
Table of contents
At deepsense.ai, we strive to make our mark on the cutting-edge research leading towards intelligent machines by providing practical machine learning tools and designs that make it much easier for scientists to track their experiments and verify novel ideas.
Table of contents
One particular step towards achieving this ideal was distributing a state-of-the-art Reinforcement Learning algorithm on a large CPU cluster, allowing super-fast training of agents that learned to master a wide range of Atari 2600 games. This post contains a brief description of our Distributed Deep Reinforcement Learning experiments. For a more in-depth look you can read our paper on the matter here.
Distributed reinforcement learning
Atari games are a widely accepted benchmark for deep reinforcement learning (RL). One common characteristic of these games is that they are very easy for humans to crack conceptually. Comparing the time it takes humans and computers to master these games can provide a clear indication of the capabilities of modern artificial intelligence. The first approaches to teach an agent to play Atari were developed by DeepMind and required around a week of training. The A3C algorithm developed later was able to achieve human performance in most games and did so with a similar amount of training time. But could computers ever learn faster than us?
Creating such a quick and bright Atari games learner would mean that computers outpaced us in understanding a game environment. The techniques that said agent would use to quickly develop a good grasp of the game could be studied to further develop our understanding of the cognitive features of a human brain. Moreover, faster training would give researchers considerably more flexibility in terms of experimenting and thus make verifying various RL approaches much quicker. Today, we present a Distributed Reinforcement Learning algorithm that efficiently trains on a large cluster of 64 12-core CPUs (768 cores in total). Our design enables agents to learn to play Atari games in as little as 20 minutes. We’re making our implementation available here.
| Breakout | ||
| Initial performance | After 15 minutes of training | After 30 minutes of training |

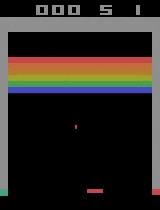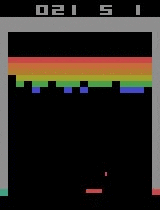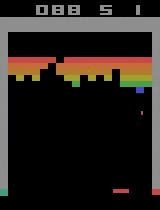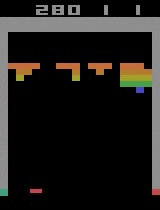

| Assault | ||
| Initial performance | After 15 minutes of training | After 30 minutes of training |



| Boxing | ||
| Initial performance | After 15 minutes of training | After 30 minutes of training |



Our achievement and results
By distributing the BA3C (details of single-machine implementation here) reinforcement learning algorithm, we were able to make an agent teach itself to play a wide range of Atari games rapidly, by just looking at a raw pixel output (game screen) from the game emulator. Our best experiments were distributed across 64 machines, each of which had 12 Intel CPU cores. In the game of Breakout, our agent achieves a superhuman score in just 20 minutes, which is a significant reduction of the single machine implementation learning time. Training for Breakout on a single computer takes around 15 hours, bringing our implementation very close to the theoretical scaling (assuming computational power is maximized, using 64 times more CPUs should yield a 64-fold speed-up). The graph below shows the scaling of our implementation for different numbers of machines. Moreover, our algorithm exhibits robust results on many Atari environments, meaning that it is not only fast, but also adaptable to various learning tasks.

Using Neptune, a tool developed here at deepsense.ai, we were able to proactively track the performance of our agents. This enabled us to instantly verify if a certain feature of the algorithm works as expected. In Neptune, we could observe our agents’ real-time scores along with many other experiment-related metrics that we later used to optimize the algorithm. The graph below shows training curves from 10 different experiments on the Breakout game. Graphs were updated live in Neptune as the training went on.
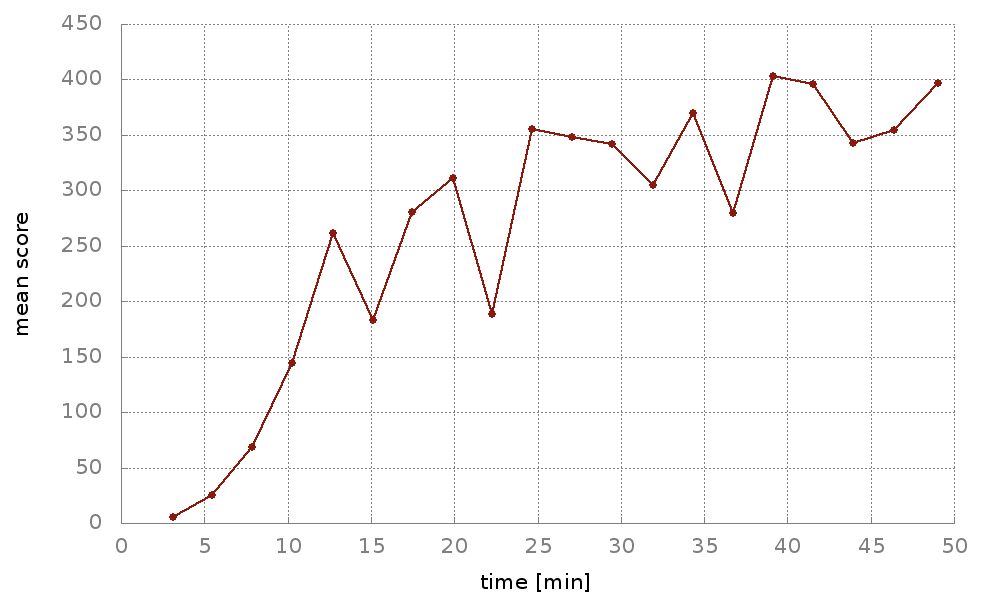
We managed to achieve very competitive training times. As we hope to inspire further research in the RL domain, we decided to open-source the implementation of our distributed reinforcement learning algorithm.
Details of the implementation
In the following section we describe the technicalities of our distributed set-up, aiming primarily to address a more advanced audience. To get the most out of our description, we recommend readers familiarize with this study done by the Google Brain team.
For parallelization we chose the synchronous paradigm. Synchronizing all our workers yielded much faster training times than the asynchronous set-up, where each node works for itself. Using a synchronous design prevented our model from using stale gradients in the updates, but at the same time introduced a problem known as slow stragglers. As suggested in the Google study linked above, deploying a few more backup workers can significantly reduce the impact of the slow stragglers, and doing just that has worked very well for us.
One of the biggest challenges that arises when dealing with largely distributed training is the cluster interconnect congestion on the parameter server nodes. Sending the gradients from multiple workers to a single parameter server bottlenecks the pipeline, effectively slowing down the training process.
To deal with that, we first reduced the model’s size. We noticed that a contraction of the neural network did not affect the accuracy of the algorithm, but did significantly increase the number of points processed per second, and hence also its speed.
Since the communication overhead between the workers and parameter server was the biggest impeding factor to the speed of learning, we decided to balance the pressure on the pipeline by adding more parameter servers. This way, with the model weights distributed uniformly on multiple parameter servers, our training times began to pick up speed. The increase in processed data points per second for a different number of parameter servers can be seen below.
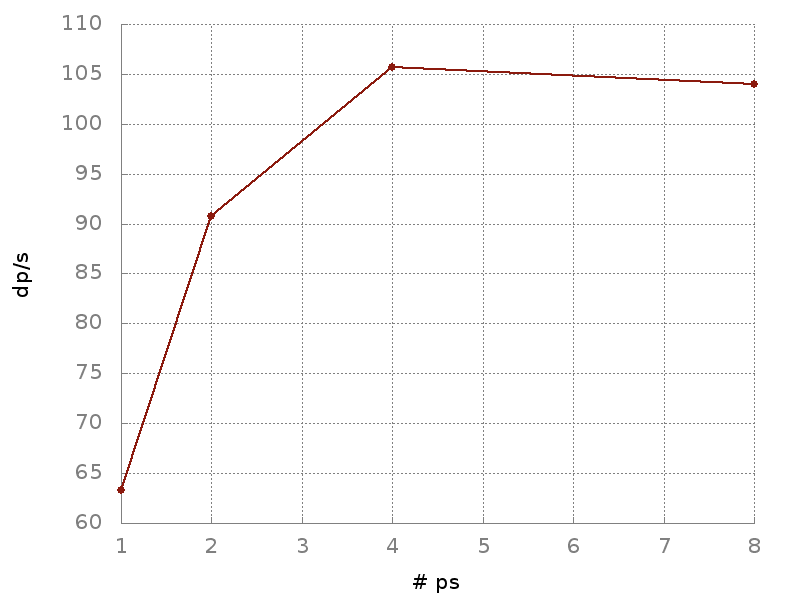
Related work
The distributed paradigm has been a topic of extensive research. Parallelization on 256 concurrent GPUs recently enabled a Facebook team to efficiently train the Resnet-51 model in one hour. Later developments from UC Berkeley reduced the time of training ImageNet to merely 24 minutes. The development of a distributed evolution strategy (ES) algorithm has led researchers from OpenAI to train agents to play Atari games in one hour by using 720 parallel CPUs. Since none of these designs have ever been applied to classical RL, the work done here can be considered pioneering in the field of distributed reinforcement learning.
Acknowledgements
The work on this distributed reinforcement learning design would not have been possible without the services of the PL-Grid supercomputing infrastructure, which provided us with all the computational power needed to conduct this research. We would like to thank Henryk Michalewski from the University of Warsaw for supervising the project and granting us access to the PL-Grid. We also used tensorpack, developed by Yuxin Wu, a very efficient open-source implementation of the A3C algorithm.





