

Using machine learning in credit risk modelling
Cost of risk is one of the biggest components in banks’ cost structure. Thus, even a slight improvement in credit risk modelling can translate in huge savings. That’s why machine learning is often implemented in this area.
We would like to share with you some insights from one of our projects, where we applied machine learning to increase credit scoring performance.To illustrate our insights we selected a random pool of 10 000 applications.
How the regular process works
Loan applications are usually assessed through a credit score model, which is most often based on a logistic regression (LR). It is trained on historical data, such as credit history. The model assesses the importance of every attribute provided and translates them into a prediction.
The main limitation of such a model is that it can take into account only linear dependencies between input variables and the predicted variable. On the other hand, it is this very property that makes logistic regression so interpretable. LR is in widespread used in credit risk modelling.
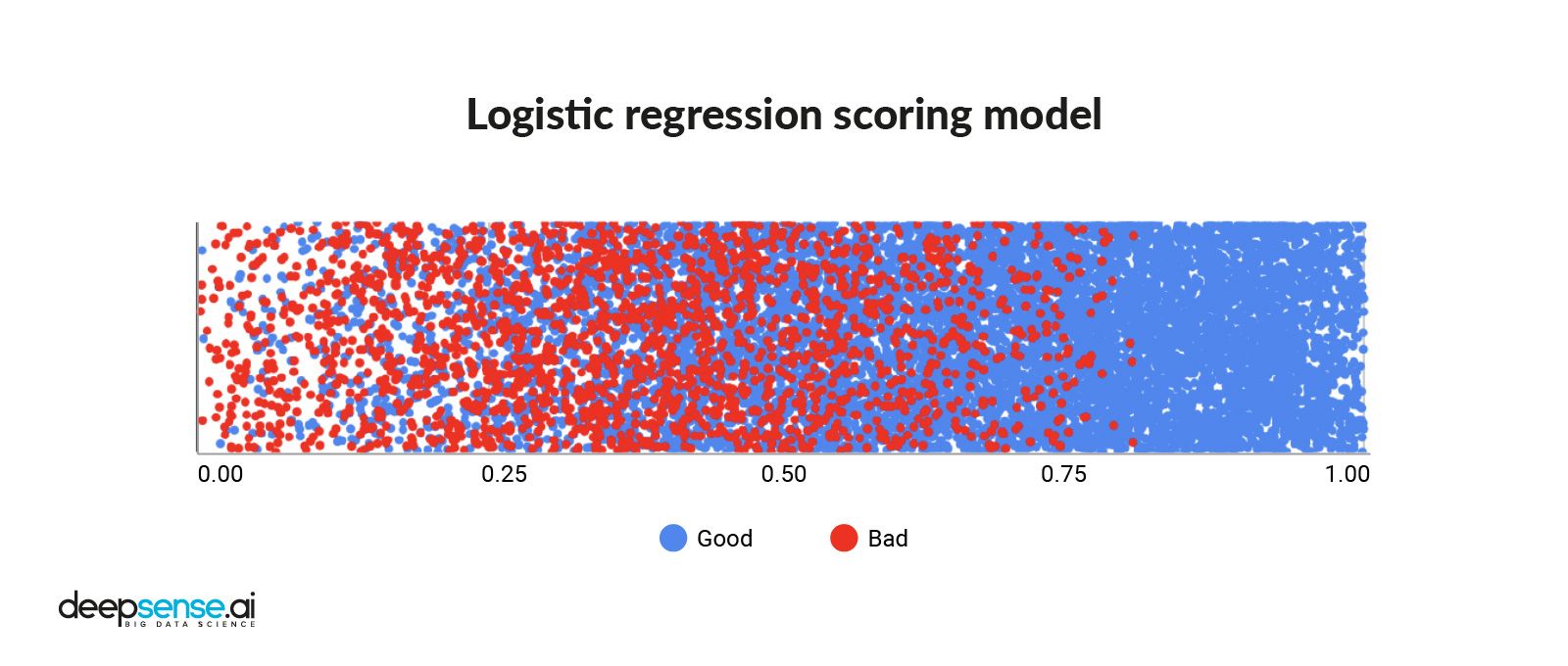
Credit scoring from a logistic regression model
What machine learning brings to the table
Machine learning enables the utilization of more advanced modeling techniques, such as decision trees and neural networks. This introduces non-linearities to the model and allows to detect more complex dependencies between the attributes. We decided to use an XGBoost model fed with features selected with the use of a method called permutation importance.
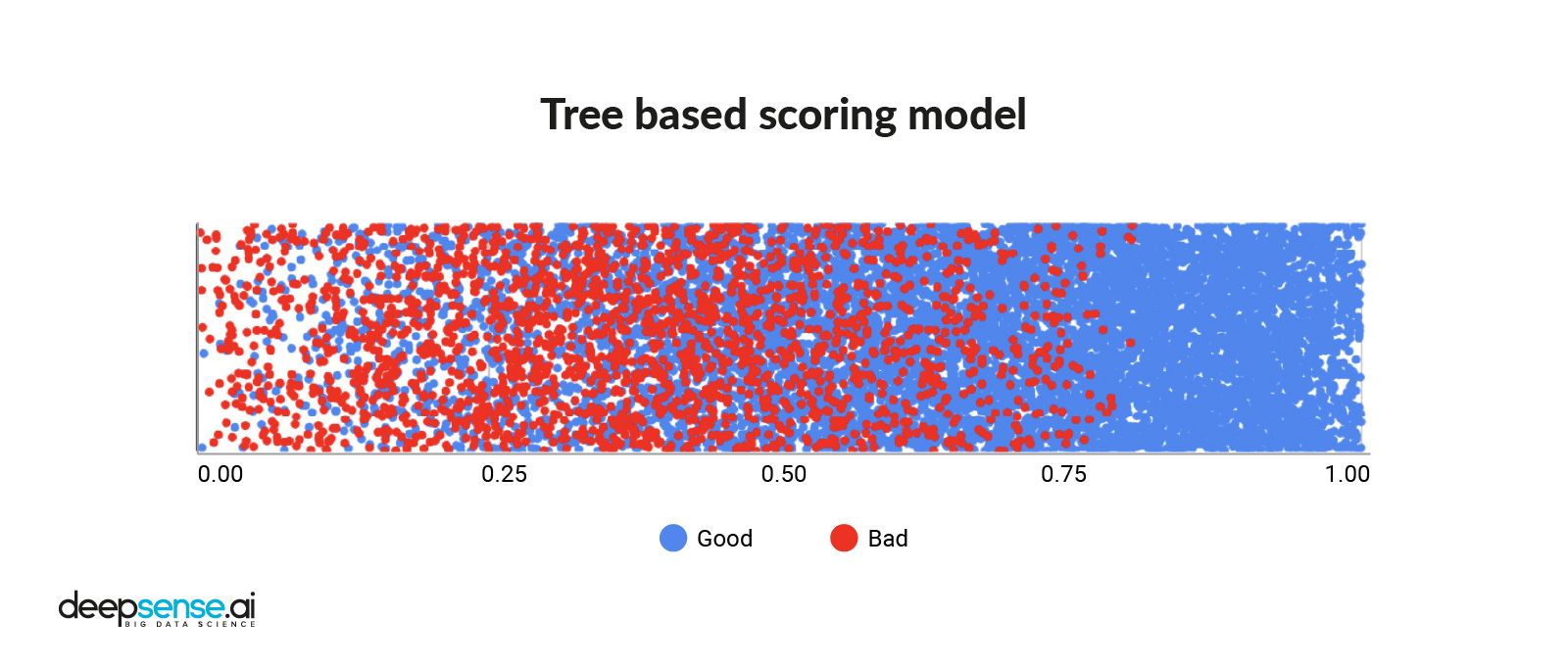
Credit scoring from tree-based model
However, ML models are usually so sophisticated that they are hard to interpret. Since a lack of interpretability would be a serious issue in such a highly regulated field as credit risk assessment, we opted to combine XGBoost and logistic regression.
Combining the models
We used both scoring engines – logistic regression and the ML based one – to assess all of the loan applications
With a clear correlation between the two assessment approaches, a high score in one model would likely mean a high score in the other.
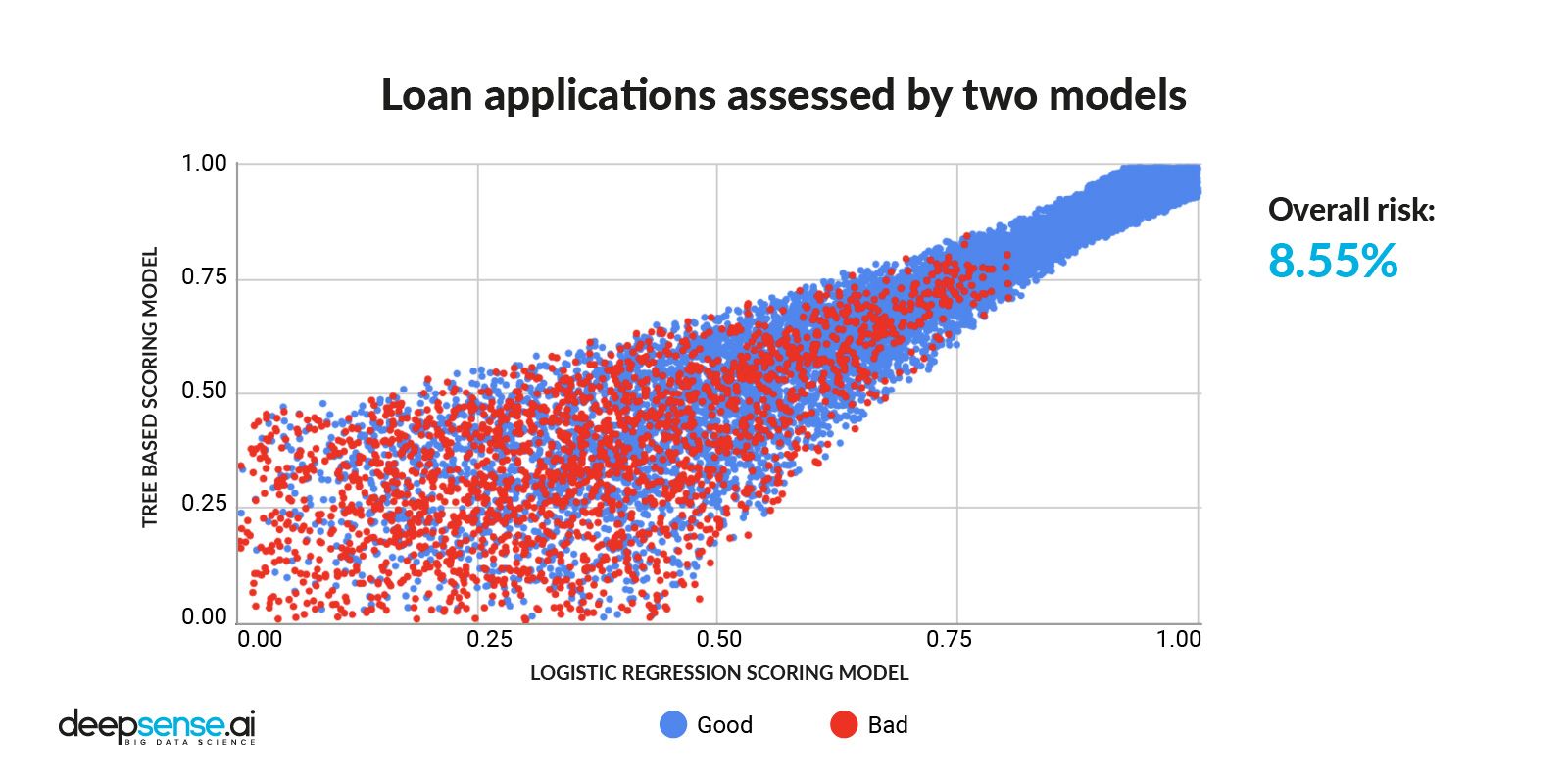
Loan applications assessed by 2 models
In the original approach, logistic regression was used to assess applications. The acceptance level was set around 60% and the risk resulted at 1%
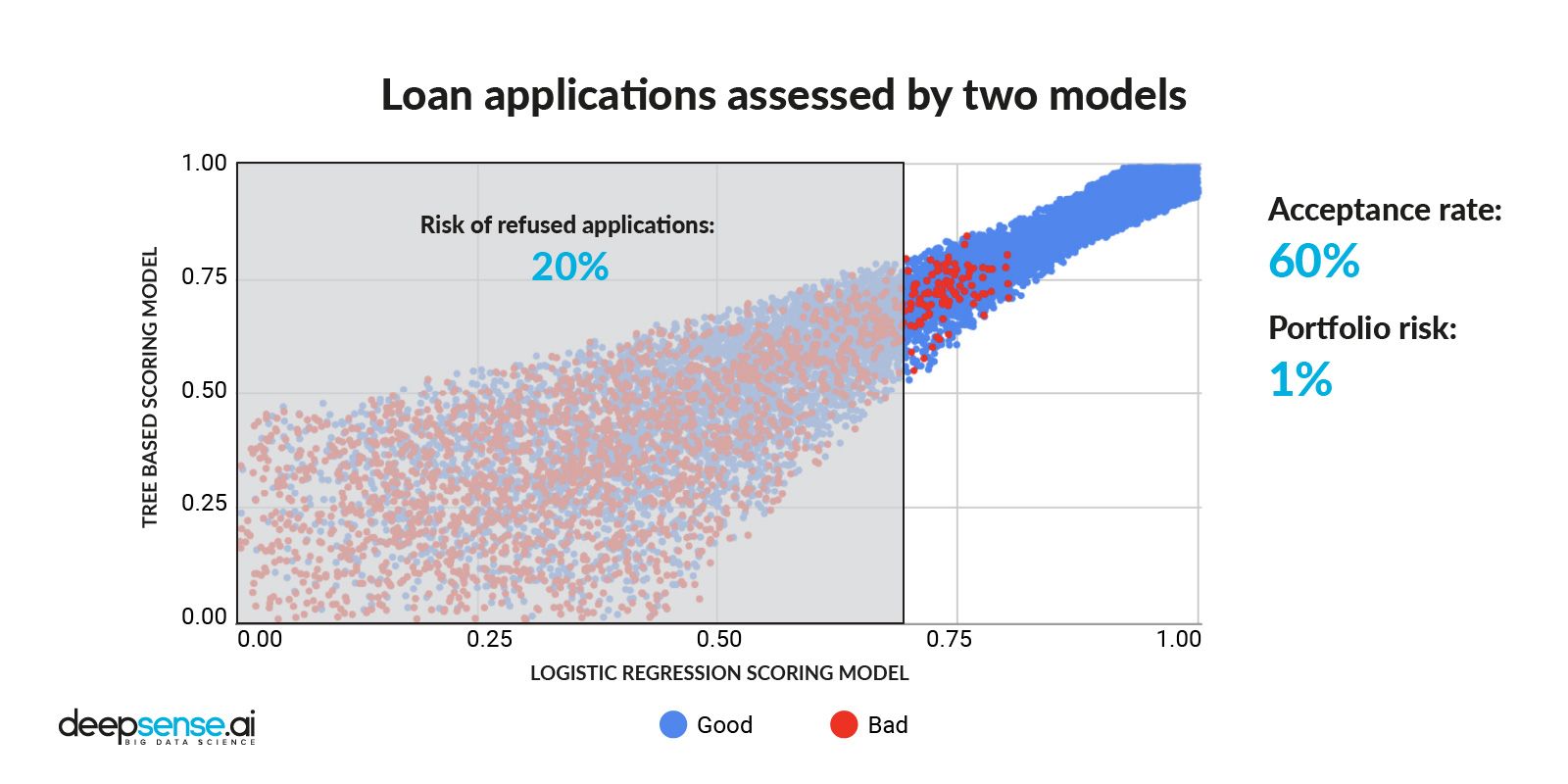
Initial credit application split (acceptance to portfolio risk)
If we decrease the threshold by a couple of points, the acceptance level hits 70% while the risk jumps to 1,5%

Credit applications’ split after lowering the threshold
We next applied a threshold for an ML model, allowing us to get an acceptance percentage to the original level (60%) while bringing the risk down to 0,75% that is by 25% lower than the risk level resulting from only traditional approach.
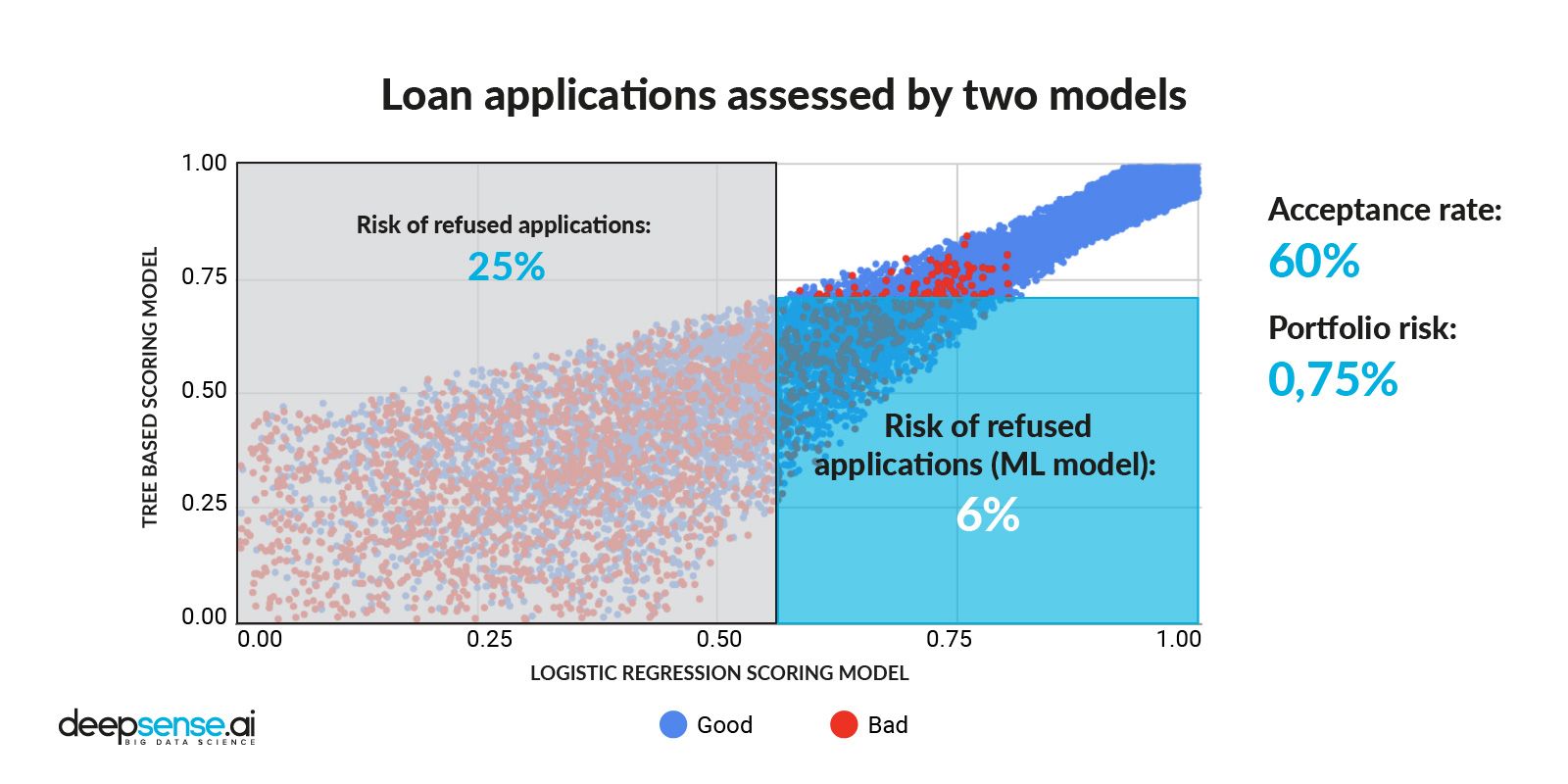
Credit applications’ split after applying Machine Learning
Summary
Machine learning is often seen as difficult to apply in banking due to the sheer amount of regulation the industry faces. The facts don’t necessarily back this up. ML is successfully used in numerous, heavily regulated industries. The example above is just one more example of how. Thanks to this innovative approach it is possible to increase the sustainability of the loans sector and make loans even more affordable to bank customers. There’s nothing artificial about that kind of intelligence.
