

Improve Apache Spark aggregate performance with batching
Seahorse provides users with reports on their data at every step in the workflow. A user can view reports after each operation to review the intermediate results. In our reports we provide users with distributions for columns in the form of a histogram for continuous data, and a pie chart for categorical data. In order to calculate data reports Seahorse needs to execute many independent aggregate operations for each data column. We managed to significantly improve aggregate performance by batching those operations together. That way those aggregations can be executed in just one data-pass.
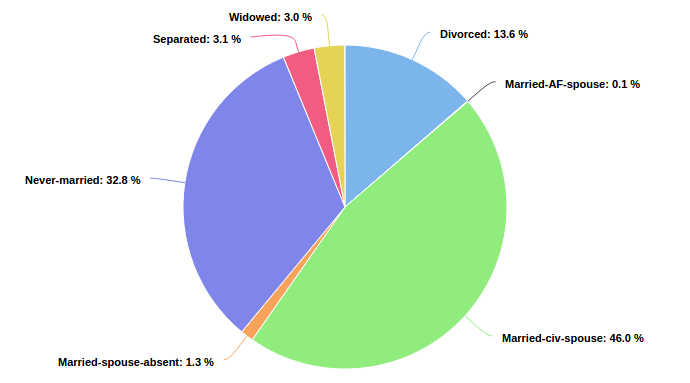
Categorical distribution
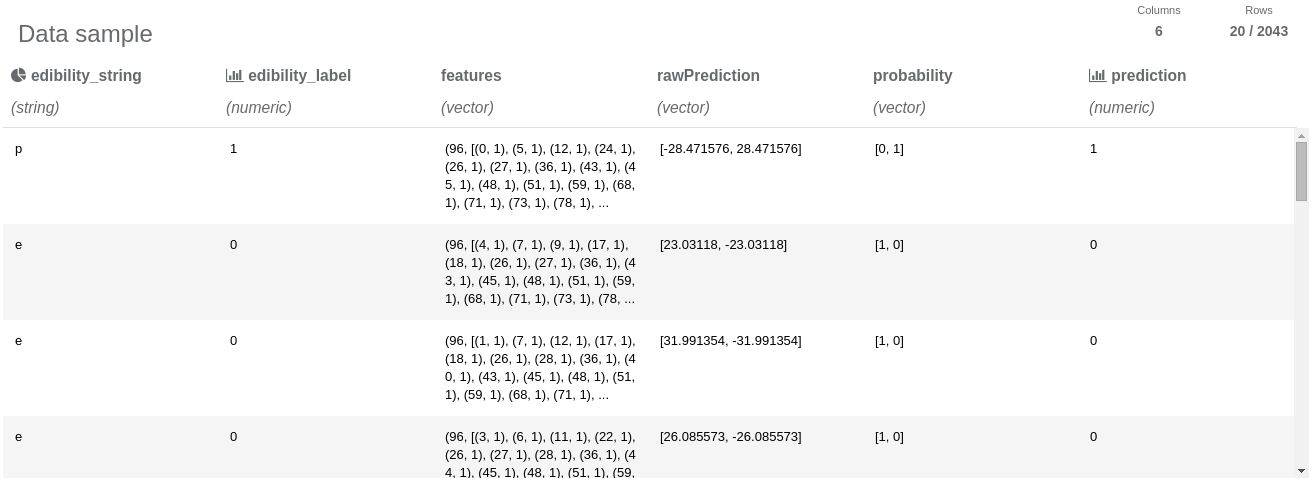
DataFrame report. Users are able to view distributions of their data after clicking on the chart icon.
Data Reports in Seahorse
Reports are generated for each DataFrame after every Operation. This means that performance is crucial here.
In our first approach, we used Apache Spark’s built-in `histogram` on RDD[Double] feature. We would initially map our RDD[Row] to RDD[Double] for each Double column and call `histogram` for each one.
Unfortunately this approach is very time-intensive. Calculating histograms for each column independently meant that we were performing expensive, full-data passes per each column.
Another alternative would be to introduce a form of special multi-histogram operation which would operate on multiple columns. Apache Spark already does that for column statistics – there is a Multicolumn Statistics method that calculates column statistics for each column in only one data pass (MultivariateStatisticalSummary).
This approach was not good enough for us. We would like to have a generic solution to combine arbitrary operations together instead of writing custom multi-operations.
Abstracting over aggregator
An operation producing one value out of a whole dataset is called aggregation. In order to perform an aggregation, the user must provide three components:
- `mergeValue` function – aggregates results from a single partition
- `mergeCombiners` function – merges aggregated results from the partitions
- `initialElement` – the initial aggregator value.
With these three pieces of data, Apache Spark is able to aggregate data across each partition and then combine these partial results together to produce final value.
We introduced an abstract `Aggregator` encapsulating the `mergeValue`, `mergeCombiners` and, `initialElement` properties. Thanks to this abstraction we can create `Wrappers` for our aggregators with additional behaviors.
MultiAggregator is one such wrapper. It wraps a sequence of aggregators and executes them in a batch – in a single data-pass. Its implementation involves:
- `mergeValue` – aggregates results from a single partition for each aggregator
- `mergeCombiners` – merges aggregated results from the partitions for each aggregator
- `initialElement` – initial aggregator values for each aggregator
case class MultiAggregator[U, T](aggregators: Seq[Aggregator[U, T]])
extends Aggregator[Seq[U], T] {
override def initialElement: Seq[U] = aggregators.map(_.initialElement)
override def mergeValue(accSeq: Seq[U], elem: T): Seq[U] = {
(accSeq, aggregators).zipped.map { (acc, aggregator) =>
aggregator.mergeValue(acc, elem)
}
}
override def mergeCombiners(leftSeq: Seq[U], rightSeq: Seq[U]): Seq[U] = {
(leftSeq, rightSeq, aggregators).zipped.map { (left, right, aggregator) =>
aggregator.mergeCombiners(left, right)
}
}
}
This special aggregator wraps a sequence of aggregators and then uses their `mergeValue`, `mergeCombiners` and `initialElement` functions to perform aggregation in one batch.
Reading Results in a Type-safe Manner
Each aggregator can return an arbitrary value type. In order to maintain type safety and genericity we added a special class encapsulating results for all input aggregators. In order to get specific aggregator result, we pass initial aggregator object to batched result. That way result type is correctly inferred from the aggregator’s result type.
// Usage // Aggregators to execute in a batch val aggregators: Seq[Aggregator[_,_]] = ??? // Batched result executed in one spark call val batchedResult: BatchedResult = AggregatorBatch.executeInBatch(rows, aggregators) // Accessing result is done by passing origin aggregator to the result object val firstAggregator = aggregators(0) // Type of `firstResult` is derived from output type of `firstAggregator` val firstResult = batchedResult.forAggregator(firstAggregator)
As we can see, each value type is derived from the aggregator’s return type.
Measurements and comparing aggregate performace
Let’s measure time for calculating histograms for data rows made up of 5 numeric columns.
In this experiment, we first execute an empty foreach statement to force Spark to cache the data in the clusters (job 0). Otherwise, the first job would have additional overhead for reading the data.
// job 0 - forces Spark to cache the data in cluster. It will take away data-loading overhead // from future jobs and make future measurements reliable. rows.foreach((_) => ())
Then we will run Spark’s `histogram` operation for each column (jobs 1- 5).
private def sequentialProcessing(rows: RDD[Row], buckets: Array[Double]): Seq[Array[Long]] =
for (i <- 0 until 5) yield {
val column = rows.map(extractDoubleColumn(i))
column.histogram(buckets, true)
}
And use our batched aggregator (job 6).
private def batchedProcessing(rows: RDD[Row], buckets: Array[Double]): Seq[Array[Long]] = {
val aggregators = for (i <- 0 until 5) yield
HistogramAggregator(buckets, true).mapInput(extractDoubleColumn(i))
val batchedResult = AggregatorBatch.executeInBatch(rows, aggregators)
for (aggregator <- aggregators) yield batchedResult.forAggregator(aggregator)
}
The results:
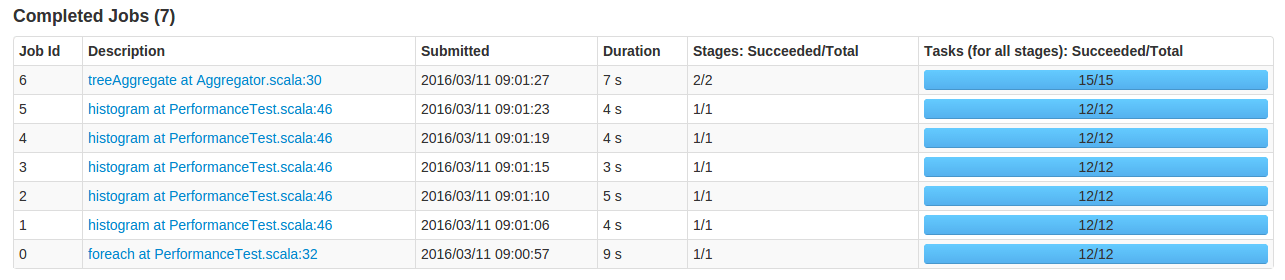
We improved from a linear number of `histogram` calls against column number to a single batched aggregate call. This method is about 5 times faster for this specific experiment.
Summary
Using only Spark’s built-in `histogram` method we would be stuck with calling it for each numeric column. Using our approach we can achieve the same results in a single method call which yields a large aggregate performance boost. Our method is roughly N times faster (where N stands for the number of columns).
We are also able to batch other arbitrary aggregators along with it. In our case they would be:
- Calculating distributions of categorical columns
- Counting missing values
- Calculating min, max and mean values for numerical columns
In the future we could add more operations as long as they comply with the aggregator interface.
