
Table of contents
Building maps to fit a crisis situation provides a challenge even when considering the impact of satellite imaging on modern cartography. Machine learning significantly reduces the time required to prepare an accurate map.
Table of contents
Crisis maps are often prepared by combining crowdsourced data, satellite and aerial imagery. Such mapping was widely used during the recent humanitarian crises brought about by the earthquake in Haiti and the floods in Pakistan in 2010.
Satellite mapping is way easier than traditional cartographic methods, but still, the main challenge is in recognizing particular objects in the image, like roads, buildings and landmarks. Getting up-to-date information about roadblocks and threats is even more essential. And that’s where machine learning-based solutions come into play.
The artificial cartographer
In this blog post we address the problem of satellite imagery semantic segmentation applied to building detection. Unlike many other approaches, we use only RGB color information and no multispectral wavebands.
Check out the demo:
1. Network architecture overview
A baseline fully-convolutional network uses a simple encoder-decoder framework to solve semantic segmentation tasks. It consists of only convolutional and pooling layers, without any fully connected layers. This allows it to make predictions on arbitrary-sized inputs. By propagating an image through several pooling layers, the resolution of feature maps is downsampled, which, due to information loss during pooling operations, results in low-resolution, coarse segmentation maps.
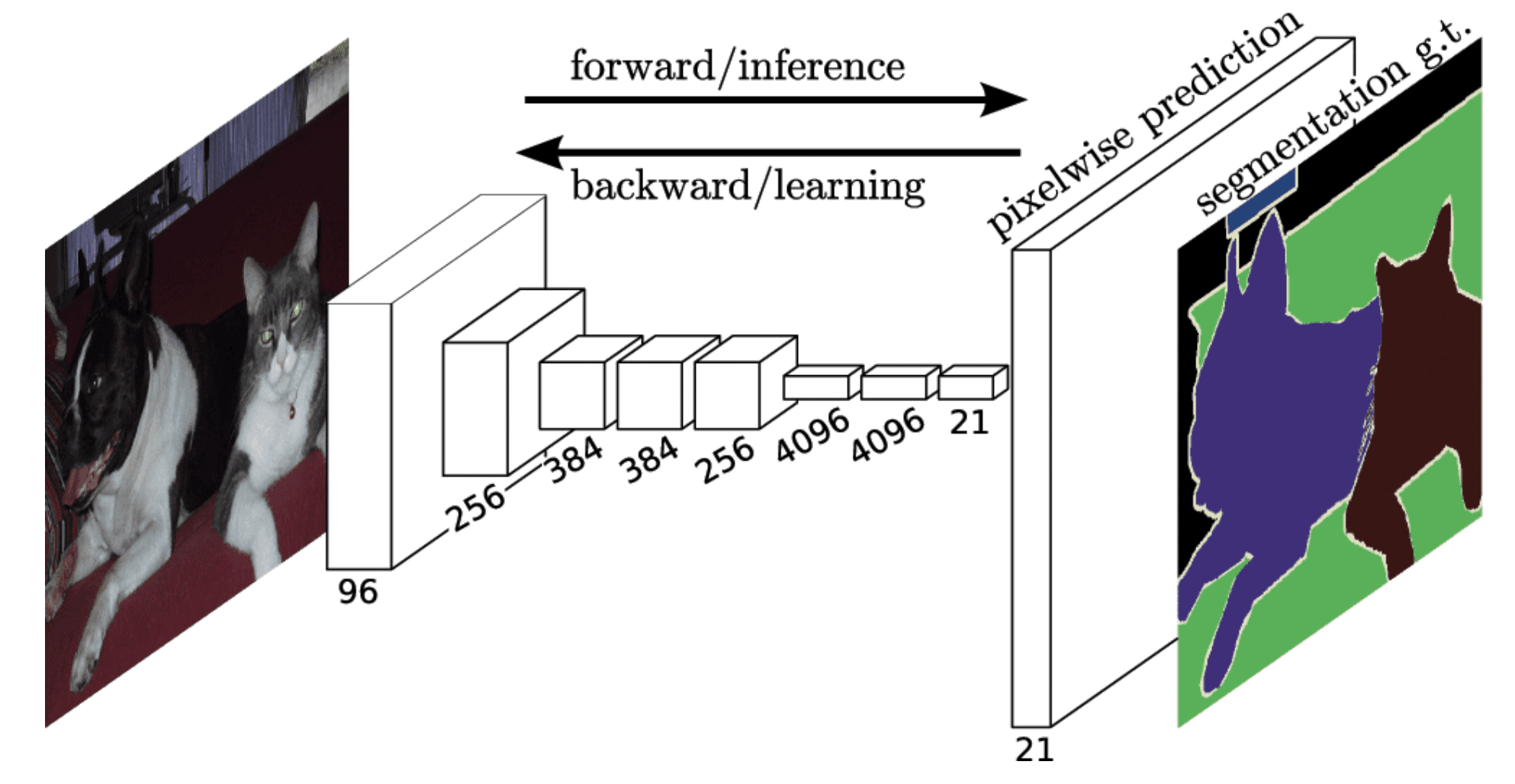
As an improvement over a baseline fully-convolutional network, we used skip connections from higher resolution feature maps, recreating U-Net network architecture. Thanks to those connections, grain information about small details isn’t lost in the process. Such an architecture makes it possible to learn fine-grained details which, when combined with a ResNet core encoder, significantly speeds up the training. The architecture of a segmentation neural network with skip connections is presented below. Cross entropy loss with weight regularization is used during training.
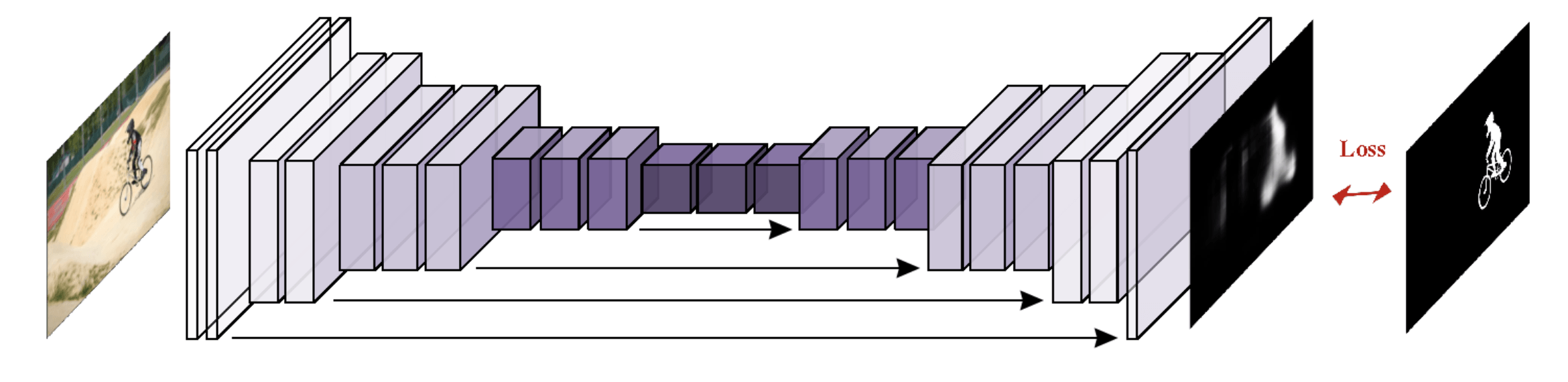
2. Network implementation
We present easy-to-understand minimal code fragments which seek to create and train deep neural networks for the semantic segmentation task. We will implement and train the network in PyTorch. Keep in mind that it’s not meant for out-of-box use but rather for educational purposes. We present our semantic segmentation task in three steps:
- Create the network
- Train and save the deep learning model
- Load the model and make predictions
2.1 Create the network
First we will create a module that performs convolution with ReLU nonlinearity. This is a basic building block in most convolutional neural networks for computer vision tasks. Convolution applies a set of filters to an image in order to extract specific features, while ReLU introduces nonlinearity between the linear layers of a neural network. Convolution with kernel size 3, stride 1 and padding 1 does not change a tensor’s spatial dimensions, but only its depth, while ReLU, as a pointwise operation, does not change any of the tensor’s dimensions.
class ConvRelu(torch.nn.Module):
def __init__(self, in_depth, out_depth):
super(ConvRelu, self).__init__()
self.conv = torch.nn.Conv2d(in_depth, out_depth, kernel_size=3, stride=1, padding=1)
self.activation = torch.nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.activation(x)
return x
We next implement a decoder block to increase the spatial size of the tensor. Generating images with neural networks usually involves up-sampling the tensor of low spatial resolution. Transposed convolution with stride greater than one can be imagined as inserting zeros between elements of input tensor and sliding a convolution kernel over it. This increases the tensor’s size. Bear in mind that doing this in a straightforward manner is inefficient, but conceptually it is how transpose convolution works. Real implementations avoid useless multiplications by zero and compute it as sparse matrix multiplication with weight matrix transposed from weight matrix representation of convolution operation with equal stride.
Be aware of other methods to increase spatial size used in generative neural networks. These include:
- Linear resizing operation which increases the spatial size of a tensor with following convolution operation
- A convolution operation to greater depth than desired with following operation which projects depth elements to spatial dimensions
- Fractionally strided convolution where a kernel is slided over a tensor with fractional strides and where linear interpolation is used to share kernel weights over the elements of a tensor
Here we apply additional convolution with an ReLU nonlinearity module before the transposed convolution. While this step may not be strictly required, it can improve network performance.
class DecoderBlock(torch.nn.Module):
def __init__(self, in_depth, middle_depth, out_depth):
super(DecoderBlock, self).__init__()
self.conv_relu = ConvRelu(in_depth, middle_depth)
self.conv_transpose = torch.nn.ConvTranspose2d(middle_depth, out_depth, kernel_size=4, stride=2, padding=1)
self.activation = torch.nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv_relu(x)
x = self.conv_transpose(x)
x = self.activation(x)
return x
Now let’s focus on the main network, which is intended to solve the semantic segmentation task. We follow the encoder-decoder framework with skip connections to recreate a UNet architecture. We then perform transfer learning using ResNet pre-trained on an ImageNet dataset. Below you can investigate detailed network architecture with additional information about tensor size in every layer to help you understand how network propagates input image to compute the desired output map. It’s important that there isn’t one optimal network architecture. We achieve something that works reasonably well through many attempts.
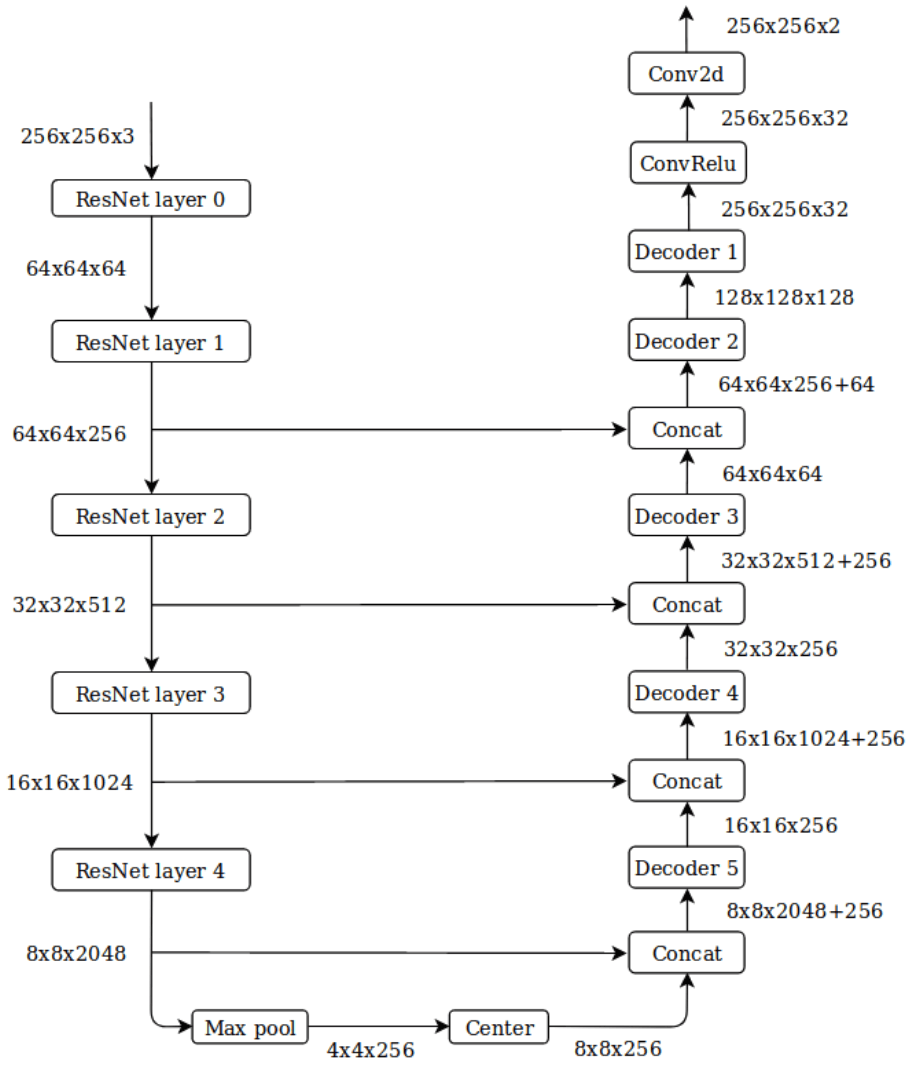
The network propagates the input tensor through the encoder while decreasing spatial resolution and increasing depth using layers from the ResNet network. The pooling layer, as well as convolution operation with stride greater than one, decreases the spatial size of a tensor. However, pooling itself does not change a tensor’s depth, which is often desired for convolution operations. In the constructor, we import a pre-trained ResNet-101 model with a torchvision module and keep only the layers, which will work as a feature extractor. After processing the image through the encoder, which transforms the input image into meaningful multi-scale representations, the decoder continues the process and transforms it into the desired semantic map. To do this, we use previously created decoder blocks. Notice that we are building a complex neural network from simpler blocks, which we either define ourselves or take from the PyTorch library. Moreover, we add skip connections – horizontal lines in a graph which connect the encoder and decoder layers by depth concatenate operation. For each pixel of the input image, the network predicts N classes (including background) with the last convolution operation with kernel size 1, which linearly projects the depth of each spatial element to another desired depth.
Keep in mind that we do not yet define loss, unlike we would do in TensorFlow, where the entire computational graph needs to be defined up front. In PyTorch, we only define the class which provides forward function. Operations used in forward pass are remembered and backward pass can be run whenever it’s needed.
class UNetResNet(torch.nn.Module):
def __init__(self, num_classes):
super(UNetResNet, self).__init__()
self.encoder = torchvision.models.resnet101(pretrained=True)
self.pool = torch.nn.MaxPool2d(2, 2)
self.conv1 = torch.nn.Sequential(self.encoder.conv1, self.encoder.bn1, self.encoder.relu, self.pool)
self.conv2 = self.encoder.layer1
self.conv3 = self.encoder.layer2
self.conv4 = self.encoder.layer3
self.conv5 = self.encoder.layer4
self.pool = torch.nn.MaxPool2d(2, 2)
self.center = DecoderBlock(2048, 512, 256)
self.dec5 = DecoderBlock(2048 + 256, 512, 256)
self.dec4 = DecoderBlock(1024 + 256, 512, 256)
self.dec3 = DecoderBlock(512 + 256, 256, 64)
self.dec2 = DecoderBlock(256 + 64, 128, 128)
self.dec1 = DecoderBlock(128, 128, 32)
self.dec0 = ConvRelu(32, 32)
self.final = torch.nn.Conv2d(32, num_classes, kernel_size=1)
def forward(self, x):
conv1 = self.conv1(x)
conv2 = self.conv2(conv1)
conv3 = self.conv3(conv2)
conv4 = self.conv4(conv3)
conv5 = self.conv5(conv4)
pool = self.pool(conv5)
center = self.center(pool)
dec5 = self.dec5(torch.cat([center, conv5], 1))
dec4 = self.dec4(torch.cat([dec5, conv4], 1))
dec3 = self.dec3(torch.cat([dec4, conv3], 1))
dec2 = self.dec2(torch.cat([dec3, conv2], 1))
dec1 = self.dec1(dec2)
dec0 = self.dec0(dec1)
return self.final(dec0)
2.2. Train and save the model
As we train the network we will be loading data in batches using PyTorch data generators, which additionally shuffles the training set, normalizes input tensors and applies color (random changes in brightnest, contrast and saturation) and spatial (random flip, flop and rotation) augmentation. While creating main network, we only need to define output depth of the last convolutional layer. There are two output classes involved in the semantic segmentation of the buildings – the probability of building pixels belonging to a building or not. Notice that necessary weights are initialized here and kept by default in CPU memory. After the output depth has been defined, we transfer all the weights to the GPU, then set the network to train mode, which results in batch normalization computing the mean and variance on each batch and updating the statistics with the moving average. Finally, we define cross entropy loss with softmax, which is included for further use during the training. Notice that the loss function doesn’t have anything in common with the network graph. We won’t freeze any pre-trained ResNet convolutional layers and train all network weights using Adam optimizer.
unet_resnet = UNetResNet(num_classes=2) unet_resnet = unet_resnet.cuda() unet_resnet.train() cross_entropy_loss = torch.nn.CrossEntropyLoss() optimizer = torch.optim.Adam(unet_resnet.parameters(), lr=0.0001, weight_decay=0.0001)
Now we are ready to start the training. We will train for number of epochs. During each epoch we exhaust the data-loader, which provides shuffled batches of data from the training set. We first transfer the batch of images and masks to GPU memory, then propagate every loaded batch of data through the network to get an output probability mask, calculate the loss and modify network weights during the backward pass. Notice that only here, during the execution, is there a connection between the network architecture and loss function. Unlike TensorFlow, which requires the entire computational graph up front, PyTorch offers dynamic graph creation during execution.
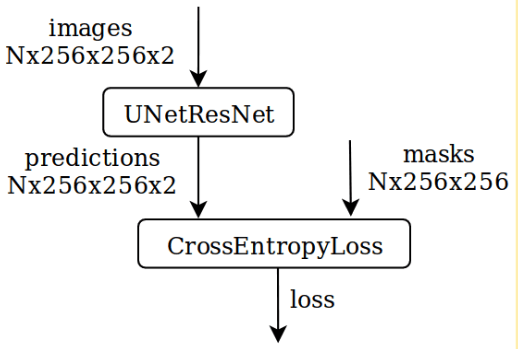
for epoch_idx in range(2):
loss_batches = []
for batch_idx, data in enumerate(train_dataloader):
imgs, masks = data
imgs = torch.autograd.Variable(imgs).cuda()
masks = torch.autograd.Variable(masks).cuda()
y = unet_resnet(imgs)
loss = cross_entropy_loss(y, masks)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_batches.append(loss.data.cpu().numpy())
print 'epoch: ' + str(epoch_idx) + ' training loss: ' + str(np.sum(loss_batches))
After the training, it’s time to save the model. We move the weights back to CPU memory, save the model weights and move it back again to GPU memory for further predictions.
model_file = './unet-' + str(epoch_idx) unet_resnet = unet_resnet.cpu() torch.save(unet_resnet.state_dict(), model_file) unet_resnet = unet_resnet.cuda() print 'model saved'
2.3. Load the model and make predictions
We first create a network and load weights from the saved checkpoint. We then set the model to eval mode, so now, instead of using parameters computed over batch, mean and variance from statistics will be used for batch normalization. We propagate the image through the network without keeping a computational graph, because no backward is needed during the predictions. To make a prediction, we load and preprocess the test image, move it to GPU memory, predict the output probability mask using softmax (which during training was hidden inside the cross entropy loss function), move the predicted mask back to CPU memory and save it.
unet_resnet = UNetResNet(num_classes=2)
model_path= './unet-99'
pretrained_model = torch.load(model_path)
for name, tensor in pretrained_model.items():
unet_resnet.state_dict()[name].copy_(tensor)
unet_resnet.eval()
softmax2d = torch.nn.Softmax2d()
img = cv2.imread('./img.png')
assert img.shape[0] % 64 == 0 and img.shape[1] % 64 == 0
img = np.expand_dims(img, axis=0)
img = (img / 255.0 - MEAN) / STD
img = img.transpose(0, 3, 1, 2)
img = torch.FloatTensor(img)
img = img.cuda()
with torch.no_grad():
pred = unet_resnet(img)
pred = softmax2d(pred)
pred = pred[0, 1, :, :] > 0.7
pred = pred.data.cpu().numpy()
mask = (pred * 255.0).astype(np.uint8)
cv2.imwrite('./mask.png', mask)
3. System pipeline
The system propagates the input image through the network, corrects the output mask and performs building segmentation. The processing consists of the following stages (described from left to right, top to bottom):
- Input satellite image.
- Raw output from network after softmax layer with probability scores.
- Probability score map thresholded with removal of small objects and filling of small holes.
- Predicted mask overlaid on top of input image.
- Segmentation results.

Use cases
The solution is easily extendable to situations with more labels, such as roads, trees or rivers. In such scenarios, there are more classes in the network’s output. Raw output data can be used to speed up map-making, but after simple processing, it can also provide a user with various types of information about an area, such as average building size, occupied percentage of land, street width, number of trees etc. These features can then be used as an input for other ML models, including ones for projecting land value, emergency response or research.





