
Operationalizing Large Language Models: How LLMOps can help your LLM-based applications succeed
The recent strides in machine learning have given rise to an array of powerful language models and algorithms. These models offer tremendous potential but also present unique challenges when it comes to operationalizing large language models in large-scale ML projects. In this blog post, we will discuss the importance of LLMOps best practices, which can enable you to take your existing or new machine learning projects to the next level.
Naturally, training a machine learning model (regardless of the problem being solved or the particular model architecture chosen) is a key part of every ML project. Preceded by data analysis and feature engineering, a model is trained and ready to be productionized. But what happens next?
There is growing awareness among machine learning and data science practitioners of the crucial role played by pre- and post-training activities. Assigning more weight to these parts is one of the key principles of LLMOps.
What is LLMOps?
To put it simply, LLMOps (Large Language Model Operations) is a framework for operationalizing large language models, ensuring that machine learning works effectively in real-world scenarios over the long term. As previously mentioned, model training is only part of what machine learning teams deal with. Other essential steps include:
- Data ingestion, validation, and preprocessing
- Model deployment and versioning of model artifacts
- Live monitoring of large language models in a production environment
- Monitoring the quality of deployed models and potentially retraining them
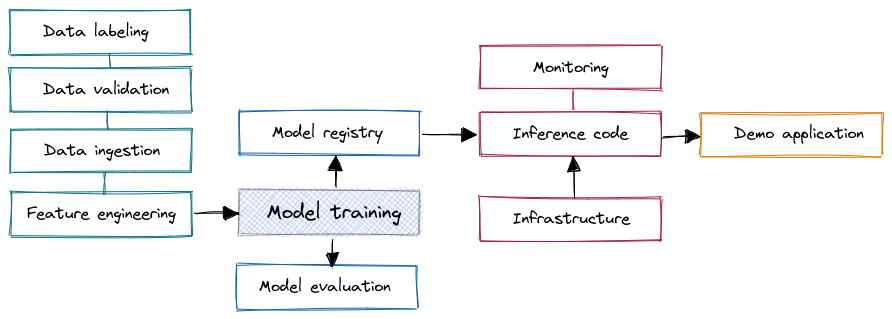
Figure 1. Model training is only a small part of a typical machine learning project (source: own study)
In the context of LLMs, the focus might shift to fine-tuning, few-shot learning, or prompt engineering rather than full-scale training. Nevertheless, these processes still require steps such as prompt template preparation and result evaluation. Regardless of how you improve model accuracy, ensuring system reliability and consistency is crucial.
LLMOps encompasses concepts, guidelines, and tools that facilitate the management and maintenance of a machine learning system. LLM automation tools help integrate consecutive steps and ensure that the entire process—from model training to inference—is reproducible, automated, and properly monitored. This approach is as vital for fine-tuning large language models internally as it is for using LLMs-as-a-service, such as leveraging the OpenAI API for GPT models. Even if you don’t train or own the model, careful LLM monitoring and automation of data input and output processes are essential.
Now that we have a common understanding of the term, let’s delve into how adopting LLMOps principles will make your project more efficient, sustainable, and robust.
Ensuring Your LLMs Are Healthy and Delivering Desired Results
One of the most critical aspects of LLMOps is monitoring. This includes monitoring LLM application health, input and output data quality, and the overall responsiveness and behavior of models. It also involves tracking the traffic that flows into your LLM-based application. Why are these elements so important?
You’ve likely invested significant time in selecting the right architecture for your application. The team has decided which large language model would be the best choice for your use case, fine-tuned the model on your knowledge base, and you’re ready to go into production. That’s great! However, challenges often arise post-deployment.
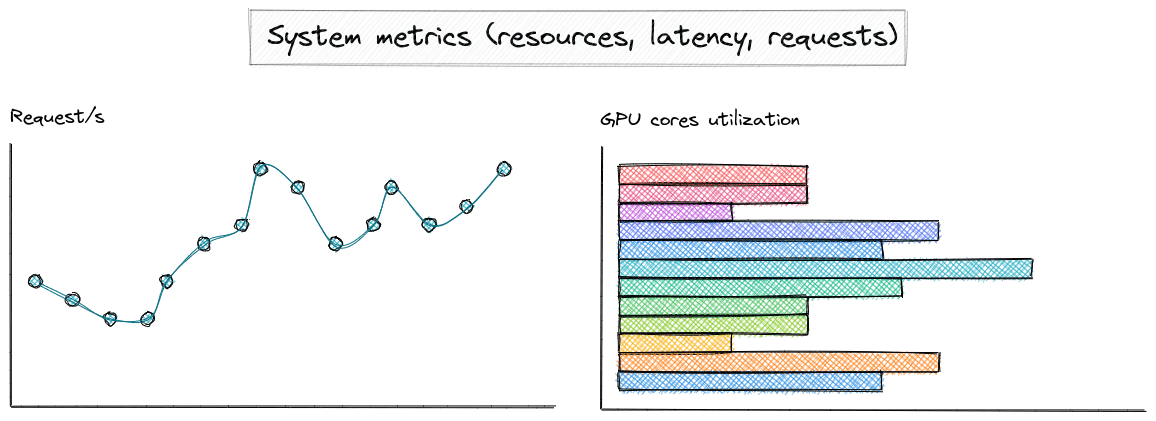
Figure 2. Sketch of system-related metrics to be monitored
Some potential issues include:
- Resource Consumption: Your system might receive more traffic than anticipated, leading to an overload (see Figure 2). This can result in errors and user dissatisfaction.
- Performance Monitoring: Even without stability issues, response times might be unacceptable due to traffic bottlenecks, causing delays for end users.
- Resource Spikes: Inconsistent production traffic can lead to significant resource consumption (e.g., RAM, CPU, or GPU usage), potentially causing services hosting your LLMs to crash.
There are additional challenges beyond those mentioned above, such as changes in model behavior due to sudden input data drift (see Figure 3). When users start interacting with your application in unexpected ways, the predictions made by large language models can shift significantly. This can result in incorrect outputs being presented to end users.
Implementing a robust monitoring platform, along with dashboards that visualize resource consumption and application health, is essential. It’s also crucial not to overlook other components of modern applications that utilize large language models, such as vector databases and frontend services. Every aspect of a mature, production-grade system should be carefully monitored. This applies to all long-term LLM-based applications, whether it’s a chatbot, a simple knowledge retrieval service, or any other use case.
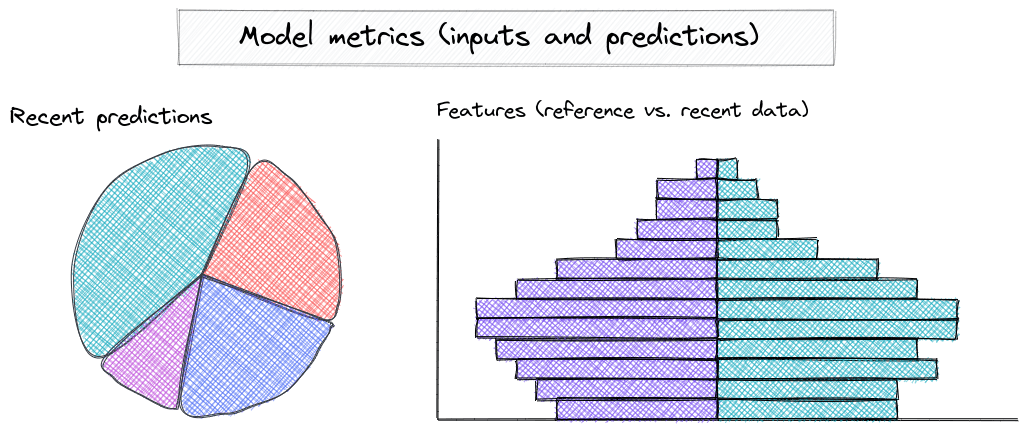
Figure 3. Sketch of model-related metrics to be monitored (source: own study)
Empowering Engineers Through Automation
Apart from monitoring, another key concept of LLMOps is the automation of software development (or machine learning) processes. In many projects, a significant amount of time and effort is devoted to exhausting and repetitive tasks, such as:
- The manual deployment process, where engineers must follow a checklist to push a new release of the application into production. Even more concerning is that if a bug is found, the process must be manually reversed step by step.
- Regularly checking the monitoring dashboard to ensure the application works as expected and produces the desired results (as discussed in the previous section).
The problem with these tasks is that, despite being monotonous, they are both critical to your application and highly error-prone—a combination that’s far from ideal, right?
To address this issue, we can automate these tasks (see Figure 4) to ensure they are executed consistently, reducing the potential for human error and allowing developers to focus on more valuable tasks, thereby increasing your team’s productivity.
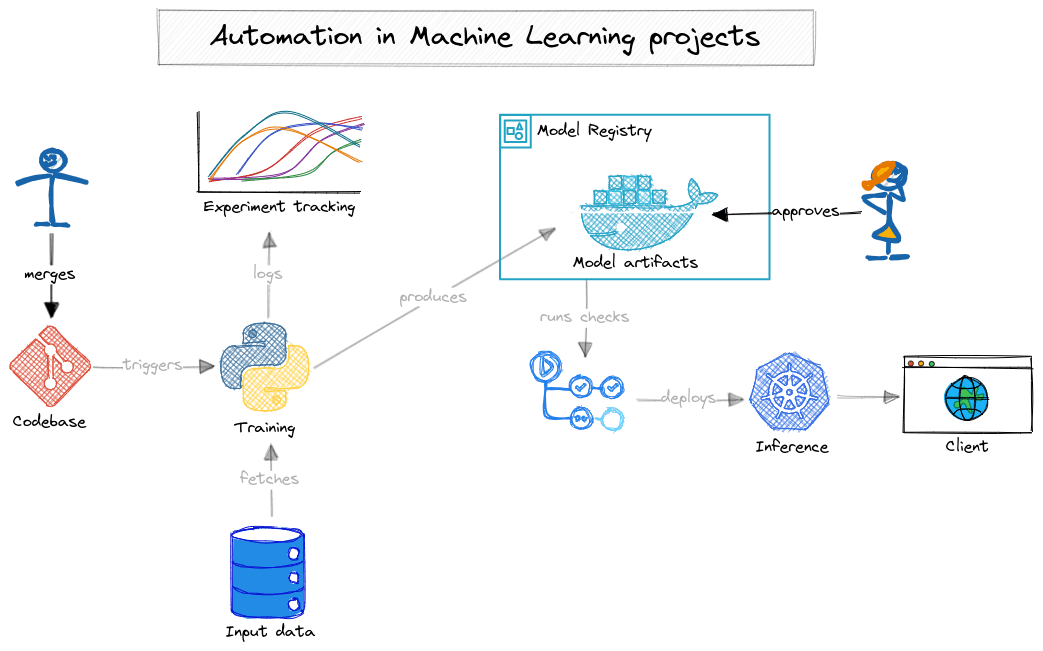
Figure 4. Example of automated flow in a machine learning project (source: own study)
The manual deployment process can be replaced with an automated continuous delivery pipeline that thoroughly tests your LLMs and application. Developers may only be needed to approve the deployment, rather than perform a lengthy list of manual steps. Instead of regularly and tediously checking charts and values, you could configure a monitoring platform to send notifications (via Slack, email, or other tools) whenever a metric drops below a certain threshold or the application becomes unresponsive. Figure 4 illustrates an example of such a setup, where only two manual actions require human intervention, while the rest occurs automatically:
- A Data Scientist merges a change in the training code or parameters into the codebase. This triggers a series of quality checks (e.g., linting, tests) and starts a training job. During training, all model metrics and metadata are logged automatically. A successful run produces model artifacts saved in a model registry, ready to be picked up for inference.
- The team validates the model metrics and decides whether to deploy the newly trained model. A Machine Learning Engineer approves the model in the registry, which automatically triggers a validation procedure that, if successful, delivers a working deployment into the inference environment.
Of course, the desired level of automation varies by project, depending on the scale, frequency of deployments, and overall maturity of the machine learning system. However, this example should provide a clear overview of how properly applied automation can reduce the risk of human error and make the entire end-to-end process much faster and more reliable.
Reducing Operational Costs Through LLMOps
Last but not least, implementing an LLMOps platform can lead to significant savings in your project budget. Let’s explore this further by revisiting the aspects we discussed earlier: monitoring and automation.
First, thanks to monitoring, you will have precise visibility into your infrastructure utilization. For instance, if your LLM-based service is deployed in a cloud environment, you can adjust the type of instance you’re using to avoid unnecessary costs for unused resources. Conversely, if you use external models via an API (such as OpenAI GPT), it’s advisable to track your expenses with a billing dashboard provided by the vendor or to develop an in-house system to monitor costs and their correlation with variables such as the length of inputs sent to these models.
Tracking such metrics will enable you to compare different architectural choices, cloud providers, or specific large language models that you deploy. Monitoring is essential not only for maintaining project health but also for optimizing business metrics and expenditure.
As mentioned earlier, automation can free your team from monotonous daily tasks, allowing them to use their knowledge and time more productively.
There are also other LLMOps concepts and practices that we did not explicitly cover in this blog post, such as model retraining and automatic data labeling. Furthermore, applications that utilize large language models often include other key components, such as vector databases—where the same principles of monitoring, automation, etc., apply.
When implemented correctly, all of these elements can help you maintain your project in a more robust and cost-effective way.
Conclusion
Implementing LLMOps best practices in your machine learning system makes it more reliable, robust, and automated. Once these practices and automation tools are in place, deploying new models to production will require minimal effort, as most processes will happen seamlessly behind the scenes. You’ll be able to monitor every log, metric, and behavior, ensuring quick responses to unforeseen issues.
Even when using models-as-a-service via third-party APIs, it’s important to apply LLMOps principles. While these services handle training and model-serving, you remain responsible for ensuring smooth integration and long-term stability. By overcoming LLM integration challenges and addressing LLM operational challenges, you can build a more sustainable and successful machine learning product.
