
Table of contents
From countering an invasion of aliens to demolishing a wall with a ball – AI outperforms humans after just 20 minutes of training. However, rebuffing the alien invasion is only the first step to performing more complicated tasks like driving a car or assisting elderly or injured people.
Table of contents
Luckily, there has been no need to counter a real space invasion. That has not stopped deepsense.ai, in cooperation with Intel, from building an AI-powered master player that has now attained superhuman mastery in Atari classics like Breakout, Space Invaders, and Boxing in less than 20 minutes.
This article discusses a few of the critical aspects behind that mastery:
- What is reinforcement learning?
- How are the RL agents evaluated?
- Why Atari games provide a good environment for testing RL agents
- What are potential use cases of models designed with RL and playing Atari with deep reinforcement learning
So why is playing Atari with deep reinforcement learning a deal at all?
Reinforcement learning is based on a system of rewards and punishments (reinforcements) for a machine that gets a problem to solve. It is a cutting-edge technology that forces the AI model to be creative – it is provided only with the indicator of success and no additional hints. Experiments combining deep learning and reinforcement learning have been done in particular by DeepMind (in 2013) and by Gerald Tesauro even before (in 1992). We focused on reducing the time needed to train the model.
A well-designed system of rewards is essential in human education. Now, with reinforcement learning, such a system has become a pillar of teaching computers to perform more sophisticated tasks, such as beating human champions in the game Go. In the near future it may be driving an autonomous car. In the case of the Atari 2600 game, the only indicator of success was the points the artificial intelligence earned. There were no further hints or suggestions. Thus the algorithm had to learn the rules of the game and find the most effective tactics by itself to maximize the long-term rewards it earned.
In 2013 the learning algorithm needed a whole week of uninterrupted training in an arcade learning environment to reach superhuman levels in classics like Breakout (knocking out a wall of colorful bricks with a ball) or Space Invaders (shooting out alien invaders with a mobile laser cannon). By 2016 DeepMind had cut the time to 24 hours by improving the algorithm.
| Breakout | ||
| Initial performance | After 15 minutes of training | After 30 minutes of training |
 | 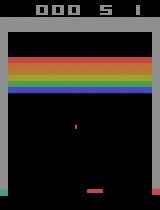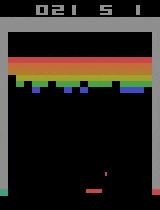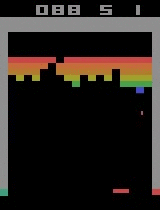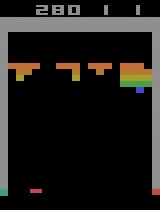 |  |
| Assault | ||
| Initial performance | After 15 minutes of training | After 30 minutes of training |
 |  |  |
While the whole process may sound like a like bunch of scientists having fun at work, playing Atari with deep reinforcement learning is a great way to evaluate a learning model. On a more sobering note, if someone had a problem understanding the rules of “Space invaders”, would you let him drive your car?
Cutting the time of deep reinforcement learning
DeepMind’s work inspired various implementations and modifications of the base algorithm including high-quality open-source implementations of reinforcement learning algorithms presented in Tensorpack and Baselines. In our work we used Tensorpack.
The reinforcement learning agent learns only from visual input, and has access to only the same information given to human players. From a single image the RL agent can learn about the current positions of game objects, but by combining the current image with a few that preceded it, the deep neural network is able to learn not only positions, but also the game’s physical characteristics, such as speed at which objects are moving.
The results of the parallelization experiment conducted by deepesense.ai were impressive – the algorithm required only 20 minutes to master Atari video games, a vast improvement over the approximately one week required in the original experiments done by DeepMind. We provided the code and technical details on arXiv, GitHub and in a blog post, so that others can easily recreate the results. Similar experiments optimizing the training time of Atari games have been conducted by Adam Stooke and Pieter Abbeel from UC Berkeley among others, including OpenAI and Uber.
Replacing the silicon spine
To make the learning process more effective, we used an innovative multi-node infrastructure based on Xeon processors provided by Intel.
The experiment proves that effective machine learning is possible on various architectures, including more common CPUs. The freedom to choose the infrastructure is crucial in seeking ways to further optimize the metrics chosen. Sometimes the time of training is sometimes the decisive factor, at others it is the price of computing power that is the most critical factor. Instead of insisting that all machine learning be done using a particular type of hardware, in practicea diversified architecture may prove more efficient. As machine learning is computing-power-hungry, the wise use of resources may save both money and time.
Biases of mortality revealed by reinforcement learning
Reinforcement learning is much more than just an academic game. By enabling a computer to learn “by itself” with no hints and suggestions,the machine can act innovatively and overcome universal, human biases.
A good example is playing chess. Reinforcement learning agents tend to move in a non-orthodox way that is rarely seen among human players. Sacrificing a bishop only to open the opponent’s position is one of the best examples of superhuman tactics.
So why Atari games?
A typical Atari game provides an environment consisting of a single screen with a limited context and a relatively simple goal to achieve. However, the number of variables which AI must consider is comparable to other visual training environments. Achieving superhuman performance in Atari games is a good indicator that an algorithm will perform well in other tasks. A robotic “game” may mean delivering a human to a destination point without incident or accident or reducing power usage in an intelligent building without any interruption to the business being conducted inside. The huge potential of reinforcement learning is seen in robotics, an area deepsense.ai is continuously developing. Our “Hierarchical Reinforcement Learning with Parameters” paper was presented during the Conference on Robot Learning in 2017.
A robotic arm can be effectively programmed to perform repetitive tasks like putting in screws on an assembly line. The task is always done in the same conditions, with no variables or unexpected events. But when empowered with reinforcement learning and computer vision, the arm will be able to find a bottle of milk in a refrigerator, a particular book on a bookshelf or a plate in a dryer. The possibilities are practically endless. An interesting demonstration of reinforcement learning in robotics may be seen in the video below, which was taken during an experiment conducted by Chelsea Finn, Sergey Levine and Pieter Abbeel from Cal-Berkeley.
Coding every possible position of milk in every possible fridge would be a Herculean-and unnecessary-undertaking. A better approach is to provide the machine with many visual examples from which it learns features of a bottle of milk and then learns through trial and error how to grasp the bottle. Powered by machine learning, the machine would become a semi-autonomous assistant for elderly or injured people. It would be able to work in different lighting conditions or deal with messy fridges.
Warsaw University professors and deepsense.ai contributors Piotr Miłoś, Błażej Osiński and Henryk Michalewski recently conducted a project dubbed “Learning to Run”. They focused on building software for modern, sophisticated leg prostheses that automatically adjust to the wearer’s walking style. Their model can be easily applied in highly flexible environments involving many rapidly changing variables, like financial markets, urban traffic management or any real-time challenge requiring rapid decision-making.Given the rapid development of reinforcement learning methods, we can be sure that 2018 will bring the next spectacular success in this area.





