Table of contents
Region of Interest pooling (RoI pooling) is a widely used technique in object detection with convolutional neural networks. It extracts fixed-size feature maps (e.g., 7×7) from variable-sized regions, enabling efficient classification of multiple objects like cars or pedestrians. RoI Align refines this process by avoiding coordinate quantization and using bilinear interpolation, resulting in more precise feature extraction—crucial for tasks like instance segmentation.
Here’s some relevant information from 2025 on the topic. You can still find the 2017 version below this article.
Region of Interest Align: A Refined Approach
While RoI pooling has proven to be an effective strategy for object detection, it introduces a subtle drawback: the quantization of coordinates when mapping regions to a fixed-size feature map. This quantization can cause slight misalignments between the original image features and the pooled output. To overcome this issue, the Region of Interest Align (RoI Align) method was introduced.
What is RoI Align?
RoI align is a neural network layer specifically designed for object detection and segmentation tasks. Introduced in the context of Mask R-CNN [1], it improves upon ROI pooling by eliminating the rounding of coordinates. Instead of quantizing the boundaries of each region, RoI align computes exact floating-point values and uses bilinear interpolation to sample the feature map. This preserves the spatial correspondence between the original image and the extracted features.
RoI align follows a process similar to RoI pooling with one key difference: the absence of quantization. Here’s how it works:
- Exact Region Extraction: The layer receives a feature map from a convolutional network along with a set of regions defined by floating-point coordinates. These coordinates represent the precise locations of the regions of interest.
- Dividing the Region: Instead of rounding off the coordinates, RoI align divides each region into equally sized bins based on the desired output dimensions.
- Bilinear Interpolation: For each bin, the layer computes the feature value using bilinear interpolation. This method evaluates the four neighboring pixels to determine an interpolated value, thus preserving finer spatial details.
- Output Generation: The final output is a fixed-size feature map for each region, where each element accurately reflects the corresponding area in the original feature map.
RoI align offers a range of benefits that make it particularly appealing for tasks requiring high spatial accuracy. By avoiding the inherent quantization error of RoI pooling, it ensures that even subtle details in the feature maps are preserved, which is crucial for precise object localization and segmentation. This enhanced precision not only contributes to better detection performance but also improves the overall robustness of the model when dealing with objects of various scales and shapes. The following key advantages highlight why RoI align has become a favored technique in modern computer vision applications:
- Improved Spatial Accuracy: By avoiding the rounding process, RoI align maintains better alignment between the region proposal and the feature map, leading to more accurate object localization.
- Enhanced Performance in Segmentation: The precise mapping is particularly beneficial for instance segmentation tasks, where pixel-level accuracy is crucial.
- End-to-End Training: Similar to RoI pooling, RoI align supports end-to-end training. However, its improved feature extraction often translates into better overall performance, especially when fine details matter.
- Versatility: The technique is highly adaptable and can be integrated into various object detection frameworks, offering a balance between speed and accuracy.
RoI Align – example
To understand how ROI Align works, it’s often helpful to walk through a concrete example that illustrates each step of the process. The example below clearly demonstrates how the region of interest is selected, subdivided, and processed using bilinear interpolation to generate an aligned feature map.
In our example, we start with an 8×8 feature map and select a rectangular ROI from it. Once the ROI is defined, it is subdivided into smaller regions—in this case, a 2×2 grid—by dividing the ROI into equal parts. Each subregion corresponds to a specific part of the ROI, ensuring that the spatial structure is maintained.

Instead of using max pooling, ROI Align computes the value for each subregion using bilinear interpolation. For each cell in the grid, the center is taken as the sampling point. The four nearest integer grid points around the center are identified, and their values are blended together based on the distances from the center. Semi-transparent markers in the illustrative images highlight these contributing areas, visually demonstrating how the interpolation is performed.

The final outcome is a fixed-size feature map—in this example, a 2×2 map—where each cell’s value is the result of the interpolation process. This aligned pooling maintains the spatial accuracy and detailed information from the original ROI, which is crucial for precise object detection and segmentation.

2017 version
Region of interest pooling
We’ve just released an open-source implementation of RoI pooling layer for TensorFlow (you can find it here). In this post, we’re going to say a few words about this interesting neural network layer. But first, let’s start with some background. Two major tasks in computer vision are object classification and object detection.
In the first case the system is supposed to correctly label the dominant object in an image. In the second case it should provide correct labels and locations for all objects in an image. Of course there are other interesting areas of computer vision, such as image segmentation, but today we’re going to focus on detection. In this task we’re usually supposed to draw bounding boxes around any object from a previously specified set of categories and assign a class to each of them. For example, let’s say we’re developing an algorithm for self-driving cars and we’d like to use a camera to detect other cars, pedestrians, cyclists, etc. — our dataset might look like this. In this case we’d have to draw a box around every significant object and assign a class to it.
This task is more challenging than classification tasks such as MNIST or CIFAR. On each frame of the video, there might be multiple objects, some of them overlapping, some poorly visible or occluded. Moreover, for such an algorithm, performance can be a key issue. In particular for autonomous driving we have to process tens of frames per second. So how do we solve this problem? [irp posts=”16874″ name=”Playing Atari with deep reinforcement learning – deepsense.ai’s approach”]
Typical architecture
The object detection architecture we’re going to be talking about today is broken down in two stages:
- Region proposal: Given an input image find all possible places where objects can be located. The output of this stage should be a list of bounding boxes of likely positions of objects. These are often called region proposals or regions of interest. There are quite a few methods for this task, but we’re not going to talk about them in this post.
- Final classification: for every region proposal from the previous stage, decide whether it belongs to one of the target classes or to the background. Here we could use a deep convolutional network.
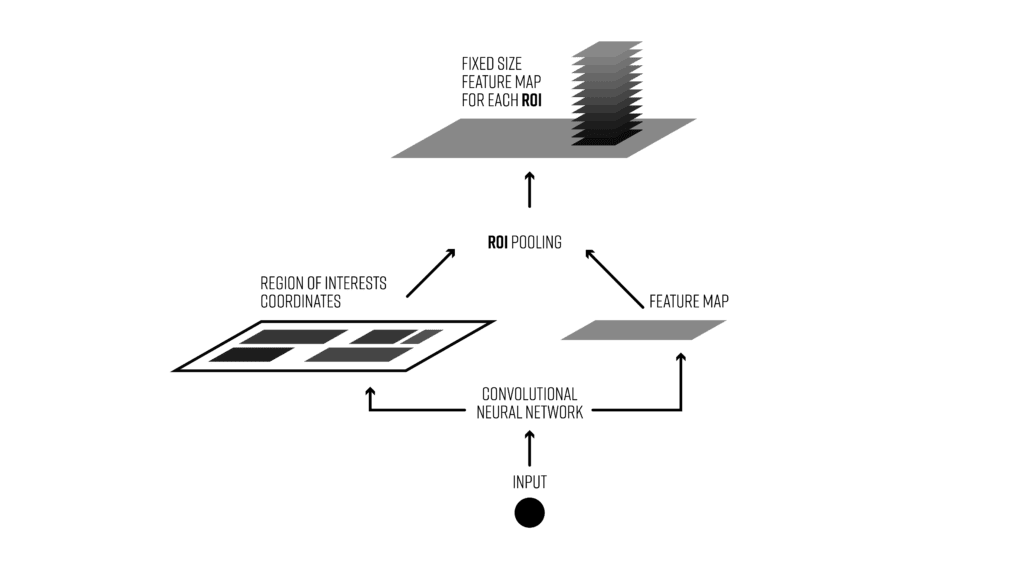
Usually in the proposal phase we have to generate a lot of regions of interest. Why? If an object is not detected during the first stage (region proposal), there’s no way to correctly classify it in the second phase. That’s why it’s extremely important for the region proposals to have a high recall. And that’s achieved by generating very large numbers of proposals (e.g., a few thousands per frame).
Most of them will be classified as background in the second stage of the detection algorithm. Some problems with this architecture are:
- Generating a large number of regions of interest can lead to performance problems. This would make real-time object detection difficult to implement.
- It’s suboptimal in terms of processing speed. More on this later.
- You can’t do end-to-end training, i.e., you can’t train all the components of the system in one run (which would yield much better results)
That’s where region of interest pooling comes into play. [irp posts=”12080″ name=”Optimize Spark with DISTRIBUTE BY & CLUSTER BY”]
What is region of interest pooling?
Region of interest pooling is a neural-net layer used for object detection tasks. It was first proposed by Ross Girshick in April 2015 (the article can be found here) and it achieves a significant speedup of both training and testing. It also maintains a high detection accuracy. The layer takes two inputs:
- A fixed-size feature map obtained from a deep convolutional network with several convolutions and max pooling layers.
- An N x 5 matrix of representing a list of regions of interest, where N is a number of RoIs. The first column represents the image index and the remaining four are the coordinates of the top left and bottom right corners of the region.

An image from the Pascal VOC dataset annotated with region proposals (the pink rectangles)What does the RoI pooling actually do? For every region of interest from the input list, it takes a section of the input feature map that corresponds to it and scales it to some pre-defined size (e.g., 7×7). The scaling is done by:
- Dividing the region proposal into equal-sized sections (the number of which is the same as the dimension of the output)
- Finding the largest value in each section
- Copying these max values to the output buffer
The result is that from a list of rectangles with different sizes we can quickly get a list of corresponding feature maps with a fixed size. Note that the dimension of the RoI pooling output doesn’t actually depend on the size of the input feature map nor on the size of the region proposals. It’s determined solely by the number of sections we divide the proposal into.
What’s the benefit of RoI pooling? One of them is processing speed. If there are multiple object proposals on the frame (and usually there’ll be a lot of them), we can still use the same input feature map for all of them. Since computing the convolutions at early stages of processing is very expensive, this approach can save us a lot of time. [irp posts=”14034″ name=”Deep learning for satellite imagery via image segmentation”]
Region of interest pooling — example
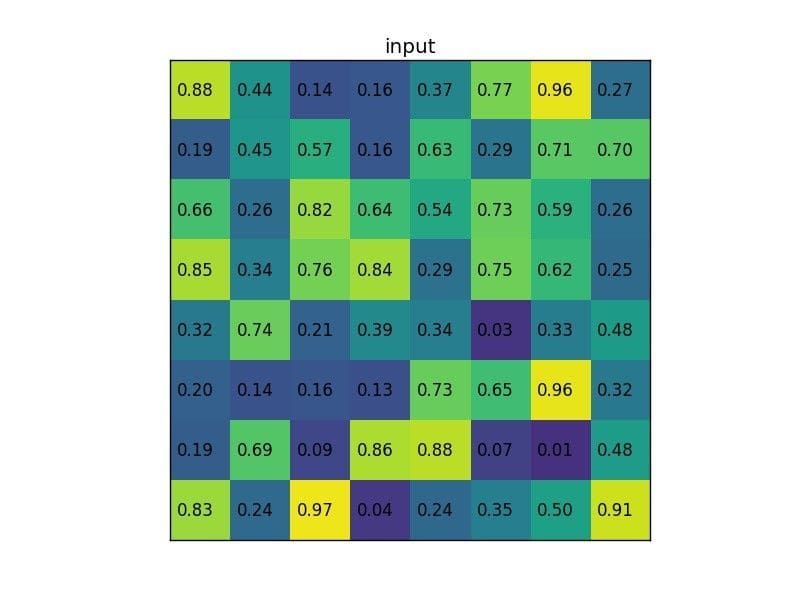
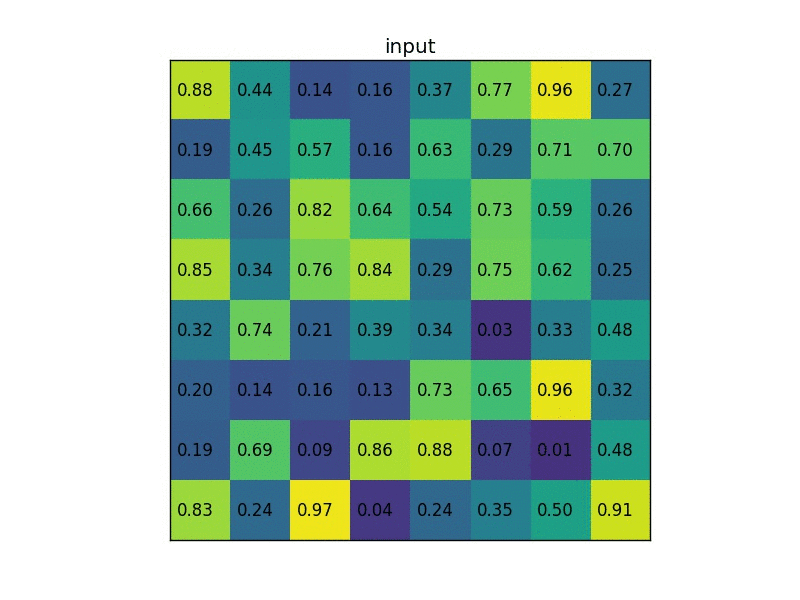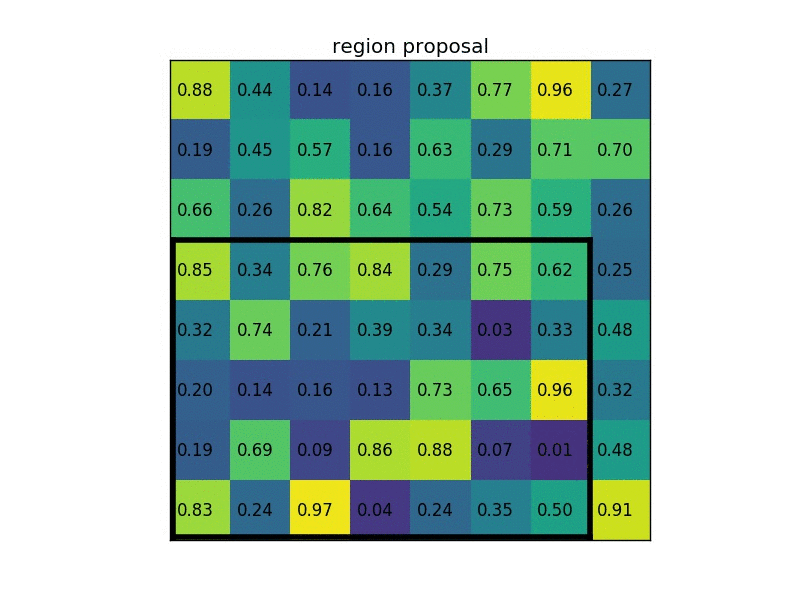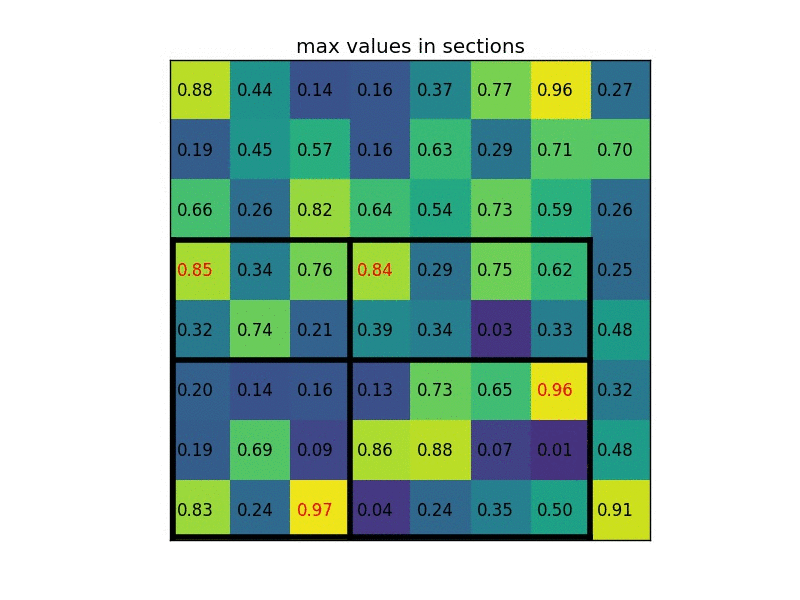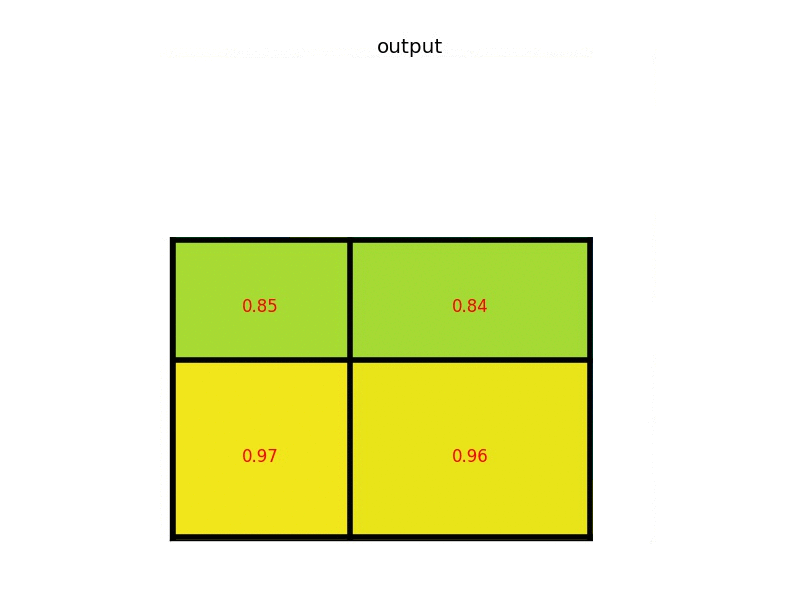
Let’s consider a small example to see how it works. We’re going to perform region of interest pooling on a single 8×8 feature map, one region of interest and an output size of 2×2. Our input feature map looks like this:
Let’s say we also have a region proposal (top left, bottom right coordinates): (0, 3), (7, 8). In the picture it would look like this:
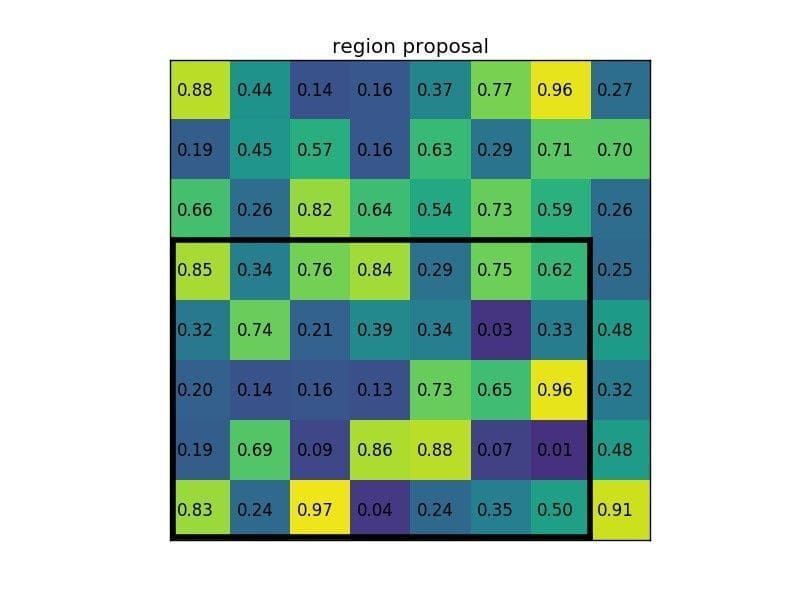
Normally, there’d be multiple feature maps and multiple proposals for each of them, but we’re keeping things simple for the example. By dividing it into (2×2) sections (because the output size is 2×2) we get:
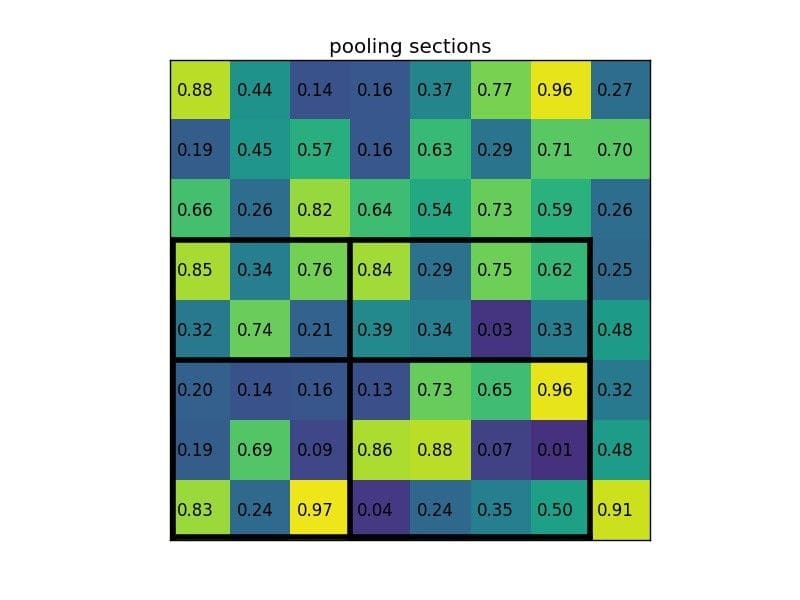
Notice that the size of the region of interest doesn’t have to be perfectly divisible by the number of pooling sections (in this case our RoI is 7×5 and we have 2×2 pooling sections). The max values in each of the sections are:
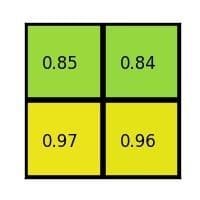
And that’s the output from the Region of Interest pooling layer. Here’s our example presented in form of a nice animation:
What are the most important things to remember about RoI Pooling?
- It’s used for object detection tasks
- It allows us to reuse the feature map from the convolutional network
- It can significantly speed up both train and test time
- It allows to train object detection systems in an end-to-end manner
If you need an opensource implementation of RoI pooling in TensorFlow you can find our version here. In the next post, we’re going to show you some examples on how to use region of interest pooling with Neptune and TensorFlow.
Conclusion
Both RoI pooling and RoI align offer unique benefits, and choosing between them involves a careful evaluation of trade-offs. RoI pooling is computationally efficient and has been widely adopted in earlier detection frameworks, making it a solid choice when speed is the primary concern and minor misalignments can be tolerated. On the other hand, RoI align addresses the quantization errors inherent in RoI pooling by using precise coordinate mapping and bilinear interpolation, resulting in improved spatial accuracy. This makes it particularly advantageous for tasks that require pixel-level precision, such as instance segmentation or applications where even slight error could impact performance.
In scenarios where processing speed is paramount and the detection task can endure small inaccuracies, RoI pooling remains a viable option. However, when the application’s success hinges on precise localization and fine-grained feature extraction, the additional computational cost of RoI align is often justified. Ultimately, the choice between these methods should be guided by the specific requirements of your project, including accuracy needs, computational resources, and the overall impact on your model’s performance.
References
- Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
- Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
- He, K., Gkioxari, G., Dollar, P., & Girshick, R. (2017, October). Mask R-CNN. 2017 IEEE International Conference on Computer Vision (ICCV). Presented at the 2017 IEEE International Conference on Computer Vision (ICCV), Venice. doi:10.1109/iccv.2017.322.
- Sermanet, Pierre, et al. “Overfeat: Integrated recognition, localization and detection using convolutional networks.” arXiv preprint arXiv:1312.6229. 2013.





