
Table of contents
Over the last few months, ChatGPT has generated a great deal of excitement. Some have gone as far as to suggest it is a giant step in developing AI that will overtake humanity in many important areas, both in business and social life. Others view it more as a distraction on the path towards achieving human-level intelligence. How did ChatGPT generate such hype? In this article, we’ll try to explain.
Table of contents
How did we get here?
Recent advances in natural language processing can be viewed as a progression toward more flexible and general systems. We can see various ideas flowing through the field of NLP development. A few years ago, around 2013-14, the main approach to NLP tasks was to use word embeddings, which are vectors that represent the meaning of words. This was the standard approach in the vast majority of language-related tasks, such as text classification, in which embeddings were first obtained either through training or by downloading pre-trained vectors from public sources, and then fed into a task-specific architecture. This approach necessitated the creation of a task-specific, labeled dataset on the one hand, and a task-specific architecture of the model itself on the other. Not only did this require a significant amount of effort, but the performance of such an approach was limited by the representational capabilities of the input embeddings. Word embeddings were unable to capture the meaning of words based on context (words surrounding them) or the semantics of the entire text.
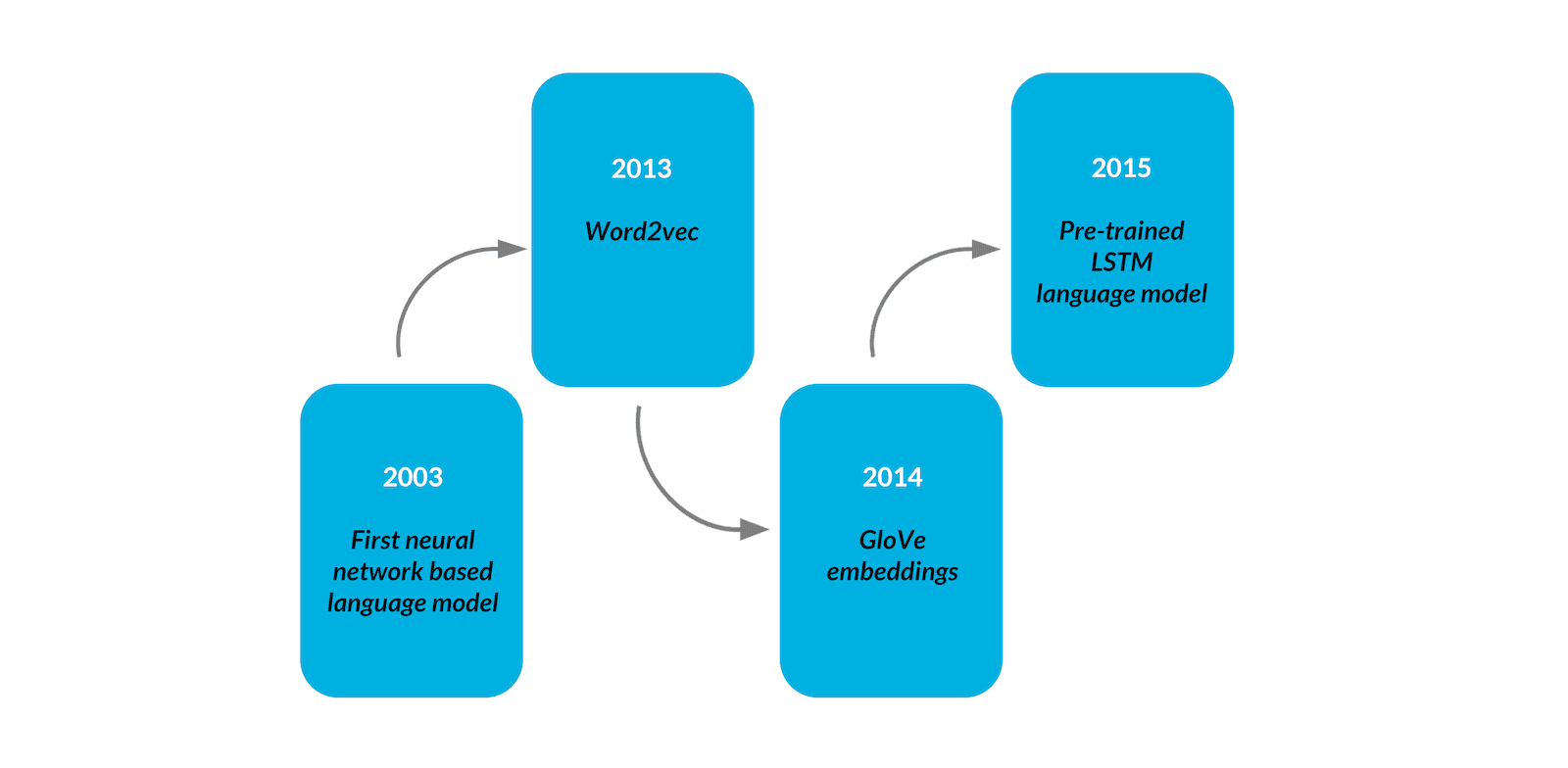
Since 2015, researchers have been experimenting with the idea of semi-supervised pre-training of LSTM [1] and Transformer-based language models on large corpora of text, and then supervised fine-tuning them for specific tasks on a much smaller dataset. BERT [2] and GPT-1 [3] are two examples of such approaches. Such methods eliminated the need for task-specific models, resulting in architectures that outperformed existing solutions to many difficult NLP tasks. Even though the task-specific dataset and fine-tuning were still required, it is a significant improvement.
The scarcity of large enough datasets for some tasks, the effort required to create them, and the lack of generalization of fine-tuned models outside the training distribution prompted the development of a new, human-like paradigm in which all that is required is a short natural language description of the task that the model is asked to perform, with an optional, tiny number of demonstrations added to the instruction. GPT-2 [4], GPT-3 [5], and other generative language models described in the following section represent this paradigm.
GPT: applications and architecture
GPT is an abbreviation of Generative Pre-trained Transformer. It is generative in the sense that it can generate text-given input. Because it has already been trained on a large corpus of text, it is pre-trained. Finally, it is a neural network architecture that is based on the Transformer [6].
A GPT generates text in response to a text input, called a prompt. It is a simple but versatile framework, as many problems can be converted to text-to-text tasks. On the one hand, GPT can be asked to perform standard NLP tasks such as summarizing/classifying a text passage, answering questions about a given piece of text, or extracting named entities from it. On the other hand, due to its generative nature, GPT is an ideal tool for creative applications. It can create a story based on a brief premise, hold a conversation, or… write a blog post. Furthermore, if trained on a corpus of code, such a model could perform code generation, editing, and explanation tasks, such as generating Python docstrings, generating git commit messages, translating natural language to SQL queries, or even translating code from one programming language to another.
Modern language models, such as OpenAI’s GPT-3, Google’s LaMDA [7], and DeepMind’s Gopher [8], are essentially GPT implementations. They are much more powerful than the original GPT-1, mostly because of their size – for instance, the largest variant has 175 billion parameters – and because they were pre-trained on massive amounts of text; in the case of GPT-3, it was hundreds of billions of words.
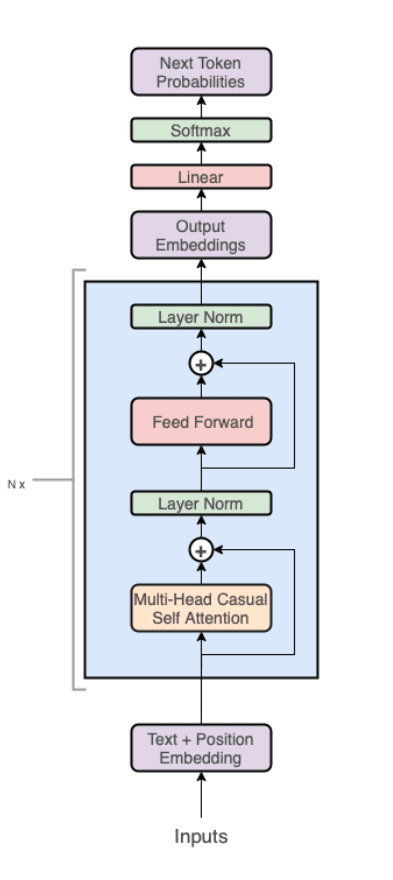
The GPT and GPT-like models are actually autoregressive language models that predict the next word in a sequence. After predicting the next word, it is appended to the initial sequence and fed back into the model to predict the subsequent one. The procedure is repeated until the model outputs a stop token or reaches the user-specified maximum length of the output sequence.
From a technical standpoint, the model is a decoder-only variant of a Transformer model, consisting of a stack of Transformer blocks followed by a linear layer and softmax that predict the probability that each word in the model’s vocabulary is the next token in a sequence. Each transformer block is composed of a Multi-Head Casual Self Attention layer, a linear layer, layer normalizations, and residual connections. This architecture can be thought of as a “general-purpose differential computer” that is both efficient (transformers enable high parallelism of computation) and optimizable (via backpropagation)[10].
ChatGPT
The research community recently took a few steps forward in the development of language models. GPT-family models are trained to complete the input text rather than follow the user’s instructions. To make the models generate more sensible outputs in response to user instructions, as well as to make them more truthful and less toxic, the authors opted for the inclusion of human feedback in the process of training the model. This technique, called Reinforcement Learning from Human Feedback (RLHF) is so interesting that we decided to devote a whole blog post to describing it in detail – feel free to read more about it here!
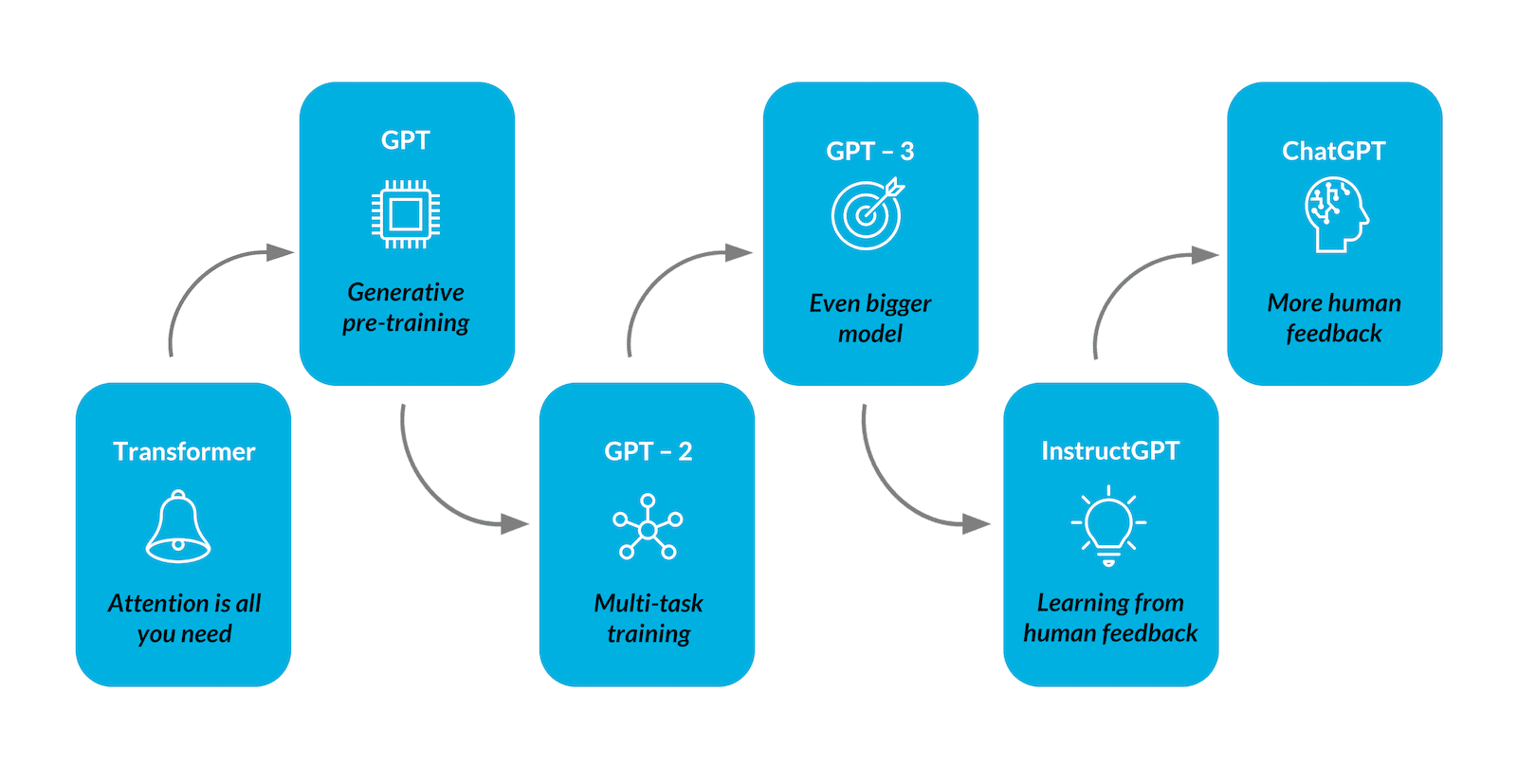
The application of this technique has resulted in new iterations of the models, such as InstructGPT [12] and ChatGPT [13]. The latter was the subject of massive attention from the public, even outside of the AI world itself. ChatGPT created a stir in the media, mostly because of its availability and API that allows everyone to use it directly [14].
With just a couple of commands, ChatGPT can prove its ability to interact with a human by producing a well-tailored resume, playing a game of chess, or writing a part of compilable code. It also acts as an information distiller, providing a comprehensive yet concise summary of a given subject.
OpenAI recently enabled ChatGPT API access under the name gpt-3.5-turbo. It’s a GPT-3.5 model optimized for the chat that costs one-tenth the price of the best previously available model. More information on that can be found here.
Future perspectives
In spite of the fact that such developments are clearly ground-breaking, there seems to be a long way to go for it to become standard for general NLP purposes. Current studies prove that even though the model is impressive given its do-it-all ability, it is underperforming compared to existing state-of-the-art solutions for NLP tasks. For instance, in the recently published paper by J. Kocon et al., ChatGPT seems to be yielding worse results than the current best models in all of the 25 different NLP tasks that were tested in the publication [15]. Anyone who has used the model for a bit longer could notice its limitations, such as the fact that it lacks knowledge of recent events.
We are eager to observe further development in this area of AI. Ideas to make the model better and more versatile seem to be never-ending and the results are already looking very promising. Bibliography
- Semi-supervised Sequence Learning, Andrew M. Dai, Quoc V. Le, 2015
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Jacob Devlin et al., 2018
- Improving Language Understanding by Generative Pre-Training, Alec Radford et al., 2018
- Language Models are Unsupervised Multitask Learners, Alec Radford et al., 2019
- Language Models are Few-Shot Learners, Tom B. Brown et al., 2020
- Attention Is All You Need, Ashish Vaswani et al., 2017
- LaMDA blogpost, Eli Collins, Zoubin Ghahramani, 2021
- Scaling Language Models: Methods, Analysis & Insights from Training Gopher, Jack W. Rae, 2022
- Transformer Models: an Introduction and Catalog, Xavier Amatriain, 2023
- https://twitter.com/karpathy/status/1582807367988654081
- GPT in 60 Lines of NumPy, Jay Mody, 2023
- Training language models to follow instructions with human feedback, Long Ouyang et al., 2022
- https://openai.com/blog/chatgpt/
- https://chat.openai.com/chat
- ChatGPT: Jack of all trades, master of none, Jan Kocon et al., 2023





