

Should I eat this mushroom?
A few days ago we have released Seahorse 1.0, a visual platform for machine learning and Big Data manipulation available for all, for free! Today, we show you how to use Seahorse to solve a simple classification problem.
We will try to distinguish edible mushrooms from poisonous ones basing on their appearance. Mushroom picking requires a lot of experience and knowledge on mushroom species recognition. Wrong classification of a mushroom (mistaking poisonous for edible one) might result in very serious health problems. We will show you that with Seahorse it is possible to aid mushroom pickers in this responsible task of mushroom classification.
We will use a publicly available dataset with mushrooms[1], where specimens descriptions are classified in two classes: edible and poisonous. Using this dataset we create and verify a prediction model that will be usable for classification of gilled mushrooms in Lepiota and Agaricus Family (the most common representative is Agaricus bisporus, also known as table mushroom).
The dataset consists of 8124 instances (4208 edible and 3916 poisonous). Each instance is described by 22 features (phenotypic traits codes, e.g. cap color, odor, veil type, habitat) and 1 label column (edible or poisonous).
We will create a Seahorse workflow: a graphical machine learning experiment representation.
Workflow Overview
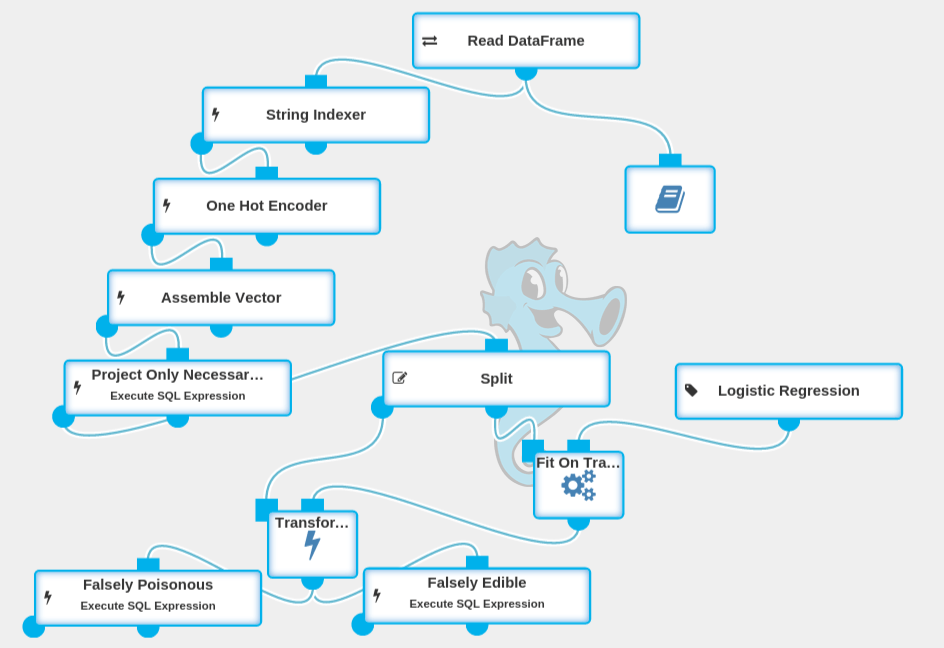
Mushroom classification – Seahorse workflow
This is a complete experiment that generates a mushroom classification model. It can be downloaded from here, but we will also show you how to create that experiment step-by-step. To follow up with this article and fully understand it, you should download and install Seahorse 1.0 using these instructions.
Step-by-Step Workflow Creation
Reading the Data
The data is provided in a form of a 23-column, comma-separated CSV-like file with column names in the first line. To work with the dataset, it has to be loaded into Seahorse. This can be done by a Read DataFrame operation. Let’s place it on the canvas using drag-and-drop from the operations palette. To load the data, we need to provide the correct path to the file.
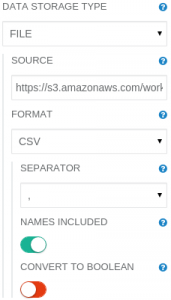
Read DataFrame operation parameters panel
Just click at the Read DataFrame operation on the canvas. Now, in panel on the right you will see its parameters. The Read DataFrame needs to have its parameters modified:
SOURCE: https://s3.amazonaws.com/workflowexecutor/examples/data/mushrooms.csv
After setting the Read DataFrame’s parameters to the correct values, the operation is ready to be executed – just simply click the RUN button in the top Seahorse toolbar. If you have much more operations on the canvas and you are interested in the results of only one operation, you can use partial execution of the workflow. Simply select that operation before clicking RUN.
RUN button
When the execution ends, a report of the operation will be available. Let’s click on the operation output port to see its result.
Operation output port
At the bottom of the screen you will see a simple DataFrame report. It contains information about data loaded by the Read DataFrame operation.
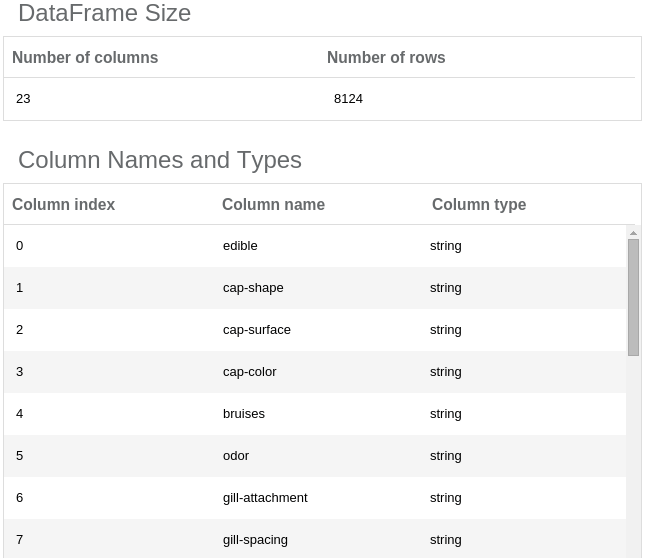
The DataFrame’s report
The DataFrame is too wide (more than 20 columns) to allow viewing the data sample in the report, so we are able to explore here only the column types and names. If you want to explore the data a bit more, you can use a Notebook operation (it allows interactive data exploration): Just place it on the canvas (use drag-and-drop technique) and connect its input port with the Read DataFrame output port (click on the output port and drag it to an input port of the other operation). Now, you can open the Notebook by selecting it on the canvas and clicking at the “Open notebook” button on the right panel.

”Open notebook” button
In the newly opened window, enter: dataframe().take(10) and click on the “run cell” button (you can use a shortcut for it: Ctrl+Enter). Now you can closely investigate the data sample of the first 10 rows returned by the Read DataFrame operation.
Data Transformation
In the first column we have labels stating to which class a specific sample belongs (possible values: edible or poisonous). We have discovered that all columns have string values. To perform classification, Seahorse needs a numeric label column and a vector of numerics as features column. We need to map string values to numbers and assembly features into a single vector column. This can be done by combining multiple operations – String Indexer with One Hot Encoder and Assemble Vector – as shown in the workflow overview image.
The String Indexer operation translates string values to numeric ordinal values. It needs to have its parameters modified, as follows:
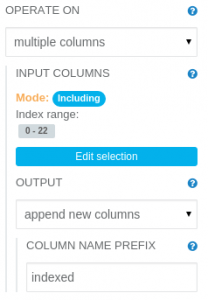
String Indexer operation parameters panel
OPERATE ON: multiple columns INPUT COLUMNS: Including index range 0-22 (all columns) OUTPUT: append new columns COLUMN NAME PREFIX: indexed
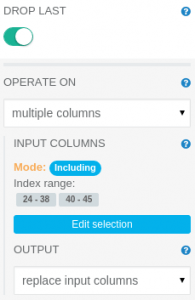
One Hot Encoder operation parameters panel
The One Hot Encoder operation translates ordinal values to vector having “1” only at position given by input numeric value. It needs to have its parameters modified, as follows:
OPERATE ON: multiple columns INPUT COLUMNS: Including index range 24-38 and 40-45
We have to exclude the column at index 39 (indexed_veil-type) because all mushroom specimens had partial veil. One Hot Encoder does not allow operating on columns with only one value (unless user wants to drop the last category using DROP LAST parameter).
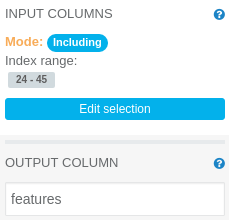
Assemble Vector operation parameters panel
Assemble Vector merges columns with numerics and vectors of numerics into a single vector of numerics. It needs to have its parameters modified, as follows:
INPUT COLUMNS: Including index range 24-45 (columns generated by the String Indexer, excluding generated column containing edibility label)
OUTPUT COLUMN: features
Remove Unnecessary Columns
We will use the Execute SQL Expression operation to remove unnecessary columns from the dataset and give more meaningful names to columns that are essential for our experiment. It will make the dataset reports smaller and facilitate exploring data.
Execute SQL Expression needs to have its parameters modified, as follows:
DATAFRAME ID: df EXPRESSION: SELECT edible AS edibility_string, indexed_edible AS edibility_label, features FROM df
Splitting Into Training and Test Set
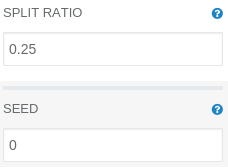
Split operation parameters panel
To perform a fair evaluation of our model, we need to split our data into two parts: a testing dataset and a training dataset. That task could be accomplished by using a Split operation. To divide the dataset in ratio 1 to 3, we do need to modify its default parameters:
SPLIT RATIO: 0.25 (percentage of rows that should end up in the first output DataFrame – the test set)
Model Training
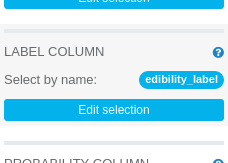
Logistic Regression operation LABEL COLUMN parameter
To train a model, we need to use the Fit operation, which can be used to fit an Estimator. We want to use logistic regression classification, so we will put the Logistic Regression operation on the canvas and connect it to the Fit operation.
We will leave almost all default values of Logistic Regression parameters unchanged, we need only to change the label column to
edibility_label. LABEL COLUMN: edibility_label
Verifying Model Effectiveness On Test Data
By using Split operation, we had generated a training dataset and a test dataset from the input data. We have trained our model on the training dataset. Now it is time to use the test dataset to verify the effectiveness of our classification model. To generate predictions using the trained model, we need to use a Transform operation. To assess effectiveness of our model we will count “Falsely Poisonous” (waste of edible mushrooms) and “Falsely Edible“ (very dangerous!) entries in the test dataset. To perform the calculations, we will use the Execute SQL Expression operation.
After executing the Transform operation, we can investigate the resulting report:
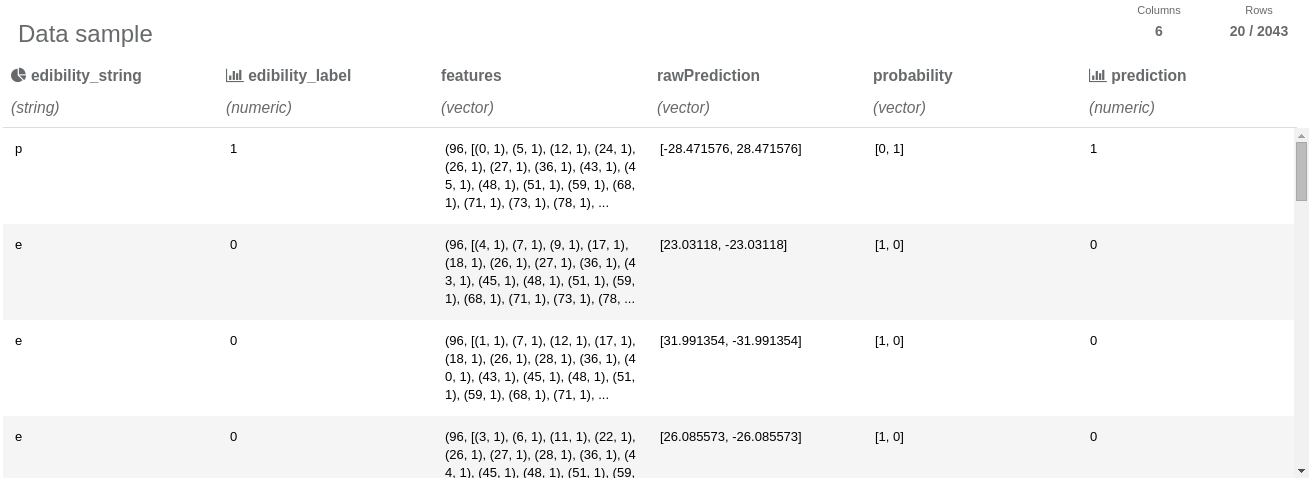
Thanks to projecting only the necessary columns, the resulting dataset fits in the column number limit and we are able to view the data sample. We can notice that the test dataset has 2043 entries. Also we can see that the String Indexer operation assigned 0 to “e” label (edible class) and 1 to “p” label (poisonous class). We can also notice that the prediction column has “almost the same” values as “edibility” column, so we can suspect that our model performs well. Let’s measure its performance:
The Execute SQL Expression (Falsely Edible) needs to have its parameters modified, as follows:
DATAFRAME ID: df EXPRESSION: SELECT * FROM df WHERE prediction=0 AND edibility_label=1 The Execute SQL Expression (Falsely Poisonous) needs to have its parameters modified, as follows: DATAFRAME ID: df EXPRESSION: SELECT * FROM df WHERE prediction=1 AND edibility_label=0 Now we can explore reports in these two operations and compare the number of rows in each of them: Falsely Poisonous: 0 Falsely Edible: 0
Conclusion
It means that we have trained a surprisingly accurate prediction model for classifying mushrooms. We have to remember that some dangers remain such as:
- Mushroom picker examining the specimen can make a mistake during assessment of traits or entering data to the computer.
- Data sample might be too small to create a comprehensive model for predicting edibility of all mushrooms that users will want to classify.
- Two different mushroom species can have identical traits, while one of the species is edible and the second one is poisonous.
Due to those problems, we can use this model only to aid expertise on mushroom edibility. Experts should always have the last word over issues that are potentially dangerous for other people, like classifying poisonous mushrooms. This must be followed not only due to lack of confidence for the newly created prediction model (experts can make mistakes even more often than this model), but most of all – due to legal responsibility of those decisions.
[1] Lichman, M. (2013). UCI Machine Learning Repository [http://archive.ics.uci.edu/]. Irvine, CA: University of California, School of Information and Computer Science.
