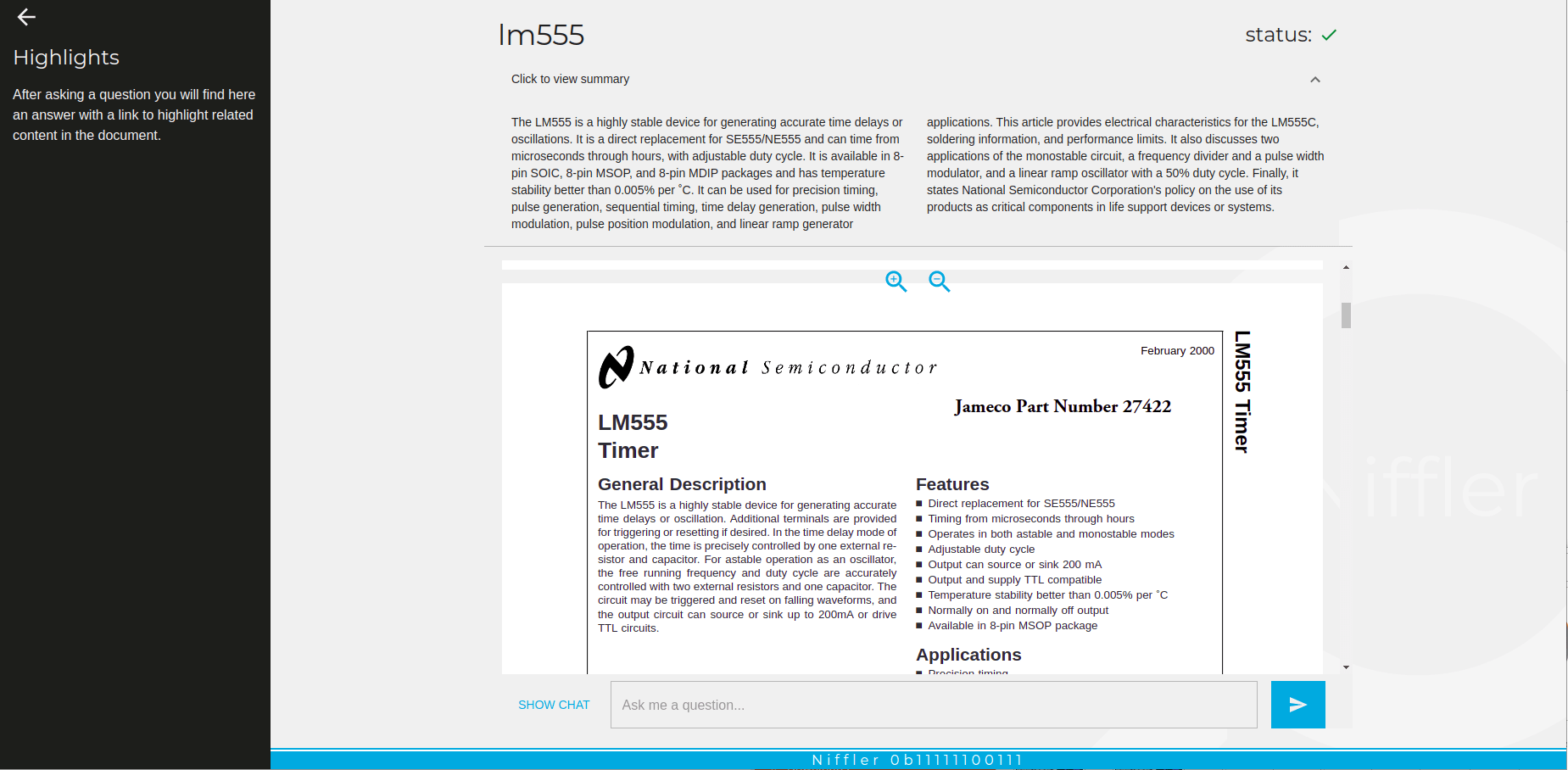
Figure 3. Two distinct PDF documents with summaries generated by AI. The shorter form is a great way to quickly learn about the content, as well as to align the system to focus only on questions and answers related to the document context.
This is a one-time cost to include each document in a database and it does take some time – however, the database can then be extended easily on the fly to include new documents, which can be done in the background without stopping the system from functioning.
This approach provides additional control which can be useful when it comes to improving or extending the performance of the system.
Great User Experience
Software should be pleasant to use. To achieve this, we decided to build our frontend as a ChatGPT-inspired interface – familiarity with chat interfaces makes it very easy and natural to use.
We have prepared two main views – a standard chat and document preview, together with a left sidebar which contains highlights, or questions with answers, serving as links which allow a user to revisit previous and current selection in the source document.
Screenshots, of course, are not enough to present interaction, so we decided to record a set of short clips to capture the user experience. One major strength of our application is that a user can not only quickly revisit answers, but also jump with just one click to the relevant source information and validate whether AI has done a good job with the answer provided.
Video 2. Question about a court case and inspecting the full document to show that only a small, relevant portion is highlighted.
Video 3. Medical leaflet – one question asked.
Video 4. Medical leaflet again, with more questions and a showcase of the highlights.
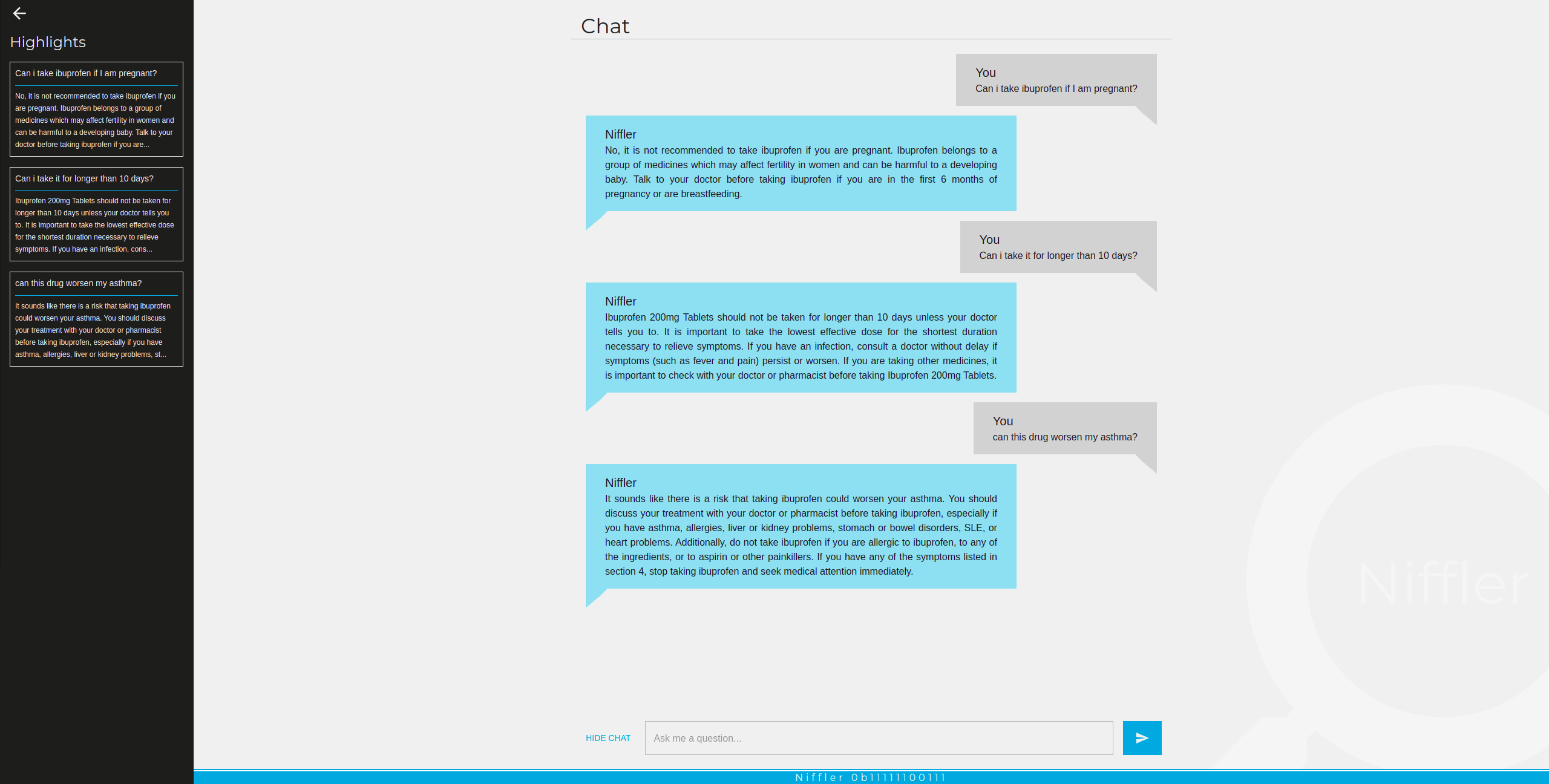
Figure 4. Example chat. Please note that our application is language-agnostic as the underlying GPT model.
Reliability and security concerns
GPT models can return different answers when asked the same question multiple times and there is no formal guarantee that they won’t make mistakes, answer on topic, or even offend a user. Indeed, it is a challenge many have experienced; it is mentioned in the Bloomberg article, the official limitations of GPT-4 (the most powerful model), and it is easy to find more articles on the topic. A mitigating solution that seems to work quite reliably for our use case is the additional 3 steps for standard flow that we describe in more detail below.
Our first line of defense is the aforementioned built-in moderation from OpenAI. We also researched prompts to ensure that AI can only provide answers on selected, narrow topics and data. The input prompt to the model is built only with the context connected to the question given the automatically generated document summary and 3 tags for a given document. Dynamic prompt engineering yields better results than a generic prompt and is a great alternative to manually hand-crafted prompts.
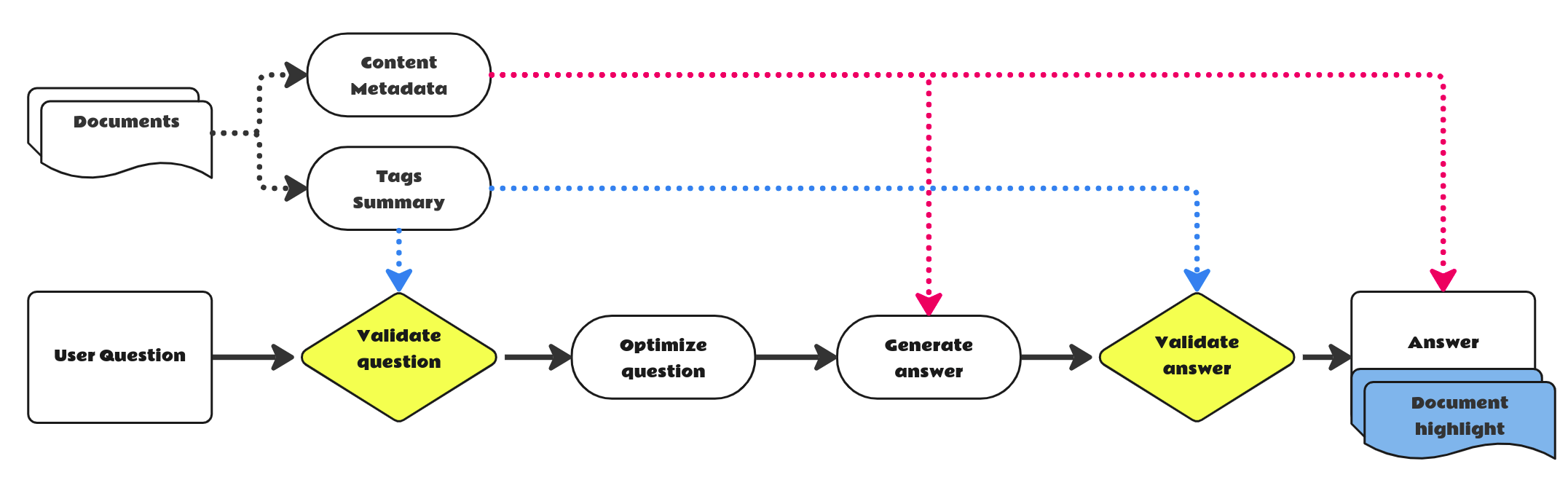
Figure 5. Simplified flow for a single document interactive question and the answers we have implemented.
The third line is actually our secret sauce – we use another AI to moderate output.
We tried several attacks by injecting text prompts known to alter model behavior (asking it to act as someone else and other different kinds of persuasions, DAN etc. which are mentioned by people on Twitter) or try to get it to answer something unrelated or on the topic but possibly harmful. We have failed to break it so far. On the other hand, it also sometimes leads to it not answering questions if they are not really on the topic. Depending on the use case, we can tune it to be more or less restrictive as all additional checks are opt-in. We also found out that even if the model refuses to provide an answer, the highlights mentioned in the next paragraph might be returned correctly.
To complete the user experience, we also quoted and showed what the source of information provided by Niffler is. This feature is a major selling point of our approach for any user as it addresses 2 aspects – verification of AI model output by the user and efficient information search. We especially placed a great deal of emphasis on presenting minimal, raw text in a visual way in the source document to enable the user to save as much time required to read the original content as possible. A concise AI answer is an added extra, not a replacement for your data source. At the moment truthful, fact-based answers and links to source information are still an unsolved problem under active research. Addressing this issue is very challenging, but we have already seen some promising results and gained a number of key insights during the development phase.
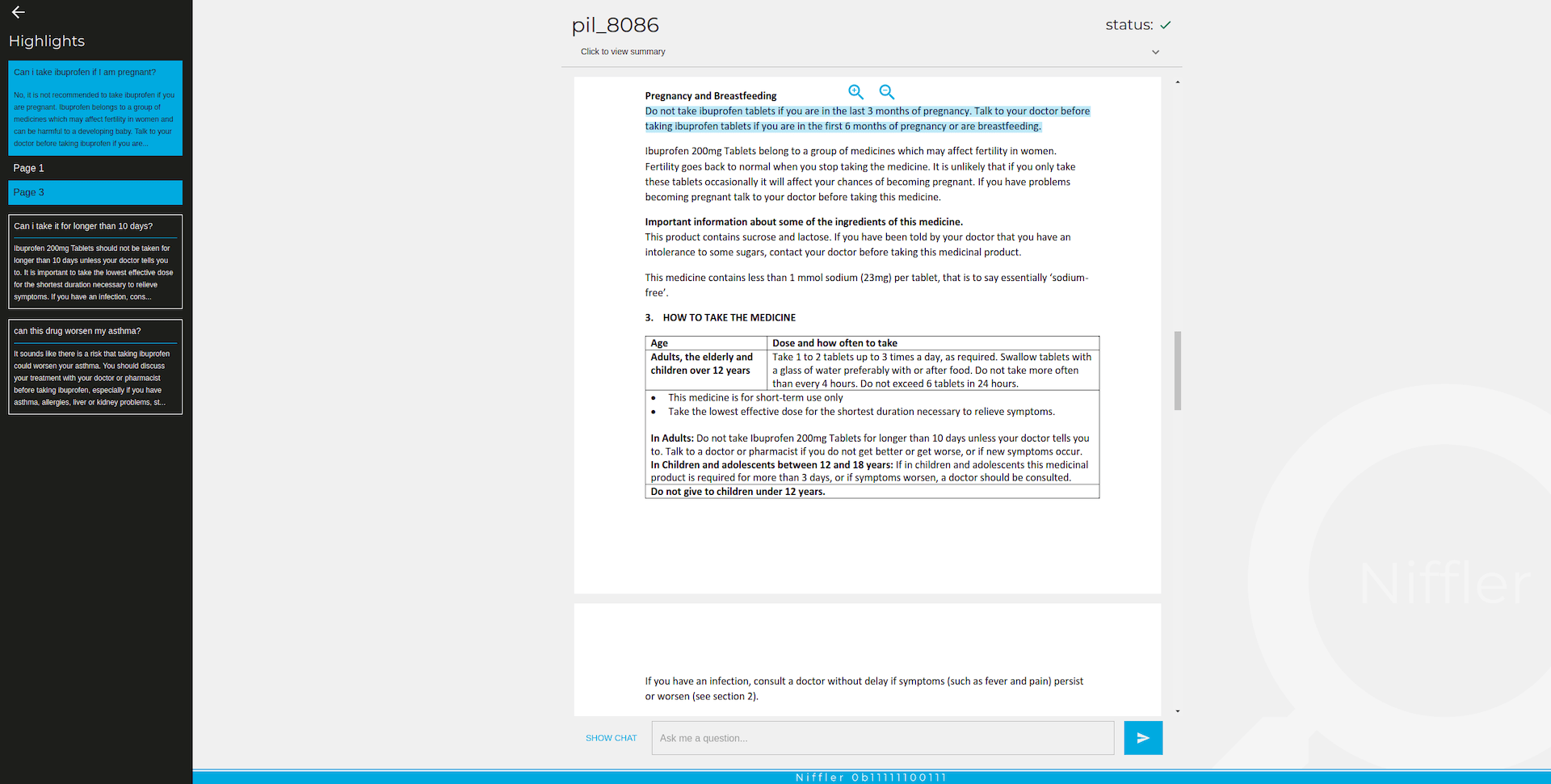
Figure 6. Example of an answer with the citation selected – in the PDF file we highlight the exact sources of information used by GPT, allowing a user to focus only on short, concise and important information.
Deployment as an internal tool
We have built a useful and interesting application – we hosted it internally on our servers and made it available for deepsense.ai employees to use. Our highlight module is one of the key strong points and people found it very useful. External use cases for the current Niffler version we witnessed included information retrieval from research papers and device manuals. Additionally, we created a knowledge base which we have shared internally (for now) with our colleagues to propagate everything we have learned.
Charged with even more superpowers
As we thrive on excellence, there are still more things to do.
Static knowledge is not enough for the rapid changes that are happening in the world of AI. That is why we added the possibility of integrating with external sources of data such as SQL databases or any APIs to Niffler. For example, if we would like to do an analysis of our competitors, we could search for different types of data along with recent business analyses, stock prices and so on.
Moreover, we created a prototype mode of an AI agent who can search and scour the Internet on its own.
On top of that, one of our team members set up an integrated Whisper service (a speech-to-text model API provided by OpenAI) – why does someone need to type on a keyboard if a superhero can just say things? With real-time transcription and text-to-speech synthesis, we make it even more enjoyable to use. Imagine being able to search for your Q3 financial statistics and receive them directly to your ear during a conversation with stakeholders! You could eliminate the need for someone to look it up and prepare a report.
Such things are entering the realm of possibility, and likely only companies which understand and can use such potential will dominate the market.
Get in touch!
If you are interested in your own solution, feel free to let us know! We can help you to build a competitive advantage by adding the features of GPT and other LLMs to your products and services.
