Table of contents
The lives of brave firemen are threatened during dangerous emergency missions while they try to save other people and their property. In this post I would like to share my experiences and winning strategy for the AAIA’15 Data Mining Competition: Tagging Firefighter Activities at a Fire Scene, in which I took first place.

The competition was organized jointly by the University of Warsaw and the Main School of Fire Service, in Warsaw, Poland. It lasted over 3 months during which 79 contestants submitted a total of 1,840 proposals with solutions on the competition’s hosting platform Knowledge Pit.
I particularly enjoy competitions with a potentially big impact – when something more than only a high accuracy score is at stake. This competition definitely had a flavor of this – the participants were asked to contribute toward the safety of firefighters on the scene during an emergency mission.
The challenge
It is certainly helpful for decision making during an emergency when you know what particular activity the members of a rescue team are currently engaged in. This was the goal of the competition – develop a model that recognizes what activity a fireman is performing based on sensory data from his body movements and a collection of statistics monitoring his vital functions. Actually, we are facing two dependent multiclass classification problems. The first class is the main posture of the fireman and the second one is his particular action. Here is a sample of the data the contestants were given:
| posture | action | avg-ecg1 | … | ll-acc-x | ll-acc-y | … | torso-gyro-z |
| stooping | manipulating | -0.03 | … | -6.98 | 10.41 | … | 28.49 |
| standing | signal water first | -0.04 | … | -9.41 | 0.11 | … | 63.84 |
| moving | running | -0.04 | … | -8.75 | 3.81 | … | -52.92 |
| crawling | searching | -0.03 | … | -36.61 | 2.74 | … | -134.26 |
| stooping | manipulating | -0.04 | … | -3.00 | 2.23 | … | -7.21 |
The first two columns present the two class attributes: the posture and the main action of the fireman. Each activity is described by ca. 2 second-time series of sensory data from accelerometers and gyroscopes and certain statistics on fireman’s vital functions. In total, there are 42 such statistics as well as 42 different time series. Moreover, as usual, you are given two datasets: “train” and “test”. In the training data, you are given instances along with labels of activities, just as exemplified in the table above. In the test data, the labels are not present and you are asked to design a model for automatic tagging of those activities. To select the best performing approach from participants’ proposals, the performance of a given model on the test set was taken into account (in terms of an evaluation metric discussed below). You can find more information on the competition at its hosting platform.
The number of possible activities is restricted to the set of labels by the competition organizers. There are five labels in the first class, and 16 in the second one. Moreover, the labels are dependent. Let us see their joint distribution.
| crawling | crouching | moving | standing | stooping | |
| ladder down | 0 | 0 | 465 | 0 | 0 |
| ladder up | 0 | 0 | 476 | 0 | 0 |
| manipulating | 0 | 1764 | 331 | 2356 | 1898 |
| no action | 0 | 87 | 0 | 490 | 0 |
| nozzle usage | 0 | 492 | 0 | 443 | 0 |
| running | 0 | 0 | 4324 | 0 | 0 |
| searching | 459 | 0 | 0 | 0 | 0 |
| signal hose pullback | 0 | 0 | 0 | 98 | 0 |
| signal water first | 0 | 0 | 41 | 496 | 0 |
| signal water main | 0 | 46 | 0 | 405 | 0 |
| signal water stop | 0 | 0 | 0 | 277 | 0 |
| stairs down | 0 | 0 | 644 | 0 | 0 |
| stairs up | 0 | 0 | 1157 | 0 | 0 |
| striking | 0 | 0 | 0 | 1022 | 0 |
| throwing hose | 0 | 0 | 0 | 234 | 930 |
| walking | 0 | 0 | 1064 | 0 | 0 |
For example, there are 4,324 instances in the data where a fireman is moving and running, and 234 instances where a fireman is standing and throwing a hose. Surely, there are many other activities that someone from the rescue team can engage in, however, the dataset was restricted to this particular subset. It may come as a big disappointment, but there were no “saving cat” label. As such, the competition was set up as a standard supervised learning task: we are given a training set of activities along with their tags. In the test set, we are to tag activities based on what we’ve learned from the examples in the training set.
Another thing to note is the fact that the distribution of labels is fairly unbalanced. For instance, a fireman is about four times more likely to be running than throwing a hose. This should be carefully considered, especially in the context of the evaluation metric adopted in the competition.
The chosen metric was balanced accuracy. It is defined in the following way. First, for a given label we define accuracy of predictions
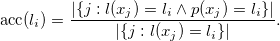
Next, the balanced accuracy score for class C with L labels is equal to the average accuracy among its labels
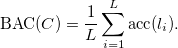
Finally, since we have two dependent class attributes, we compute a weighted average of balanced accuracy scores for posture and action classes:
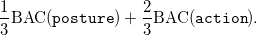
A higher weight is attached to the accuracy of classification of the more granular class action.
Overview of the solution
The approach to the task boils down to an extensive feature engineering step for time series data, before learning a set of classifiers. Along the way, there are a couple of interesting details to discuss. Since the final solution consisted of three slightly different Random Forest models that do not differ too much, I’ll describe just one of them.
Classification with two dependent class attributes
One of the interesting aspects of the challenge is the fact that we need to predict two dependent classes. In my approach, I performed a stepwise classification. In the first step, I predict the main posture of a fireman. In the second step, the particular activity is predicted based on the training set and the predicted label from the first step. Thanks to this approach, you can capture the hierarchical dependency between labels. Naturally, there are a number of other ways to deal with the two-class tagging problem. For instance, one could train two independent classifiers or concatenate the two labels. However, the approach of chaining two classifiers yielded better results in my case.
Drift between training and test data distribution
Another issue that came with the data was the fact that the activities in training and test set were performed by different firemen. This posed a real challenge. An important part of successful participation in any data mining competition is that you are able to set-up a local evaluation framework that is in-line with the one employed in the contest. Here, a natural solution would be to perform a stratified cross-validation over different firemen. However, no identifier of a fireman for a particular activity was provided. Hence, regardless of whether I liked it or not, I had to rely predominantly on preliminary evaluation scores that were based on 10% of the data during the competition (the final evaluation was done on the other 90% of test data). Of course, this was a problem not only for me but also for all the other contestants. As I talked to them at a conference workshop following the competition, they also relied mainly on preliminary evaluation results, as the evaluation on the training data yielded far too optimistic scores.
Feature engineering
The main effort during the competition was devoted to the extraction of interesting features describing the underlying time series (called signals). There are a couple of basic statistics that you can derive from the signal: mean, standard deviation, skewness, kurtosis, quantiles. I derived quantiles on a relatively rich grid ranging from 0.01, 0.05, 0.1, …, 0.95, 0.99. Because some of the activities are periodic, I thought that it would be useful to utilize some tools dedicated to that task. I processed each signal by Fourier transform as well as computed periodograms. From these transformed signals I once again extracted basic summary statistics. Another feature which is quite simple and proved to be useful in classification is correlation between signals. Intuitively, when you are running, the recordings of corresponding devices attached to your legs should be negatively correlated. Finally, I made some effort to identify peaks in the data. The idea is that, in case of performing different activities, e.g., running or striking, we can observe a different number of “peaks” in the signal. Peaks identification is a problem that is easy to state but hard to define mathematically. At the end, I ended up with a simple method that was based on counting chunks of a time series where it exceeds its mean by one or two standard deviations.
To battle the drift between training and test data, one should try to design generic (not subject-specific) features. For instance, the quantiles of distribution of acceleration are heavily dependent on a given person’s running pace and his/her motoric abilities. Presumably, these statistics are going to differ much from person to person. On the other hand, if you derive a correlation between acceleration recordings on left and right leg, this correlation may turn out to vary less between different firemen! This is a desired property of a feature, as the activities in test data were performed by a different set of people than those in the training set. Feature extraction was the most tedious part of the solution, but I believe a worthy one. I derived a set of almost 5,000 features describing each single activity. Now, the next step is to train a model based on these features that learns to distinguish between different activities.
Let’s vote
If a group of experts is to decide on an important matter, it is often the case, that collectively they can make a better decision. As each of them looks at the problem from a slightly different perspective, they can jointly arrive at a more refined judgment. This idea is brilliantly explored in the Random Forest algorithm, which is an ensemble of decision trees. A large number of trees are trained on diverse subsamples of data so that their joint prediction, made by majority voting, usually yields higher accuracy than each single individual model. I employed this model to solve the problem of activity recognition.
Another appealing property of Random Forest is that it has an inherent method of selecting relevant attributes. Having extracted a quite rich set of features, it is certainly the case that some of them are only mildly useful. I handed over the task of selecting the most relevant ones to the model itself.
As already mentioned in the introduction, the distribution of labels in the data was fairly unbalanced. Recall that our solutions are evaluated against a balanced accuracy evaluation metric. Doing a poor job predicting some label, yields the same penalty regardless of its distribution in the data. To account for this, each tree in the forest was trained on a stratified subsample of the data, where each label was present in an equal proportion. This preserved the forest from focusing too much on the most prevalent labels, and gave a major improvement in the score.

Summary
Summing up, the competition was a very exciting experience. I would like to thank all the participants, as they made the contest a great event. Also, I want to thank the organizing committee from the University of Warsaw and the Main School of Fire Service for providing such an interesting dataset and setting up the competition. The winning solution yielded a balanced accuracy of 84% which was enough to beat other contestants’ solutions. Certainly, there is still some room for improvement, yet we took a small step toward increasing the safety of firemen at a fire scene.
Jan Lasek (deepsense.ai Machine Learning Team)
About the Author:
Jan Lasek, Data Scientist at deepsense.ai, is also pursuing his PhD at the Institute of Computer Science, a part of the Polish Academy of Sciences. He graduated from Warsaw University where he studied both at the Faculty of Mathematics and the Faculty of Economic Sciences.