Table of contents
In our previous post, we gave you an overview of the differences between Keras and PyTorch, aiming to help you pick the framework that’s better suited to your needs. Now, it’s time for a trial by combat. We’re going to pit Keras and PyTorch against each other, showing their strengths and weaknesses in action. We present a real problem, a matter of life-and-death: distinguishing Aliens from Predators!
Table of contents

We perform image classification, one of the computer vision tasks deep learning shines at. As training from scratch is unfeasible in most cases (as it is very data hungry), we perform transfer learning using ResNet-50 pre-trained on ImageNet. We get as practical as possible, to show both the conceptual differences and conventions.
At the same time we keep the code fairly minimal, to make it clear and easy to read and reuse. See notebooks on GitHub, Kaggle kernels or Neptune versions with fancy charts.
Wait, what’s transfer learning? And why ResNet-50?
In practice, very few people train an entire Convolutional Network from scratch (with random initialization), because it is relatively rare to have a dataset of sufficient size. Instead, it is common to pretrain a ConvNet on a very large dataset (e.g. ImageNet, which contains 1.2 million images with 1000 categories), and then use the ConvNet either as an initialization or a fixed feature extractor for the task of interest.– Andrej Karpathy (Transfer Learning – CS231n Convolutional Neural Networks for Visual Recognition)
Transfer learning is a process of making tiny adjustments to a network trained on a given task to perform another, similar task. In our case we work with the ResNet-50 model trained to classify images from the ImageNet dataset. It is enough to learn a lot of textures and patterns that may be useful in other visual tasks, even as alien as this Alien vs. Predator case. That way, we use much less computing power to achieve much better result. In our case we do it the simplest way:
- keep the pre-trained convolutional layers (so-called feature extractor), with their weights frozen,
- remove the original dense layers, and replace them with brand-new dense layers we will use for training.
So, which network should be chosen as the feature extractor?
ResNet-50 is a popular model for ImageNet image classification (AlexNet, VGG, GoogLeNet, Inception, Xception are other popular models). It is a 50-layer deep neural network architecture based on residual connections, which are connections that add modifications with each layer, rather than completely changing the signal.
ResNet was the state-of-the-art on ImageNet in 2015. Since then, newer architectures with higher scores on ImageNet have been invented. However, they are not necessarily better at generalizing to other datasets (see the Do Better ImageNet Models Transfer Better? arXiv paper). Ok, it’s time to dive into the code.
Let the match begin!
We do our Alien vs. Predator task in seven steps:
- Prepare the dataset
- Import dependencies
- Create data generators
- Create the network
- Train the model
- Save and load the model
- Make predictions on sample test images
We supplement this blog post with Python code in Jupyter Notebooks (Keras-ResNet50.ipynb, PyTorch-ResNet50.ipynb). This environment is more convenient for prototyping than bare scripts, as we can execute it cell by cell and peak into the output. All right, let’s go!
0. Prepare the dataset
We created a dataset by performing a Google Search with the words “alien” and “predator”. We saved JPG thumbnails (around 250×250 pixels) and manually filtered the results. Here are some examples:
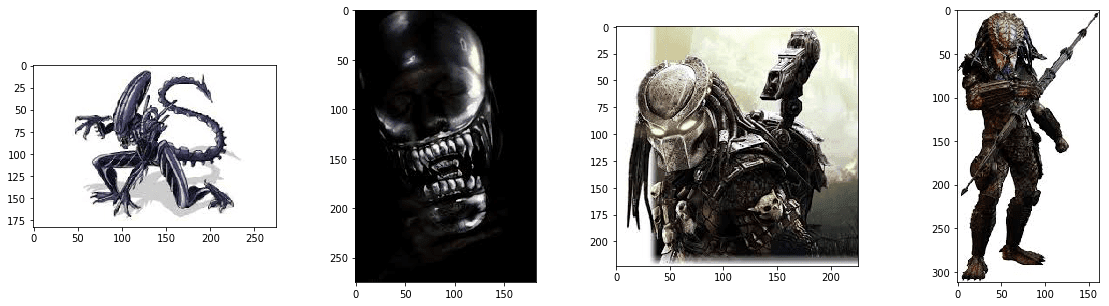
We split our data into two parts:
- Training data (347 samples per class) – used for training the network.
- Validation data (100 samples per class) – not used during the training, but needed in order to check the performance of the model on previously unseen data.
Keras requires the datasets to be organized in folders in the following way:
|-- train
|-- alien
|-- predator
|-- validation
|-- alien
|-- predator
If you want to see the process of organizing data into directories, check out the data_prep.ipynb file. You can download the dataset from Kaggle.
1. Import dependencies
First, the technical ities. We assume that you have Python 3.5+, Keras 2.2.2 (with TensorFlow 1.10.1 backend) and PyTorch 0.4.1. Check out the requirements.txt file in the repo. So, first, we need to import the required modules. We separate the code in Keras, PyTorch and common (one required in both).
COMMON
import numpy as np import matplotlib.pyplot as plt from PIL import Image %matplotlib inline
KERAS
import keras from keras.preprocessing.image import ImageDataGenerator from keras.applications import ResNet50 from keras.applications.resnet50 import preprocess_input from keras import Model, layers from keras.models import load_model, model_from_json
PYTORCH
import torch from torchvision import datasets, models, transforms import torch.nn as nn from torch.nn import functional as F import torch.optim as optim
We can check the frameworks’ versions by typing keras.__version__ and torch.__version__, respectively.
2. Create data generators
Normally, the images can’t all be loaded at once, as doing so would be too much for the memory to handle. At the same time, we want to benefit from the GPU’s performance boost by processing a few images at once. So we load images in batches (e.g. 32 images at once) using data generators. Each pass through the whole dataset is called an epoch. We also use data generators for preprocessing: we resize and normalize images to make them as ResNet-50 likes them (224 x 224 px, with scaled color channels). And last but not least, we use data generators to randomly perturb images on the fly:
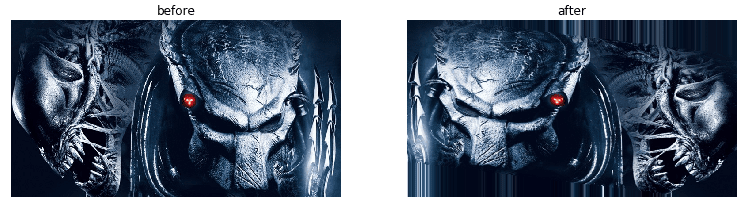
Performing such changes is called data augmentation. We use it to show a neural network which kinds of transformations don’t matter. Or, to put it another way, we train on a potentially infinite dataset by generating new images based on the original dataset. Almost all visual tasks benefit, to varying degrees, from data augmentation for training. For more info about data augmentation, see as applied to plankton photos or how to use it in Keras. In our case, we randomly shear, zoom and horizontally flip our aliens and predators.
Here we create generators that:
- load data from folders,
- normalize data (both train and validation),
- augment data (train only).
KERAS
train_datagen = ImageDataGenerator(
shear_range=10,
zoom_range=0.2,
horizontal_flip=True,
preprocessing_function=preprocess_input)
train_generator = train_datagen.flow_from_directory(
'data/train',
batch_size=32,
class_mode='binary',
target_size=(224,224))
validation_datagen = ImageDataGenerator(
preprocessing_function=preprocess_input)
validation_generator = validation_datagen.flow_from_directory(
'data/validation',
shuffle=False,
class_mode='binary',
target_size=(224,224))
PYTORCH
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
data_transforms = {
'train':
transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomAffine(0, shear=10, scale=(0.8,1.2)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize]),
'validation':
transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
normalize])}
image_datasets = {
'train':
datasets.ImageFolder('data/train', data_transforms['train']),
'validation':
datasets.ImageFolder('data/validation', data_transforms['validation'])}
dataloaders = {
'train':
torch.utils.data.DataLoader(
image_datasets['train'],
batch_size=32,
shuffle=True,
num_workers=4),
'validation':
torch.utils.data.DataLoader(
image_datasets['validation'],
batch_size=32,
shuffle=False,
num_workers=4)}
In Keras, you get built-in augmentations and preprocess_input method normalizing images put to ResNet-50, but you have no control over their order. In PyTorch, you have to normalize images manually, but you can arrange augmentations in any way you like.
There are also other nuances: for example, Keras by default fills the rest of the augmented image with the border pixels (as you can see in the picture above) whereas PyTorch leaves it black. Whenever one framework deals with your task much better than the other, take a closer look to see if they perform preprocessing identically; we bet they don’t.
3. Create the network
The next step is to import a pre-trained ResNet-50 model, which is a breeze in both cases. We freeze all the ResNet-50’s convolutional layers, and only train the last two fully connected (dense) layers. As our classification task has only 2 classes (compared to 1000 classes of ImageNet), we need to adjust the last layer. Here we:
- load pre-trained network, cut off its head and freeze its weights,
- add custom dense layers (we pick 128 neurons for the hidden layer),
- set the optimizer and loss function.
KERAS
conv_base = ResNet50(include_top=False,
weights='imagenet')
for layer in conv_base.layers:
layer.trainable = False
x = conv_base.output
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(128, activation='relu')(x)
predictions = layers.Dense(2, activation='softmax')(x)
model = Model(conv_base.input, predictions)
optimizer = keras.optimizers.Adam()
model.compile(loss='sparse_categorical_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
PYTORCH
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = models.resnet50(pretrained=True).to(device)
for param in model.parameters():
param.requires_grad = False
model.fc = nn.Sequential(
nn.Linear(2048, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 2)).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.fc.parameters())</pre>
<!-- /wp:preformatted -->
We load the ResNet-50 from both Keras and PyTorch without any effort. They also offer many other well-known pre-trained architectures: see Keras’ model zoo and PyTorch’s model zoo. So, what are the differences?
In Keras we may import only the feature-extracting layers, without loading extraneous data (include_top=False). We then create a model in a functional way, using the base model’s inputs and outputs. Then we use model.compile(…) to bake into it the loss function, optimizer and other metrics. In PyTorch, the model is a Python object. In the case of models.resnet50, dense layers are stored in model.fc attribute. We overwrite them. The loss function and optimizers are separate objects. For the optimizer, we need to explicitly pass a list of parameters we want it to update.

In PyTorch, we should explicitly specify what we want to load to the GPU using .to(device) method. We have to write it each time we intend to put an object on the GPU, if available. Well… Layer freezing works in a similar way.
However, in The Batch Normalization layer of Keras is broken (as of the current version; thx Przemysław Pobrotyn for bringing this issue). That is – some layers get modified anyway, even with trainable = False. Keras and PyTorch deal with log-loss in a different way.
In Keras, a network predicts probabilities (has a built-in softmax function), and its built-in cost functions assume they work with probabilities.
In PyTorch we have more freedom, but the preferred way is to return logits. This is done for numerical reasons, performing softmax then log-loss means doing unnecessary log(exp(x)) operations. So, instead of using softmax, we use LogSoftmax (and NLLLoss) or combine them into one nn.CrossEntropyLoss loss function.
4. Train the model
OK, ResNet is loaded, so let’s get ready to space rumble!

Now, we proceed to the most important step – model training. We need to pass data, calculate the loss function and modify network weights accordingly. While we already had some differences between Keras and PyTorch in data augmentation, the length of code was similar. For training… the difference is massive. Let’s see how it works! Here we:
- train the model,
- measure the loss function (log-loss) and accuracy for both training and validation sets.
KERAS
history = model.fit_generator(
generator=train_generator,
epochs=3,
validation_data=validation_generator)
PYTORCH
def train_model(model, criterion, optimizer, num_epochs=3):
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch+1, num_epochs))
print('-' * 10)
for phase in ['train', 'validation']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, preds = torch.max(outputs, 1)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(image_datasets[phase])
epoch_acc = running_corrects.double() / len(image_datasets[phase])
print('{} loss: {:.4f}, acc: {:.4f}'.format(phase,
epoch_loss,
epoch_acc))
return model
model_trained = train_model(model, criterion, optimizer, num_epochs=3)
In Keras, the model.fit_generator performs the training… and that’s it! Training in Keras is just that convenient. And as you can find in the notebook, Keras also gives us a progress bar and a timing function for free. But if you want to do anything nonstandard, then the pain begins…

PyTorch is on the other pole. Everything is explicit here. You need more lines to construct the basic training, but you can freely change and customize all you want. Let’s shift gears and dissect the PyTorch training code. We have nested loops, iterating over:
- epochs,
- training and validation phases,
- batches.
The epoch loop does nothing but repeat the code inside. The training and validation phases are done for three reasons:
- Some special layers, like batch normalization (present in ResNet-50) and dropout (absent in ResNet-50), work differently during training and validation. We set their behavior by model.train() and model.eval(), respectively.
- We use different images for training and for validation, of course.
- The most important and least surprising thing: we train the network during training only. The magic commands optimizer.zero_grad(), loss.backward() and optimizer.step() (in this order) do the job. If you know what backpropagation is, you appreciate their elegance.
We take care of computing the epoch losses and prints ourselves.
5. Save and load the model
Saving
Once our network is trained, often with high computational and time costs, it’s good to keep it for later. Broadly, there are two types of savings:
- saving the whole model architecture and trained weights (and the optimizer state) to a file,
- saving the trained weights to a file (keeping the model architecture in the code). It’s up to you which way you choose.
- save the model.
Here we:
KERAS
# architecture and weights to HDF5
model.save('models/keras/model.h5')
# architecture to JSON, weights to HDF5
model.save_weights('models/keras/weights.h5')
with open('models/keras/architecture.json', 'w') as f:
f.write(model.to_json())
PYTORCH
torch.save(model_trained.state_dict(),'models/pytorch/weights.h5')
torch.save(model_trained.state_dict(),'models/pytorch/weights.h5')

One line of code is enough in both frameworks. In Keras you can either save everything to a HDF5 file or save the weights to HDF5 and the architecture to a readable json file. By the way: you can then load the model and run it in the browser. Currently, PyTorch creators recommend saving the weights only. They discourage saving the whole model because the API is still evolving.
Loading
Loading models is as simple as saving. You should just remember which saving method you chose and the file paths. Here we:
- load the model.
KERAS
# architecture and weights from HDF5
model = load_model('models/keras/model.h5')
# architecture from JSON, weights from HDF5
with open('models/keras/architecture.json') as f:
model = model_from_json(f.read())
model.load_weights('models/keras/weights.h5')
PYTORCH
model = models.resnet50(pretrained=False).to(device)
model.fc = nn.Sequential(
nn.Linear(2048, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 2)).to(device)
model.load_state_dict(torch.load('models/pytorch/weights.h5'))
In Keras we can load a model from a JSON file, instead of creating it in Python (at least when we don’t use custom layers). This kind of serialization makes it convenient for transfering models.
PyTorch can use any Python code. So pretty much we have to re-create a model in Python. Loading model weights is similar in both frameworks.
6. Make predictions on sample test images
All right, it’s finally time to make some predictions! To fairly check the quality of our solution, we ask the model to predict the type of monsters from images not used for training. We can use the validation set, or any other image. Here we:
- load and preprocess test images,
- predict image categories,
- show images and predictions.
COMMON
validation_img_paths = ["data/validation/alien/11.jpg",
"data/validation/alien/22.jpg",
"data/validation/predator/33.jpg"]
img_list = [Image.open(img_path) for img_path in validation_img_paths]
KERAS
validation_batch = np.stack([preprocess_input(np.array(img.resize((img_size, img_size))))
for img in img_list])
pred_probs = model.predict(validation_batch)
PYTORCH
validation_batch = torch.stack([data_transforms['validation'](img).to(device)
for img in img_list])
pred_logits_tensor = model(validation_batch)
pred_probs = F.softmax(pred_logits_tensor, dim=1).cpu().data.numpy()
COMMON
fig, axs = plt.subplots(1, len(img_list), figsize=(20, 5))
for i, img in enumerate(img_list):
ax = axs[i]
ax.axis('off')
ax.set_title("{:.0f}% Alien, {:.0f}% Predator".format(100*pred_probs[i,0],
100*pred_probs[i,1]))
ax.imshow(img)
Prediction, like training, works in batches (here we use a batch of 3; though we could surely also use a batch of 1). In both Keras and PyTorch we need to load and preprocess the data. A rookie mistake is to forget about the preprocessing step (including color scaling). It is likely to work, but result in worse predictions (since it effectively sees the same shapes but with different colors and contrasts).
In PyTorch there are two more steps, as we need to:
- convert logits to probabilities,
- transfer data to the CPU and convert to NumPy (fortunately, the error messages are fairly clear when we forget this step).
And this is what we get:
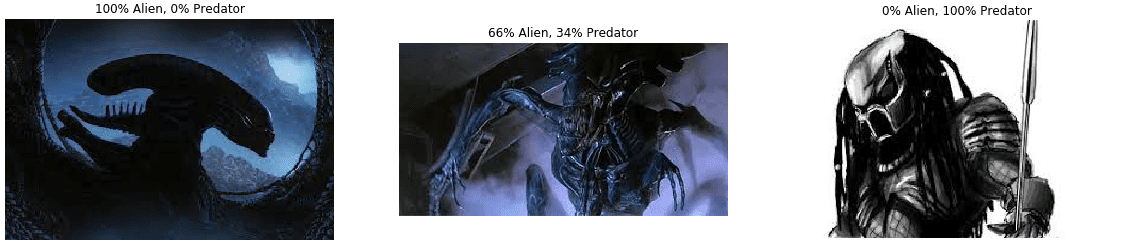
It works!
And how about other images? If you can’t come up with anything (or anyone) else, try using photos of your co-workers. 🙂
Conclusion
As you can see, Keras and PyTorch differ significantly in terms of how standard deep learning models are defined, modified, trained, evaluated, and exported. For some parts it’s purely about different API conventions, while for others fundamental differences between levels of abstraction are involved.
Keras operates on a much higher level of abstraction. It is much more plug&play, and typically more succinct, but at the cost of flexibility.
PyTorch provides more explicit and detailed code. In most cases it means debuggable and flexible code, with only small overhead. Yet, training is way-more verbose in PyTorch. It hurts, but at times provides a lot of flexibility.
Transfer learning is a big topic. Try tweaking your parameters (e.g. dense layers, optimizer, learning rate, augmentation) or choose a different network architecture.
Have you tried transfer learning for image recognition? Consider the list below for some inspiration:
- Chihuahua vs. muffin, sheepdog vs. mop, shrew vs. kiwi (already serves as an interesting benchmark for computer vision)
- Original images vs. photoshopped ones
- Artichoke vs. broccoli vs. cauliflower
- Zerg vs. Protoss vs. Orc vs. Elf
- Meme or not meme
- Is it a picture of a bird?
- Is it huggable?
Pick Keras or PyTorch, choose a dataset and let us know how it went in the comments section below 🙂





