Table of contents
This update of our benchmark Business Utility Evaluation (BU Eval) is especially notable because it includes the newly evaluated Claude-Fable-5, a model attracting significant attention, which now leads the ranking with the highest Business Utility Score in this snapshot.
The current leaderboard is based on the 2026-06-11 evaluation. This update expands on the previous evaluation snapshot by adding several newly evaluated models to the LLM Business Utility Leaderboard. The ranking compares frontier models on practical business usefulness, not just benchmark-style correctness.
BU Eval (read more here) measures whether an LLM can produce a correct answer, but also whether that answer is reliable enough to support business decision-making. The benchmark reports a combined Business Utility Score, which rewards models that demonstrate both high analytical accuracy and consistent performance across repeated runs.
Latest ranking
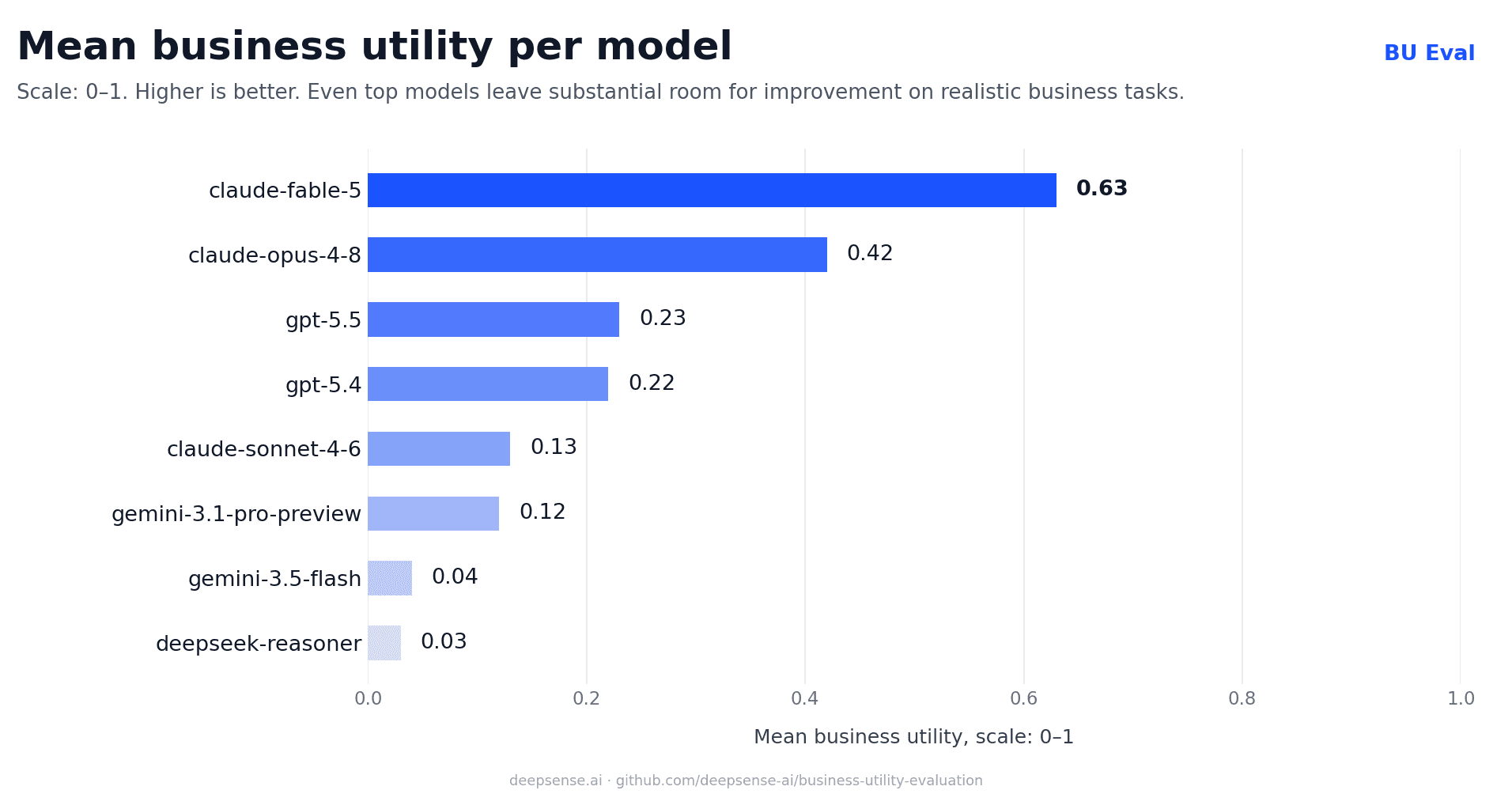
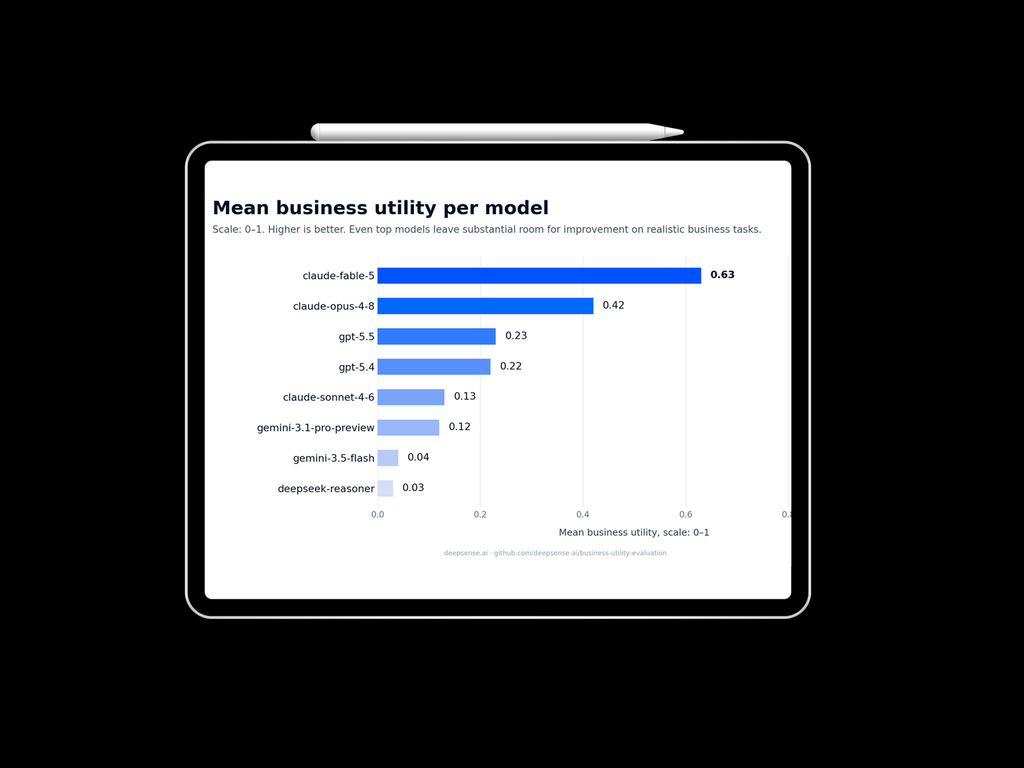
In this round, the newly evaluated claude-fable-5 achieved the highest Business Utility Score of 0.63, showing a measurable advancement over claude-opus-4-8, which scored 0.42.
The results for gpt-5.5 and gpt-5.4 remained closely matched, with scores of 0.23 and 0.22 respectively. In this workflow simulation, the two OpenAI models showed no significant performance difference from a business utility perspective.
The remaining evaluated models scored lower in this snapshot. claude-sonnet-4-6 and gemini-3.1-pro-preview delivered comparable results, with Business Utility Scores of 0.13 and 0.12.
Efficiency-focused or specialized reasoning models, specifically gemini-3.5-flash and deepseek-reasoner, demonstrated limited utility on these complex analytical business tasks, scoring 0.04 and 0.03 respectively. These results suggest that substantial room for improvement remains for these architectures in realistic enterprise AI environments where reliability, repeatability, and decision quality matter.
How to read the result
The Business Utility Score reflects a deployment-oriented view of LLM performance: a model is more useful when it combines high average analytical quality with repeatable behavior across runs.
In BU Eval, each model is evaluated across multiple trajectories. Failed trajectories are scored as zero, which penalizes models that occasionally produce unusable outputs even if they perform well in other runs.
The metric is bounded between 0 and 1, but the benchmark does not define a universal production-readiness threshold. Acceptable utility depends on the specific business use case, risk tolerance, verification costs, and the level of human oversight required.
For enterprise AI teams, this distinction matters. A model with strong average performance but high variability may still be expensive or risky to deploy, because every output requires additional review. BU Eval is designed to surface this gap between benchmark performance and practical business reliability.
Interested in custom datasets and benchmarks?

Evaluation setup
The current run expands our evaluation matrix to include models from Anthropic, OpenAI, Google, and DeepSeek.
Models were evaluated using provider-specific execution harnesses and run with default temperature settings. Where applicable, the highest available reasoning-effort configuration was used. Anthropic models were evaluated with reasoning effort set to xhigh.
The benchmark currently includes several synthetic business simulation tasks, including:
- bottleneck employee detection,
- machinery malfunction analysis,
- marketplace activity monitoring,
- sales representative performance analysis,
- supply chain issue investigation.
These tasks are designed to evaluate whether LLMs and AI agents can identify business-relevant patterns, anomalies, root causes, and operational risks from realistic data.
Check the public BU Eval repository on GitHub
The detailed results and artifacts are available in the public repository.
About BU Eval
Business Utility Evaluation (BU Eval) is an LLM and AI agent benchmark designed to measure how well AI systems perform in real-world analytical business workflows.
Unlike traditional AI benchmarks that focus primarily on answer correctness, BU Eval evaluates whether a model is reliable enough to support decision-making in production environments. It is designed for teams assessing enterprise AI readiness, AI agent reliability, and LLM performance in business workflows.
Read more here about why we discovered the Business Utility metric.
The benchmark assesses both analytical quality and result stability, helping organizations understand not only whether a model can solve a business problem, but whether it can do so consistently across repeated runs. This makes BU Eval particularly relevant for teams evaluating AI systems for enterprise deployment, operational automation, AI agents, and data-driven decision support.
BU Eval uses synthetic business simulations that reflect realistic analytical tasks, including supply chain analysis, marketplace monitoring, operational bottleneck detection, and business performance investigation.
Models receive simulator-generated datasets and must identify patterns, anomalies, root causes, and actionable business insights from incomplete or indirect evidence. This setup is closer to real-world business analysis than many academic benchmarks, where tasks are often isolated, static, or optimized solely for answer correctness.
At the core of the benchmark is the Business Utility Score, a metric that combines average performance with repeatability. By accounting for both accuracy and stability, BU Eval provides a more practical measure of AI model readiness for production use than benchmark scores alone.
The benchmark is used to evaluate leading frontier models and AI agents, including systems from OpenAI, Anthropic, Google, DeepSeek, and other model providers. Results help AI leaders compare models based on their practical usefulness in business settings rather than academic task performance alone.
Interested in custom datasets and benchmarks?
This ranking is part of our ongoing Business Utility Evaluation Leaderboard series. Each update reports the latest benchmark results, methodology improvements, and performance trends across state-of-the-art AI models. Full benchmark methodology, evaluation code, datasets, and result artifacts are available in the public repository.
Table of contents





