AI has become a powerful force in computer vision and it has unleashed tangible business opportunities for 2D visual data such as images and videos. Applying AI can bring tremendous results in a number of fields. To learn more about this exciting area, read our overview of 2D computer vision algorithms and applications.
Despite its popularity, there is nothing inherent to 2D imagery that makes it uniquely suitable for AI application. In fact, artificial intelligence systems can analyze various forms of information, including volumetric data. In spite of the increasing number of companies already using 3D data gathered by lidar or 3D cameras, AI applications aren’t the mainstream in their industries.
In this post, we describe how to leverage 3D data across multiple industries with the use of AI. Later in the article we’ll have a closer look at the nuts and bolts of the technology and we’ll aslo show what it takes to apply AI to 3D data. At the end of the post, you’ll also find an interactive demo to play with.
In the 3D world, there is no Swiss Army Knife
3D data is what we call volumetric information. The most common types include:
2.5D data, including information on depth or the distance to visible objects, but no volumetric information of what’s hidden behind them. Lidar data is an example.
3D data, with full volumetric information. Examples include MRI scans or objects rendered with computer graphics.
4D data, where volumetric information is captured as a sequence, and the outcome is a recording where one can go back and forth in time to see the changes occurring in the volume. We refer to this as 3D + time, which we can treat as the 4th dimension. Such representation enables us to visualize and model dynamic 3D processes, which is especially useful in medical applications such as respiratory or cardiac monitoring.
There are also multiple data representations. These include a compound of 2D images along the normal axis, sparse Point Cloud representation and voxelized representation. Such data could have additional channels, like reflectance in every point of a lidar’s view.
Depending on the business need, there can be different objectives for using AI: object detection and classification, semantic segmentation, instance segmentation and movement parameterization, to name a few. Moreover, every setup has its own characteristics and limitations that should be addressed with a dedicated approach (or, in the case of artificial neural networks, with a sophisticated and thoroughly designed architecture). These are the main reasons our clients come to us, and to take advantage of our experience in the field. We are responsible for delivering the AI part of specific projects, even though the majority of their competencies are built in-house.
Let us have a closer look at a few examples
1. Autonomous driving
Task: 3D object detection and classification,
Data: 2.5 Point clouds captured with a lidar: sparse data, big distances between points
Autonomous driving data are very sparse because:
the distances between objects in outdoor environments are significant
In the majority of cases lidar rays from the front and rear of the car don’t return to lidar, since there are no objects to reflect them.
The resolution of objects gets worse the further they are from the laser scanner. Due to the angular expansion of the beam it’s impossible to determine the precise shape of objects that are far away.
For autonomous driving, we needed a system that can take advantage of data sparsity to infer 3D bounding boxes around objects. One such network is the part-aware and aggregation neural network i.e. Part-A2 net (https://arxiv.org/abs/1907.03670). This is a two-stage network that uses the high separability of objects, which functions as segmentation information.
In the first stage, the network estimates the position of foreground points of objects inside bounding boxes generated by an anchor-based or anchor-free scheme. Then, in the second stage, the network aggregates local information for box refinement and class estimation. The network output is shown below, with the colors of points in bounding boxes showing their relative location as perceived by the Part-A2 net.
Data: Point clouds, sparse data, relatively small distances between points
A different setup is called for in mapping indoor environments, such as we do with instance segmentation of objects in office space or shops (see this dataset for better intuition: S3DIS dataset). Here we employ a relatively high-density representation of a point cloud and BoNet architecture.
In this case the space is divided into a 1- x 1- x 1-meter cubic grid. In each cube, a few thousand points are sampled for further processing. In an autonomous driving scenario, such a grid division would make little sense given the sheer number of cubes produced, many of which are empty and only a few of which contain any relevant information.
The network produces semantic segmentation masks as well as bounding boxes. The inference is a two-stage process. The first produces a global feature vector to predict a fixed number of bounding boxes. It also tallies scores to indicate whether some of the predicted classes are inside those boxes. The point-level and global features derived in the first stage are then used to predict a point-level binary mask with the class assignment. The pictures below show a typical scene with the segmentation masks.
An example from the S3DIS dataset. From left: input image, semantic segmentation labels, instance segmentation labels
3. Medical diagnosis
Task: 3D Semantic segmentation
Data: Stacked 2D images, dense data, small distance between images
This is a highly controlled setup, where all 2D images are carefully and densely stacked together. Such a representation can be treated as a natural extension of a 2D setup. In such cases, modifying existing 2D approaches will deliver satisfactory results.
An example of a modified 2D approach is the 3D U-Net (https://arxiv.org/abs/1606.06650), where all 2D operations for a classical U-Net are replaced by their 3D counterparts. If you want to know more about AI in medicine, check out how it can be used to help with COVID-19 diagnosis and other challenges.
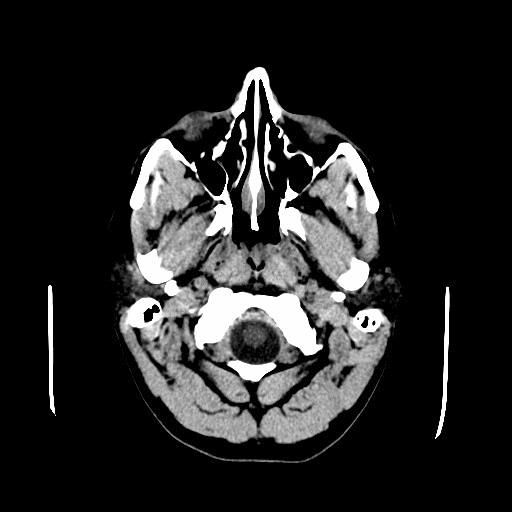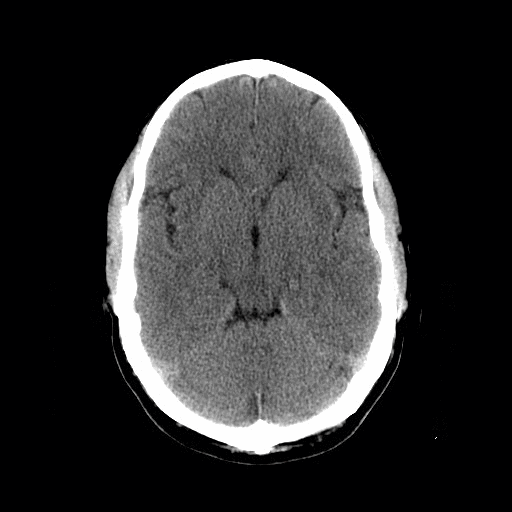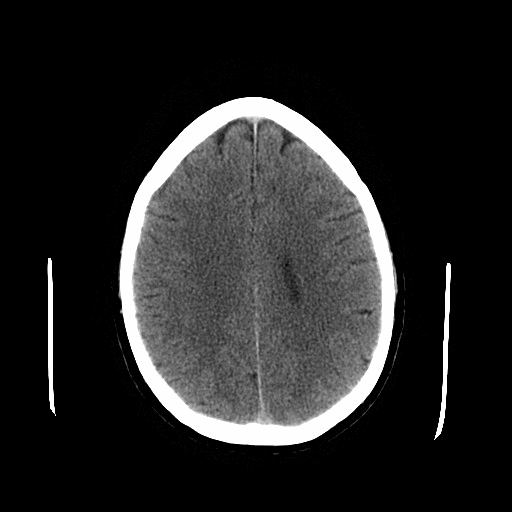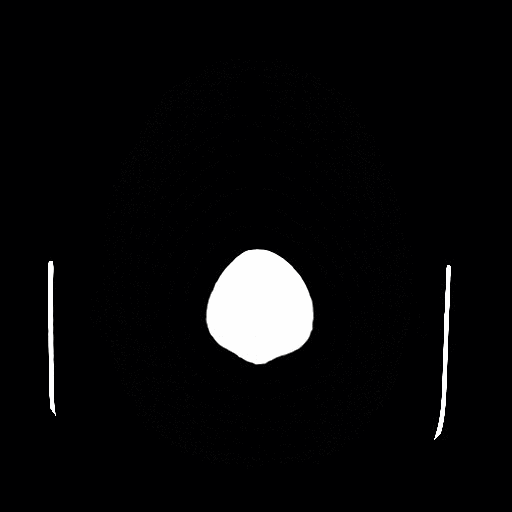
Source: Head CT scan
4. A 3D-enhanced 2D approach
There is also another case, where luckily, it can be relatively straightforward to apply expertise and technology developed for 2D cases in 3D applications. One such scenario is where there are 2D labels available, but the data and the inference products are in 3D. Another is when 3D information can play a supportive role.
In such a case, a depth map produced by 3D cameras can be treated as an additional image channel beyond regular RGB colors. Such additional information increases the sensitivity of neural networks to edge detection and thus yield better object boundaries.
Source: Azure Kinect DK depth camera
Examples of the projects we have delivered in such a setup include:
Defect detection based on 2D and 3D images.
We developed an AI system for a tire manufacturer to detect diverse types of defects. 3D data played a crucial role as it allowed for ultra-precise detection of submillimeter-size bubbles and scratches.
Object detection in a factory
We designed a system to detect and segment industrial assets in a chemical facility that had been thoroughly scanned with high resolution laser scanners. Combining 2D and 3D information allowed us to digitize the topology of the installation and its pipe system.
3D data needs a mix of competencies
At deepsense.ai, we have a team of data scientists and software engineers handling the algorithmic, visualization, and integration capabilities. Our teams are set up to flexibly adapt to specific business cases and provide tailor-made AI solutions. The solutions they produce are an alternative to pre-made, off-the-shelf products, which often prove too rigid and constrained; they fail once user expectations deviate from the assumptions of their designers.
Processing and visualizing data in near real time with appropriate user experience is no piece of cake. Doing so requires a tough balancing act, including
combining specific business needs, technical limitations resulting from huge data loads and the need to support multiple platforms.
It is always easier to discuss based on an example. Next section shows what it takes to develop an object detection system for autonomous vehicles with outputs accessible from a web browser. The goal is to predict bounding boxes of 3 different classes: car, pedestrian and cyclist, 360 degrees around the car. Such a project can be divided into 4 interconnected components: data processing, algorithms, visualizations and deployment.
Data preprocessing
In our example, we use the KITTI and A2D2 datasets, two common datasets for autonomous driving, and ones our R&D hub rely on heavily. In both datasets, we use data from spinning lidars for inference and cameras for visualization purposes.
Lidars and cameras work independently, capturing data at different rates. To obtain a full picture, all data have to be mapped to a common coordinate system and adjusted for time. This is no easy task. As lidars are constantly spinning, each point is captured at a different time, while simultaneously the position and rotation of the car in relation to world coordinates is changing. Meanwhile, the precise location and angle of the car is not known perfectly due to limitations of geolocation systems such as GPS. These difficulties make it extremely difficult to precisely and stably determine the absolute positions of objects around you (SLAM can be used to tackle some of the problems).
Fortunately, absolute positioning of objects around the vehicle is not always required.
Algorithms
There are a vast number of approaches when it comes to 3D data. However, factors such as the length to and between objects and high sparsity will play an essential role in which algorithm we ultimately settle on. As in the first example above, we used Part-A2 net.
Deployment
We have relied on a complete, in-house solution for visualization, data handling, and UI. We have used expertise in the Unity engine to develop a cross-platform, graphically rich and fully flexible solution. In terms of a platform, we opted for maximum availability, which can be satisfied by a popular web browser like Chrome or Mozilla and WebGL as Unity’s compilation platform.
Visualization/UI
WebGL, while very comfortable for the user, disables drive access and advanced GPU features, limits available RAM to 2GB and processing to a single thread. Additionally, while standalone solutions in Unity may rely on existing libraries for point cloud visualization, making it possible to visualize hundreds of millions of points (thanks to advanced GPU features), this is not the case in WebGL.
Therefore, we have developed an in-house visualization solution enabling real-time, in-browser visualization of up to 70 mln points. Give it a try!
Such visualization could be tailored to the company’s specific needs. In a recent project, we took a different approach: we used AR glasses in visualizing a factory in all its complexity. This enabled our client to reach next level user experience and see the factory in a whole new light.
Summary
We hope that this post has shed some light on how AI can be used with 3D data. If you have a particular 3D use case in mind or you are just curious about the potential for AI solutions in your field, please reach out to us. We’ll be happy to share our experience and discuss potential ways we can help you apply the power of artificial intelligence in your business. Please drop us an email at contact@deepsense.ai.




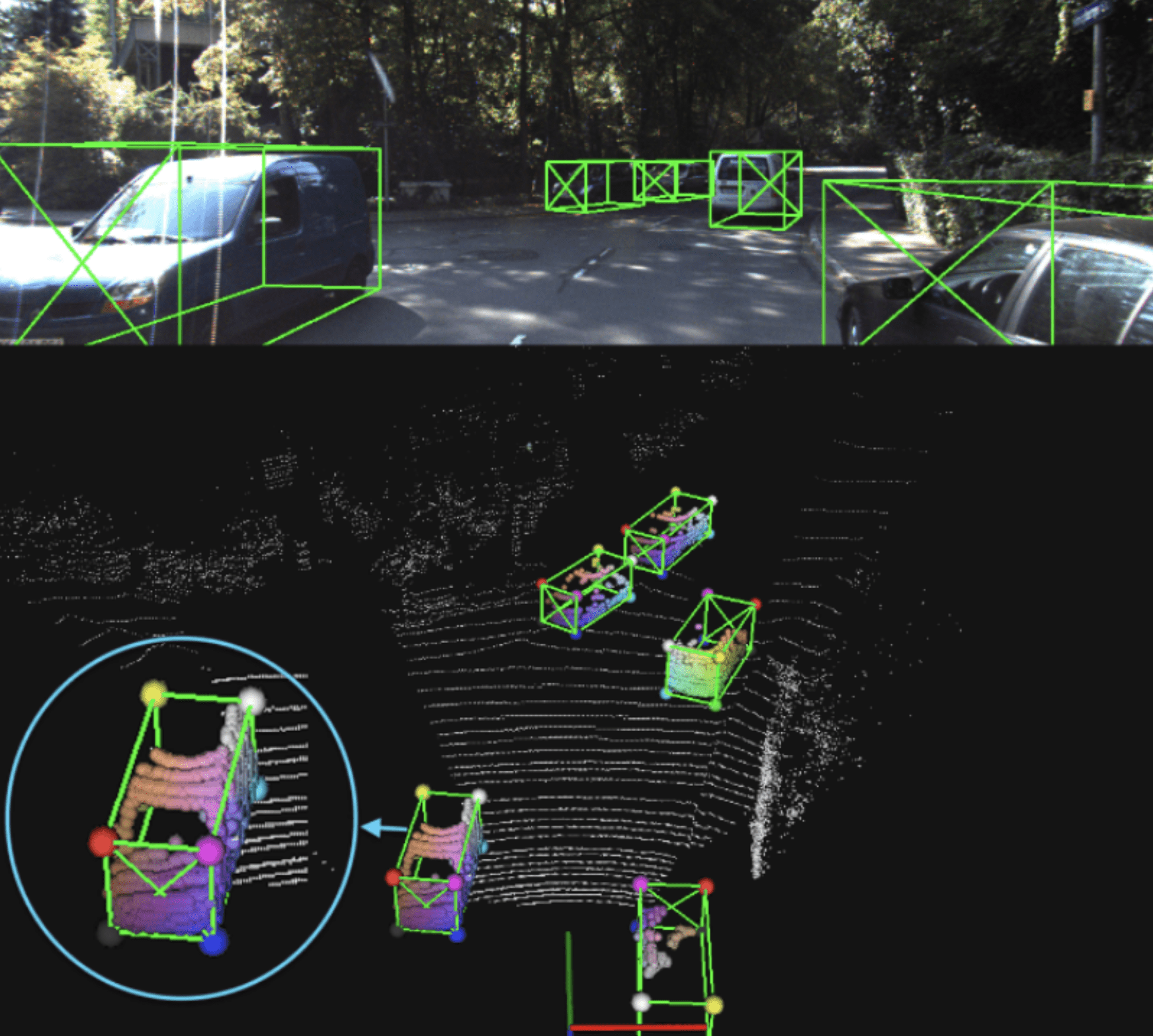 Source of image: From Points to Parts: 3D Object Detection from Point Cloud with Part-aware and Part-aggregation Network
Source of image: From Points to Parts: 3D Object Detection from Point Cloud with Part-aware and Part-aggregation Network